ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!テクニカルディレクターの桑島です。
CData ODBC Driver for SparkSQL は、ODBC 経由でリアルタイムSpark データ に標準SQL での利用を可能にします。
ここでは、汎用ODBC データプロバイダーとしてSpark に接続し、データアナリティクスツールのExploratory (https://exploratory.io/) からSpark データを連携利用する手順を説明します。
Exploratory は、多くのRDB やRedshift、BigQuery などのクラウドデータストアに対応していますが、SaaS データを分析したい場合にはCData ODBC ドライバを使うことで、API コーディング不要でデータを活用できます。今回はSpark を例に説明します。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
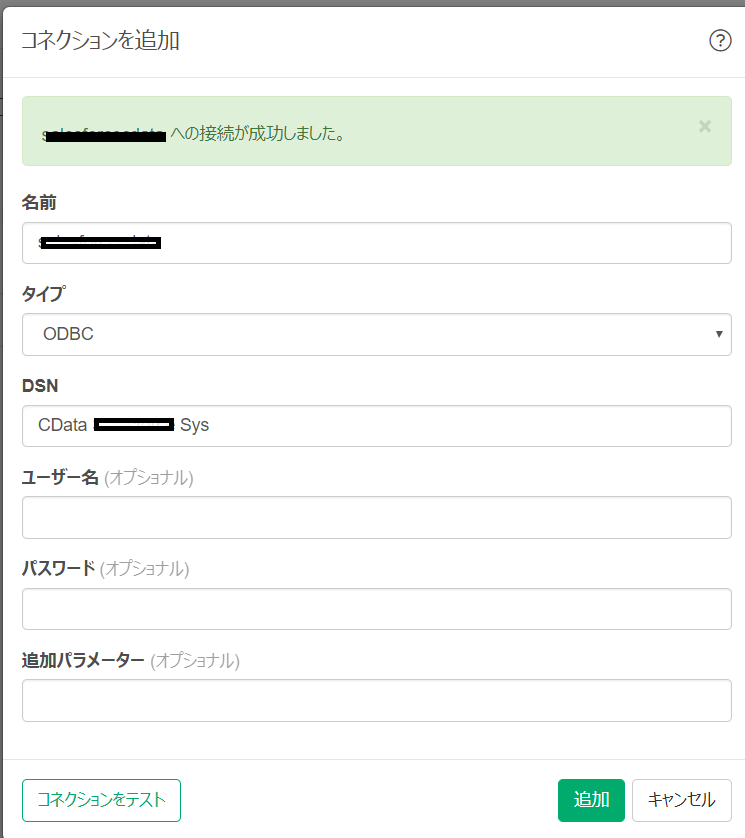
