ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Power Automate Desktop は、さまざまなファイルやサービスの処理を自動化できるMicrosoft のRPA サービスです。Power Automate Desktop をCData ODBC ドライバと組み合わせることで、ネイティブではサポートされていない多くのSaaS / クラウドDB のデータを扱えます。この記事ではCData ODBC Driver for SparkSQL を使って、Power Automate Desktop からSpark データを使えるようにします。サンプルとしてSpark データから特定のテーブルを選んで自動でCSV ファイルを生成します。
CData ODBC ドライバは、以下のような特徴を持った製品です。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Power Automate 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
ODBC ドライバーのインストール完了時にODBC DSN 設定画面が立ち上がります。「Microsoft ODBC データソースアドミニストレーター」を開いて設定を行うことも可能です。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
Power Automate Desktop では、設定したSpark のDSN 名のほかに、使用するテーブル名が必要です。テーブル名は、ODBC DSN 構成画面の「テーブル」タブで確認可能です。使うテーブルもしくはビューの名前をコピーして控えておくとよいでしょう。
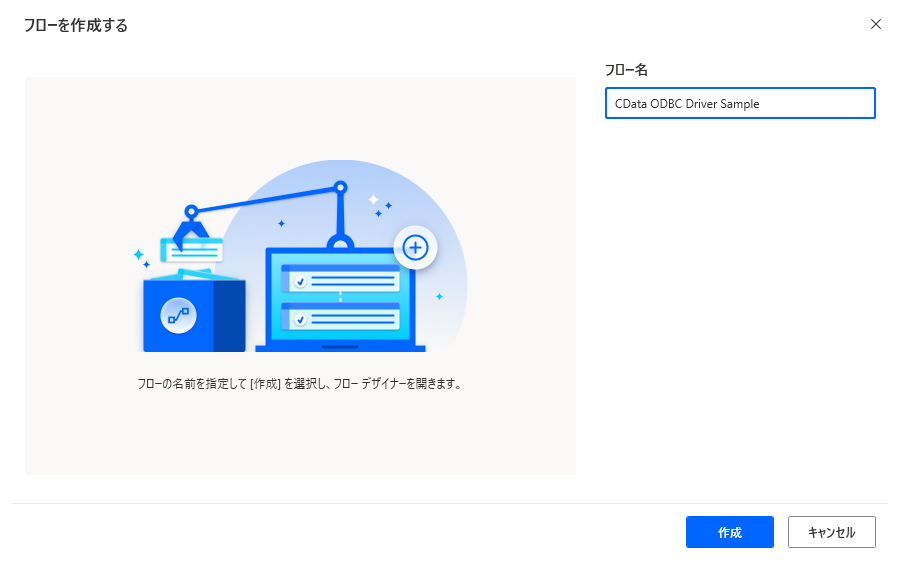
Power Automate Desktop でフローを作成していきます。Power Automate Desktop を立ち上げて、「新しいフロー」をクリックします。任意のフロー名を入力して、新規のフローを作成します。
以下の順番でフローを作成していきます。
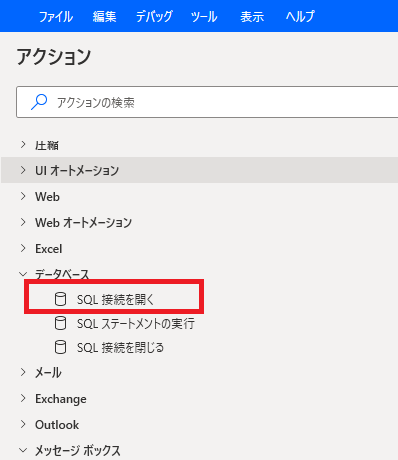
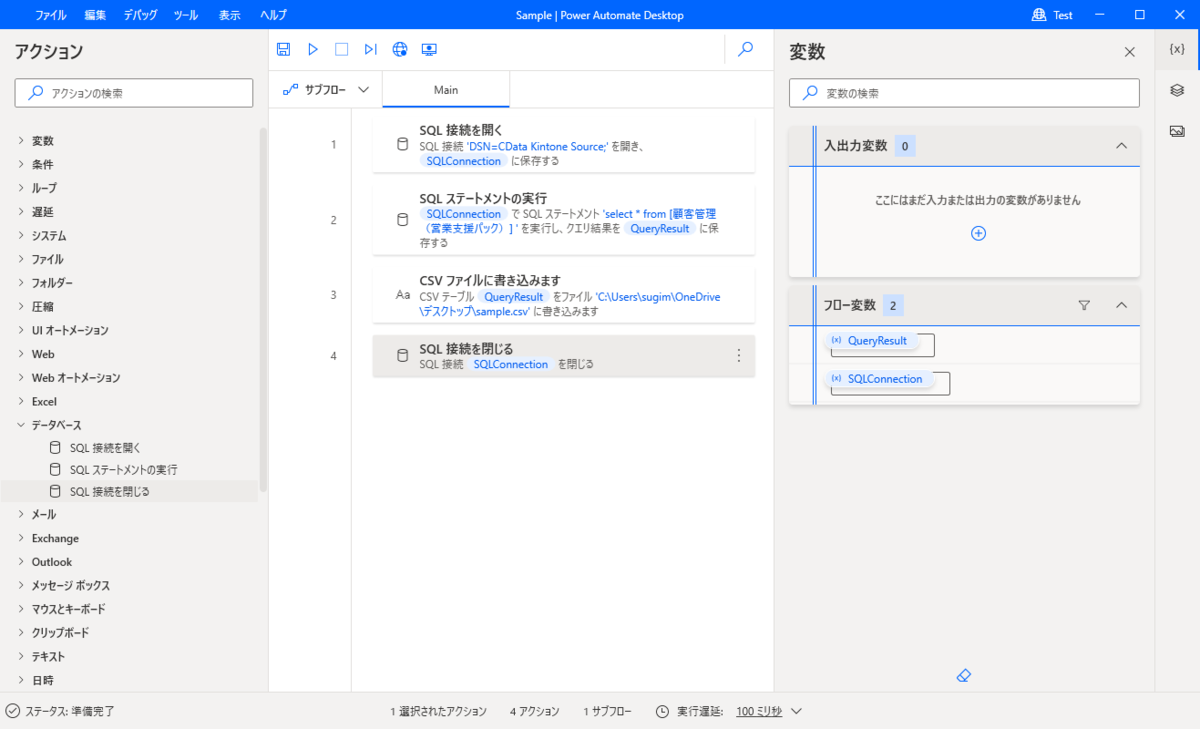
Power Automate Desktop から、CData ODBC ドライバでSpark に接続する場合にはデータベース接続のアクションを使います。まず最初に「SQL 接続を開く」アクションを配置して、先ほど設定したODBC DSN への接続設定を行います。
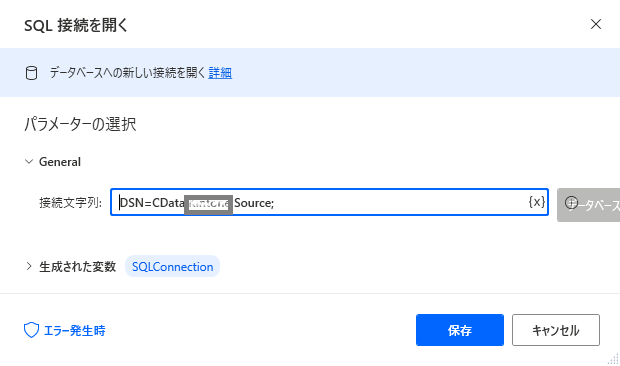
「SQL 接続を開く」の設定画面で、Spark のDSN を「DSN= CData SparkSQL Source;」の形で指定します。
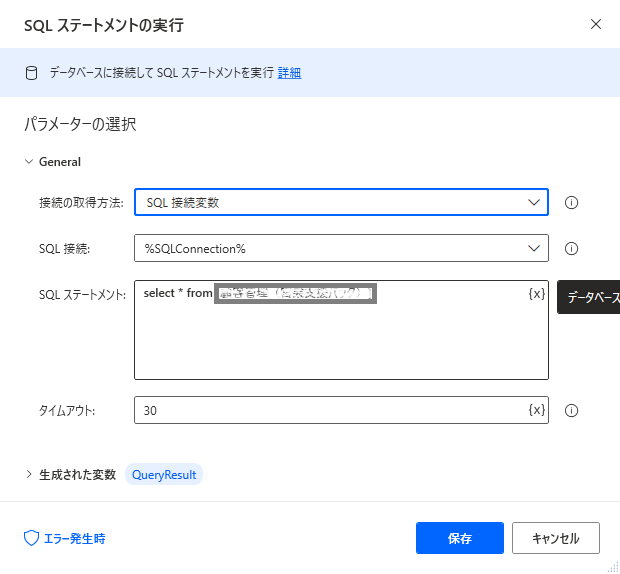
続いてデータを取得するクエリを実行するために「SQL ステートメントの実行」を配置します。設定画面に以下を設定します。
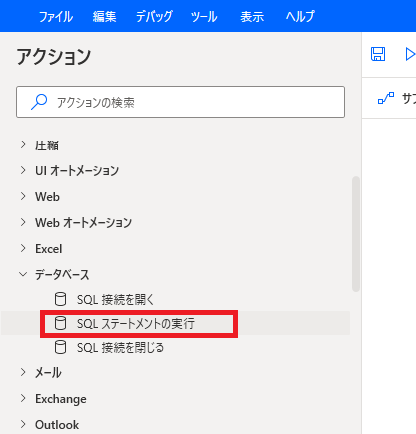
これでSQL でSpark にクエリをすることができます。豊富なSQL の設定が可能です。
