ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL は、ColdFusion のrapid development tools を使ってSpark への接続をシームレスに統合します。この記事では、ColdFusion でSpark に連携しSpark テーブルをクエリする方法を説明します。
下記の手順に従ってSpark データソースを作成し、ColdFusion アプリケーションへの連携を可能にします。
ドライバーのJAR および.lic ファイルを、インストールディレクトリから C:\ColdFusion10\cfusion\wwwroot\WEB-INF\lib にコピーします。
ドライバーのJAR およびlicense はインストールディレクトリの[lib]サブフォルダに配置されています。
ドライバーをデータソースとして追加:
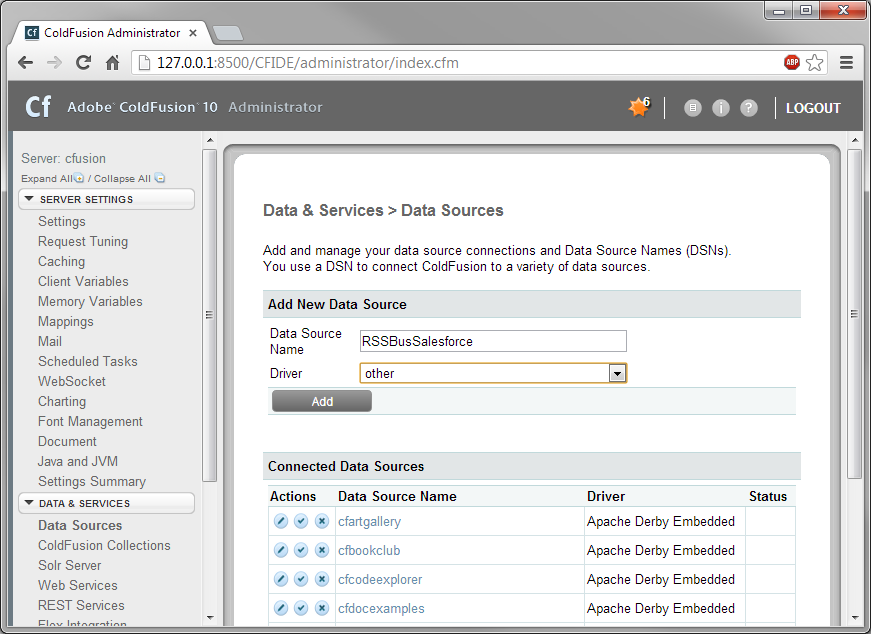
ColdFusion Administrator インターフェースで[Data & Services]ノードを展開し、[Data Sources]>[Add New Data Source]をクリックします。ダイアログが表示されたら、以下のプロパティを入力します。
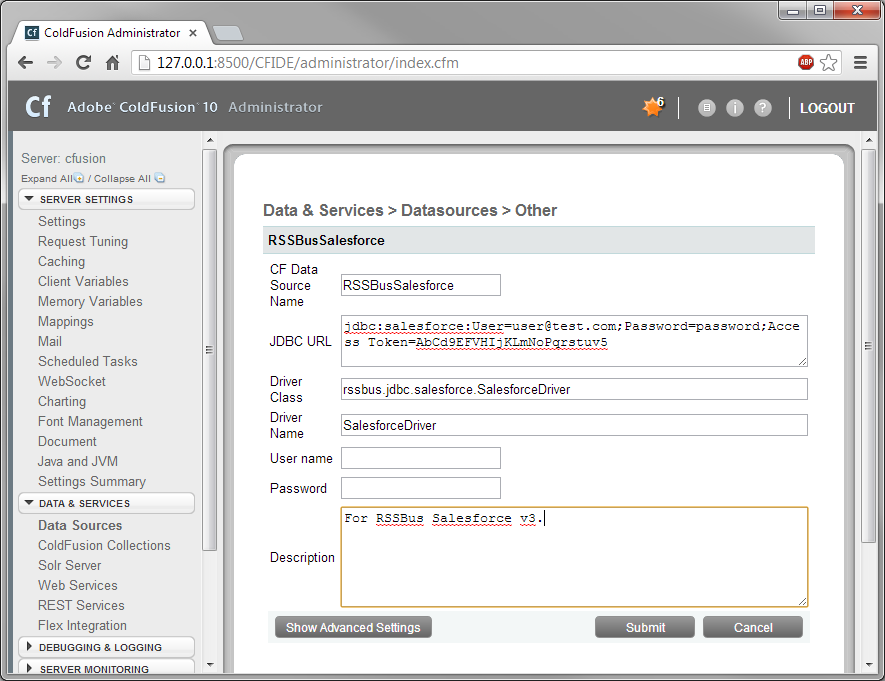
JDBC Driver のプロパティ設定:
JDBC URL:JDBC URL に接続プロパティを入力。JDBC のURL は以下で始まり jdbc:sparksql: 次に、セミコロン区切りでname=value ペアの接続プロパティを入力します。以下は一般的なJDBC URL です:
jdbc:sparksql:Server=127.0.0.1;
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
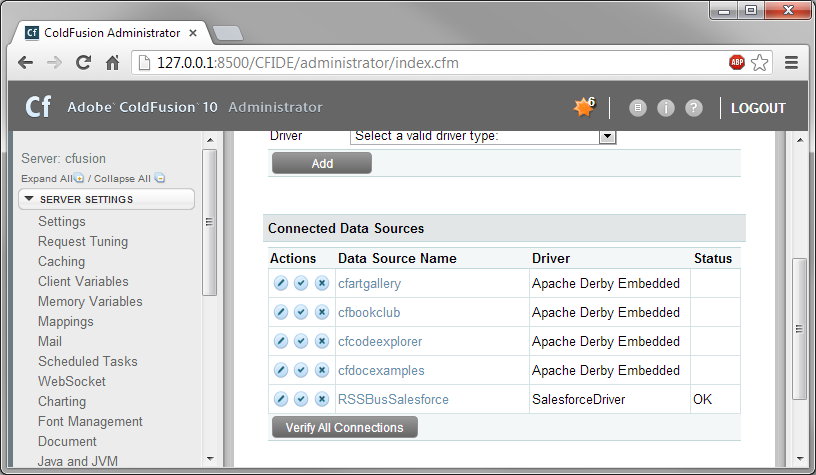
[Actions] カラムのCData Spark データソースを有効にして、接続をテストできます。ステータスがOK になったら、Spark データソースを使うことができます。
下記の手順に従って、Spark の基準に合ったレコードをクエリし、結果をHTML テーブルに出力する簡単なアプリケーションを作成します。
新規ColdFusion markup ファイルでクエリを定義:C:\ColdFusion10\cfusion\wwwroot directory for ColdFusion の.cfm ファイルに次のコードを入力:
<cfquery name="SparkSQLQuery" dataSource="CDataSparkSQL">
