ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
JRuby はRuby プログラミング言語の高性能で安定した、完全にスレッド化されたJava 実装です。CData JDBC Driver for SparkSQL を使用すると、JRuby からリアルタイムSpark へのデータ連携を簡単に実装できます。ここでは、Spark に接続し、クエリを実行して結果を表示する簡単なJRuby アプリを作成する方法を説明します。
アプリを作成する前に、JDBC Driver のJAR ファイルのインストール場所をメモします。 (通常はC:\Program Files\CDatat\CData JDBC Driver for SparkSQL\libにあります。)
JRuby は、JDBC をネイティブにサポートしているため、簡単にSpark に接続してSQL クエリを実行できます。java.sql.DriverManager クラスのgetConnection 関数を使用してJDBC 接続を初期化します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
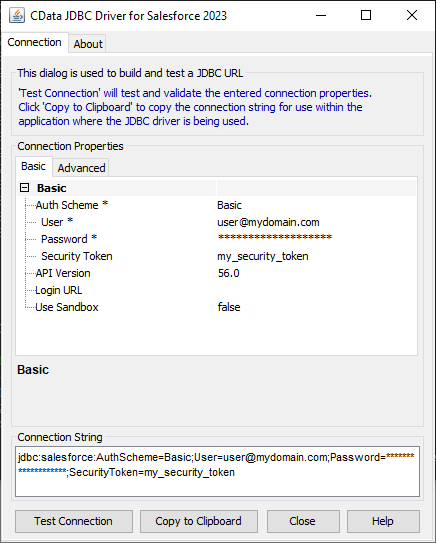
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下はSpark の一般的なJDBC 接続文字列です。
jdbc:sparksql:Server=127.0.0.1;
新しいRuby ファイル(例: SparkSQLSelect.rb) を作成してテキストエディタで開き、次のコードをファイルにコピーします。
require 'java'
require 'rubygems'
require 'C:/Program Files/CData/CData JDBC Driver for SparkSQL 2018/lib/cdata.jdbc.sparksql.jar'
url = "jdbc:sparksql:Server=127.0.0.1;"
conn = java.sql.DriverManager.getConnection(url)
stmt = conn.createStatement
rs = stmt.executeQuery("SELECT City, Balance FROM Customers")
while (rs.next) do
puts rs.getString(1) + ' ' + rs.getString(2)
end
ファイルが完成したら、コマンドラインからファイルを実行するだけでJRuby でSpark を表示できるようになります。
jruby -S SparkSQLSelect.rb
SQL-92 クエリをSpark に書き込むと、Spark を独自のJRuby アプリケーションに素早く簡単に組み込むことができます。今すぐ無料トライアルをダウンロードしましょう。