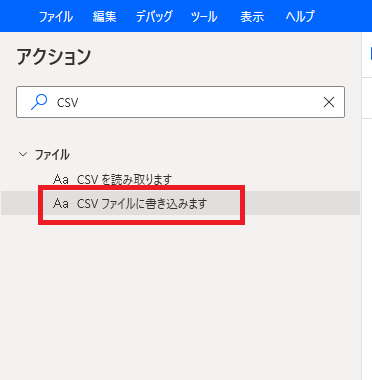
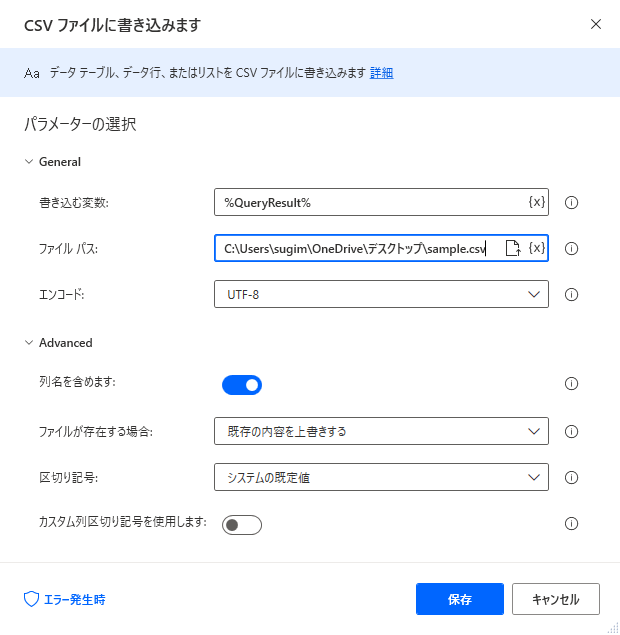
この例では、取得したSpark データをCSV ファイルとして保存します。では、CSVファイルの生成アクションを設定します。アクションから「CSV ファイルに書き込みます」を配置します。
取得したアプリのデータが格納されている「%QueryResult%」を書き込む変数に指定します。生成先のファイルパスを指定します。列名を含めたい場合には「Advanced」の「列名を含めます」にチェックを入れます。
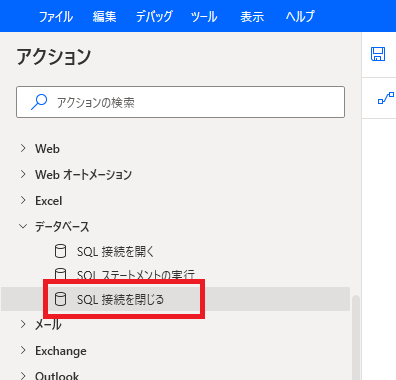
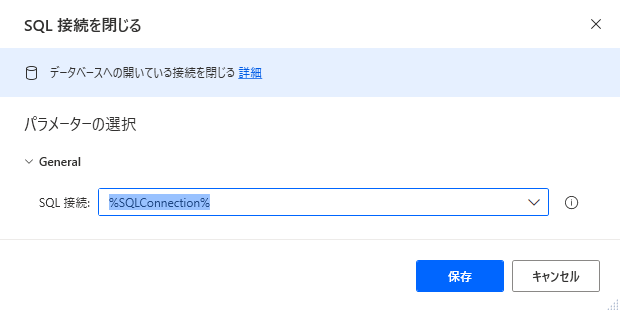
最後に、接続したODBC 接続をクローズします。「SQL接続を閉じる」をフローに配置します。
閉じるコネクションを指定して保存します。
これで、Spark データをCSV に保存するPower Automate フローが完成しました。実行ボタンを押してオートメーションを実行しましょう。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをPower Automate Desktop からコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
日本のユーザー向けにCData ODBC ドライバは、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。