SELECT * FROM Customers
</cfquery>
Note:CData JDBC Drivers は、cfqueryparam エレメントを使ってパラメータ化されたクエリもサポートします。例:
<cfquery name="SparkSQLQuery" dataSource="CDataSparkSQL">
SELECT * FROM Customers WHERE Country = <cfqueryparam>US</cfqueryparam>
</cfquery>
CFTable を使ってHTML にテーブルを出力:
<cftable
query = "SparkSQLQuery"
border = "1"
colHeaders
colSpacing = "2"
headerLines = "2"
HTMLTable
maxRows = "500"
startRow = "1"/>
<cfcol header="<b>City</b>" align="Left" width=4 text="#City#"></cfcol>
<cfcol header="<b>Balance</b>" align="Left" width=7 text="#Balance#"></cfcol>
</cftable>
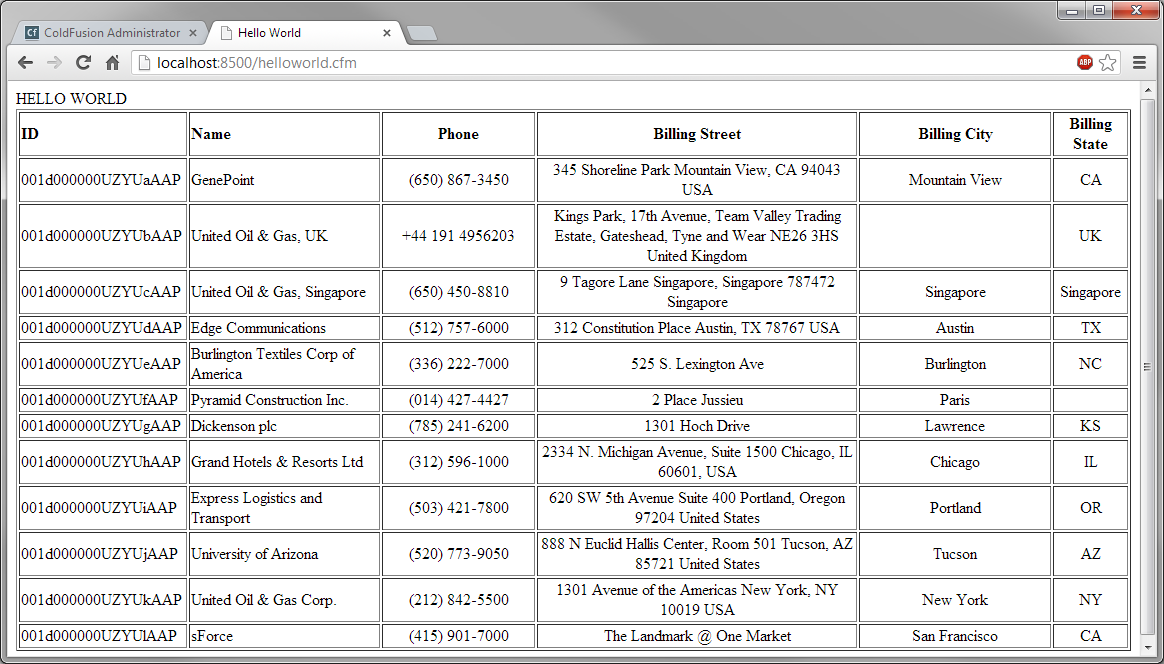
コードを実行してグリッドを表示します。
HTML 部分を含む以下のフルコードが利用できます。
<html>
<head><title>Hello World</title></head>
<body>
<cfoutput>#ucase("hello world")#</cfoutput>
<cfquery name="SparkSQLQuery" dataSource="CDataSparkSQL">
SELECT * FROM Customers
</cfquery>
<cftable
query = "SparkSQLQuery"
border = "1"
colHeaders
colSpacing = "2"
headerLines = "2"
HTMLTable
maxRows = "500"
startRow = "1">
<cfcol header="<b>City</b>" align="Left" width=4 text="#City#"></cfcol>
<cfcol header="<b>Balance</b>" align="Left" width=7 text="#Balance#"></cfcol>
</cftable>
</body>
</html>