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Exploratory 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
次にマシンにSpark データ に接続するODBC DSN を設定します。Exploratory からはそのODBC DSN を参照する形になります。ODBC DSN 設定の詳細については、ドキュメントを参照してください。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
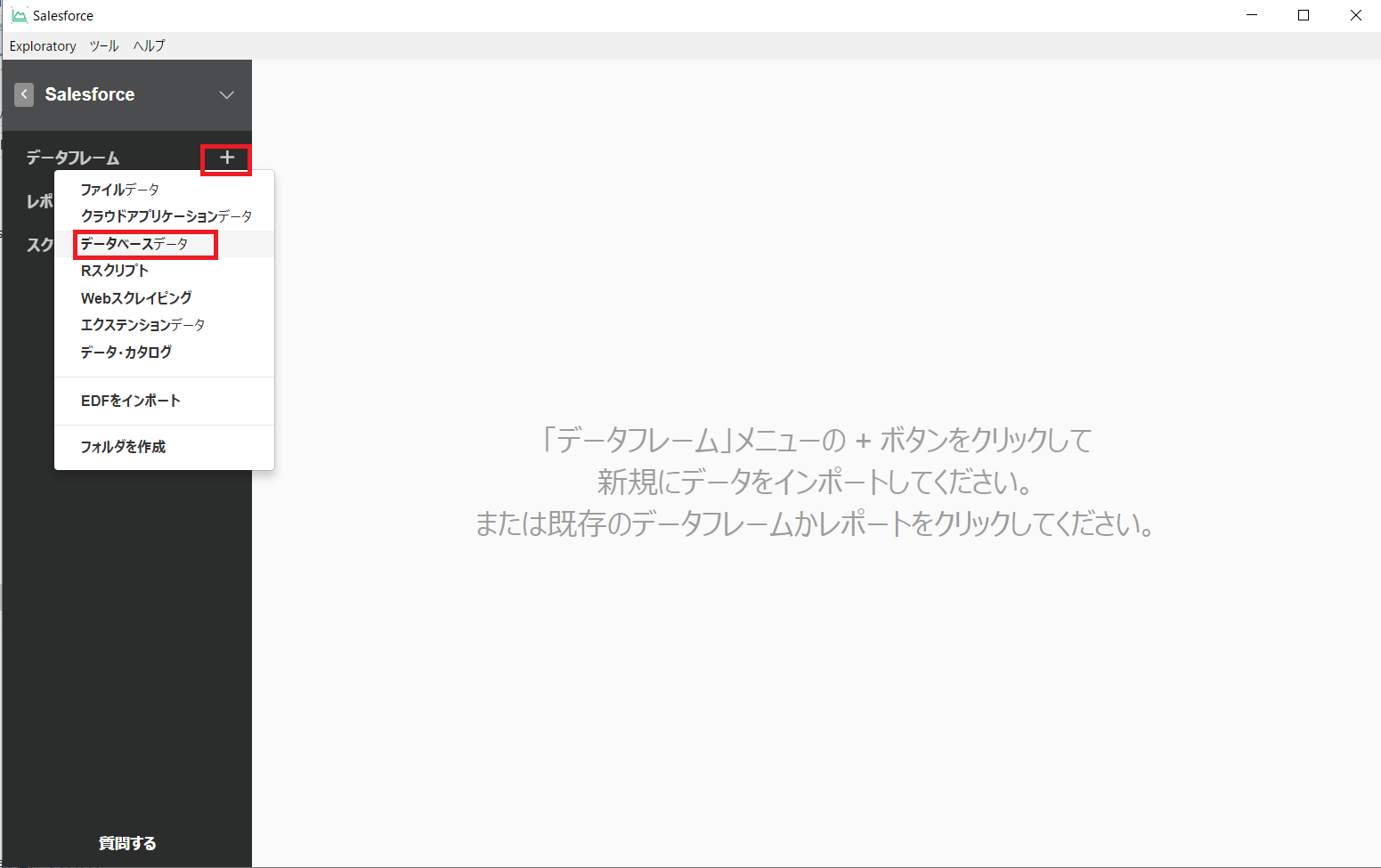
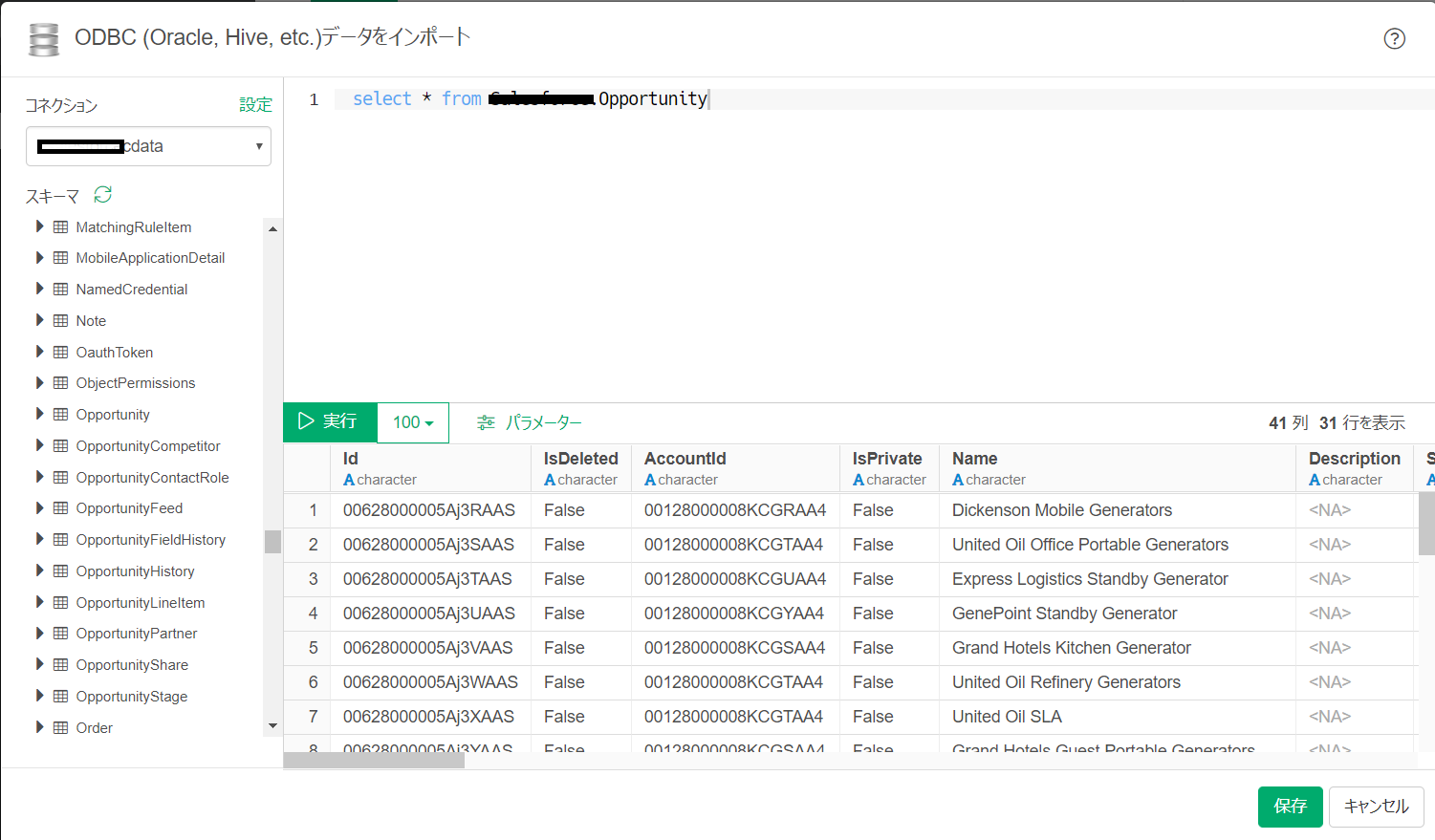
さあ、Exploratory からSpark データを扱ってみましょう。
データフレームになったデータは通常のRDB データソースと同じようにExploratory で利用可能です。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。