Spark データにSQL を使ってAnypoint からデータ連携
Spark のJSON エンドポイントを作成するために、HTTP やSQL をCData Mule Connector とともに使用するシンプルなMule アプリケーションを作成します。
杉本和也
リードエンジニア
最終更新日:2023-10-03
こんにちは!リードエンジニアの杉本です。
CData Mule Connector for SparkSQL は、Spark をMule アプリケーションから標準SQL でのread 、write。update、およびdelete 機能を可能にします。コネクタを使うことで、Mule アプリケーションでSpark のバックアップ、変換、レポートおよび分析を簡単に行えます。
この記事では、Mule プロジェクト内のCData Mule Connector for SparkSQL を使用してSpark 用のWeb インターフェースを作成する方法を説明します。作成されたアプリケーションを使用すると、HTTP リクエストを使用してSpark をリクエストし、結果をJSON として返すことができます。以下のアウトラインと同じ手順を、CData Mule Connector で使用し、250+ の使用可能なWeb インターフェースを作成できます。
- Anypoint Studio で新しいMule プロジェクトを作成します。
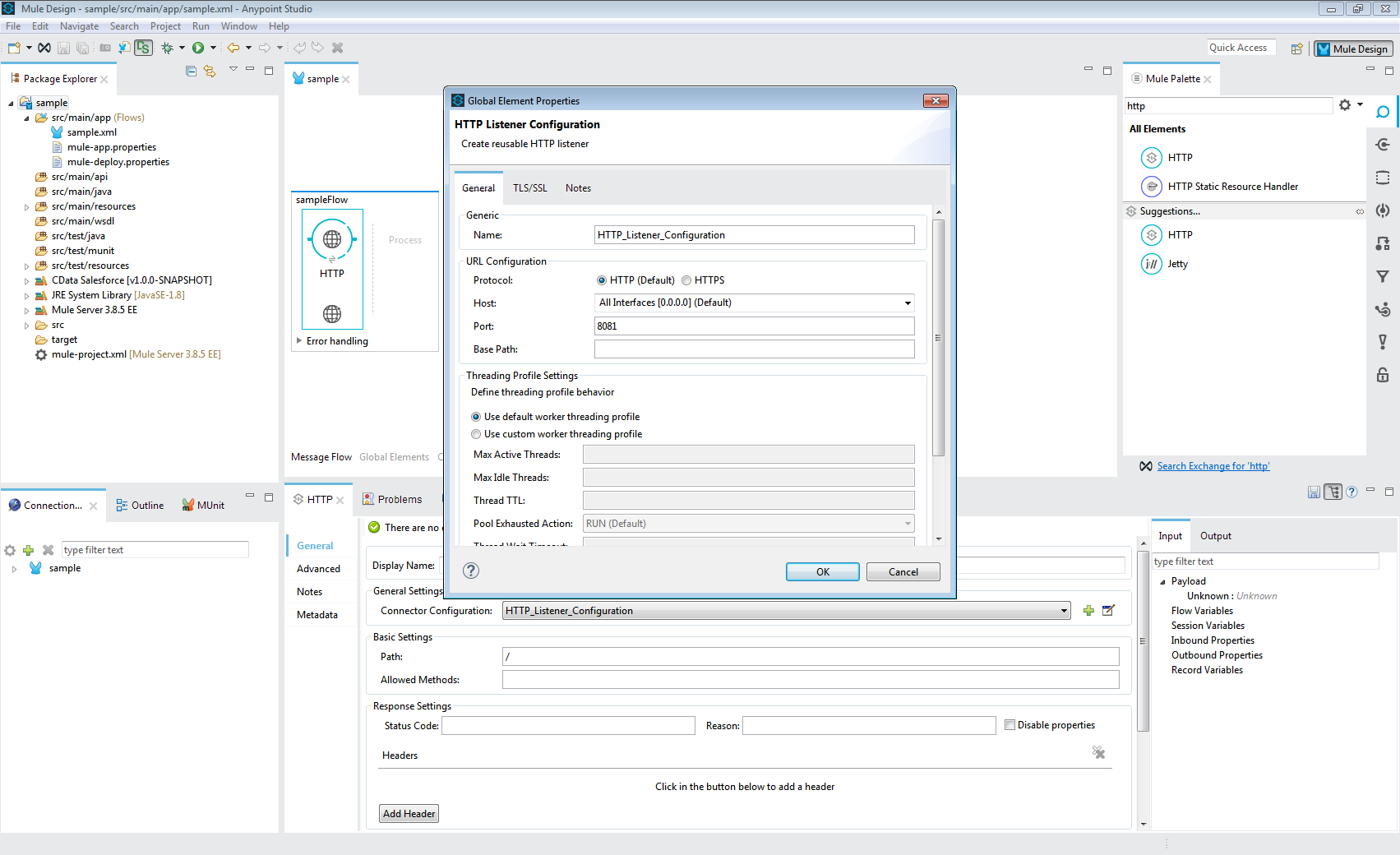
- [Message Flow]にHTTP Connector を追加します。
- HTTP Connector のアドレスを設定します。
![Add and Configure the HTTP Connector]()
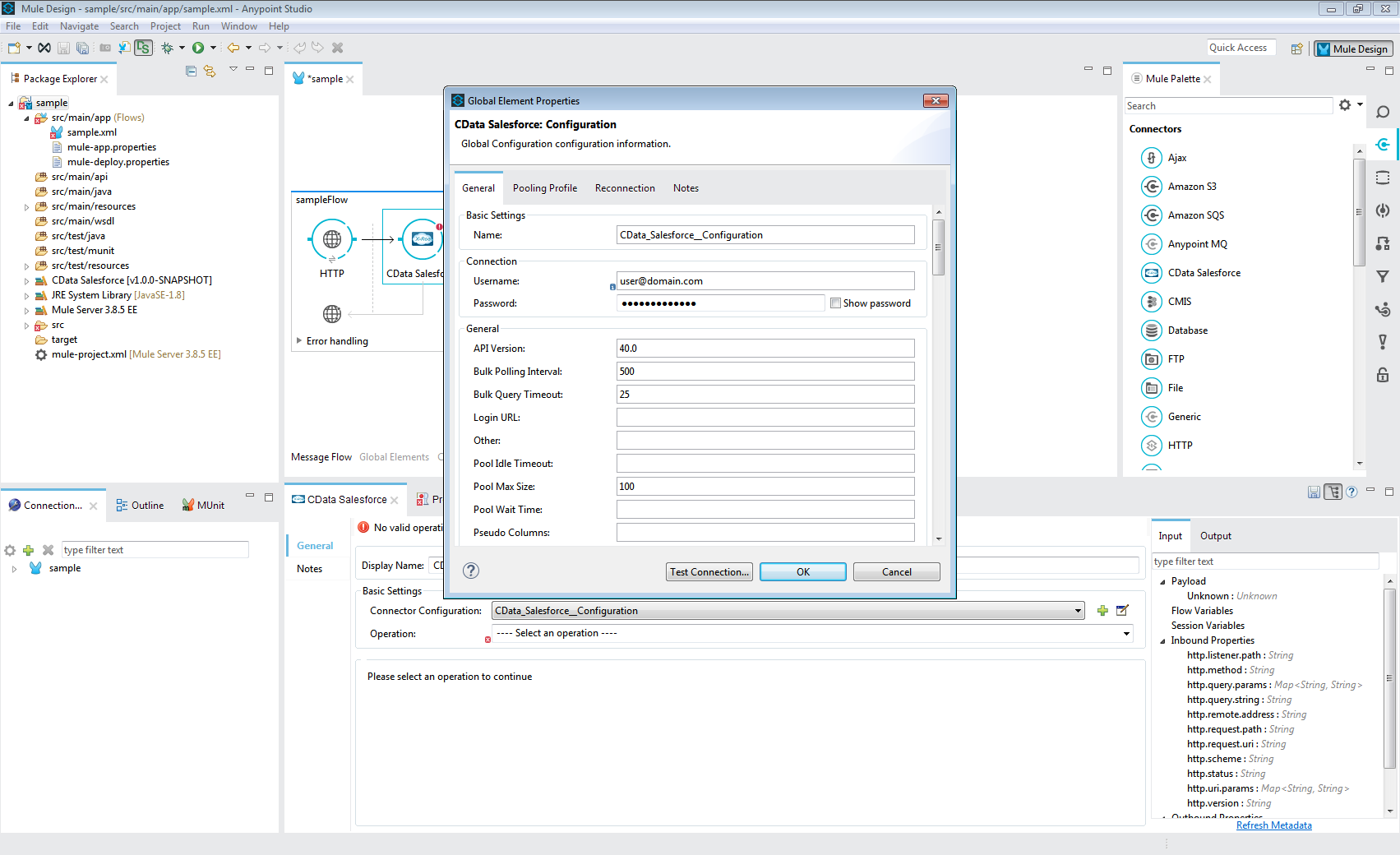
- CData Spark Connector をHTTP Connector の後に、同じフロー内に追加します。
- 新しい接続を作成または既存の接続を編集し、Spark に接続するようにプロパティを構成します。(以下を参照)接続が構成されたら、[Test Connection]をクリックしてSpark への接続を確認します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![Add the CData Spark Connector and Configure the Connection (Salesforce is Shown)]()
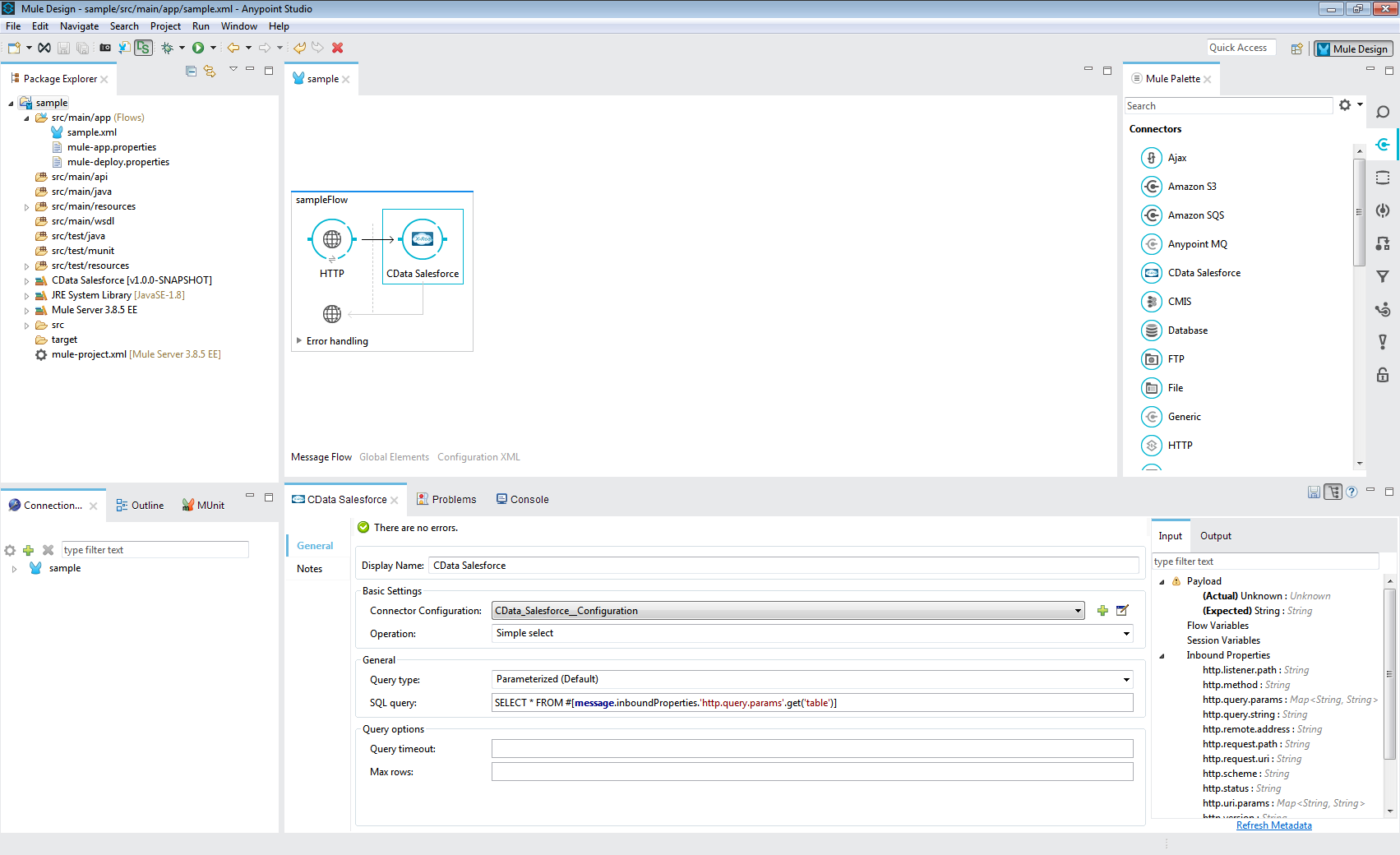
- CData Spark Connector を構成します。
- [Operation]を[Select with Streaming]に設定します。
- [Query type]を[Dynamic]に設定します。
- SQL クエリをSELECT * FROM #[message.inboundProperties.'http.query.params'.get('table')] に設定してURL パラメータtable を解析し、SELECT クエリのターゲットとして使用します。他の潜在的なURL パラメータを参照することにより、クエリをさらにカスタマイズできます。
![Configure the CData Spark Mule Connector (Salesforce is Shown)]()
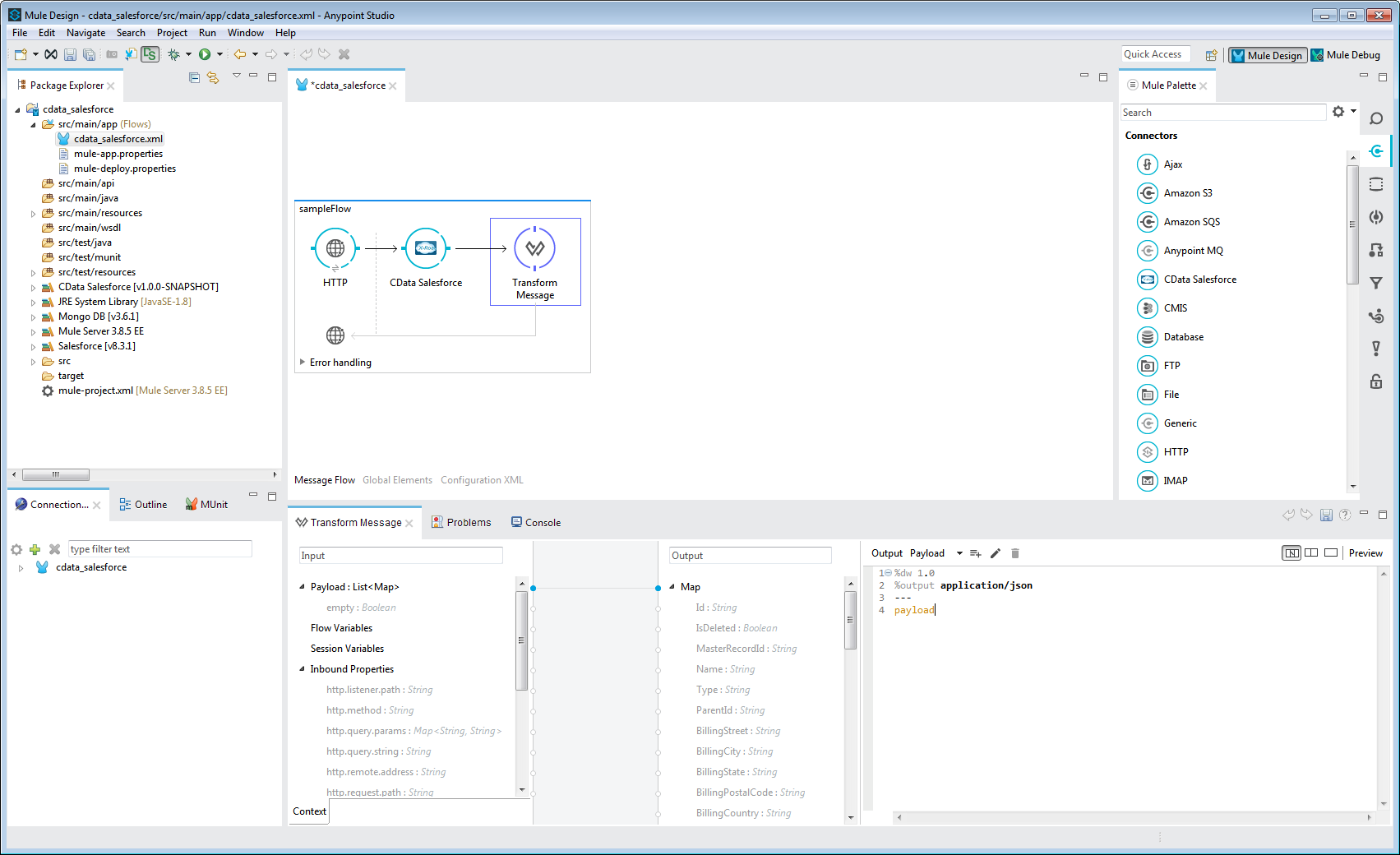
- [Transform Message Component]をフローに追加します。
- 入力から出力のMap にPayload をマッピングします。
- Payload をJSON に変換するには、Output スクリプトを以下のように設定します。
%dw 1.0
%output application/json
---
payload
![Add the Transform Message Component to the Flow]()
- Spark を表示するには、HTTP Connector 用に構成したアドレス(デフォルトではlocalhost:8081) に移動し、table のURL parameter はhttp://localhost:8081?table=Customers としてテーブル名を渡します。
Customers データは、Web ブラウザおよびJSON エンドポイントを使用できるその他のツールでJSON として使用できます。
カスタムアプリでSpark をJSON データとして操作するためのシンプルなWeb インターフェースと、様々なBI、レポート、およびETL ツールが完成しました。Mule Connector for SparkSQL の30日間無料トライアルをダウンロードして今すぐMule Applications でCData の違いを確認してみてください。