ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData ODBC Drivers は、ODBC ドライバーをサポートするあらゆる環境から利用可能です。本記事では、PyCharm からのCData ODBC Driver for SparkSQL の利用を説明します。CData ODBC Deriver をデータソースとして設定する方法、データソースをクエリして結果を表示するためのPyCharm の簡単なコードを含みます。
はじめに、このチュートリアルではCData ODBC Driver for SparkSQL とPyCharm が、既にインストールされていることを前提としています。
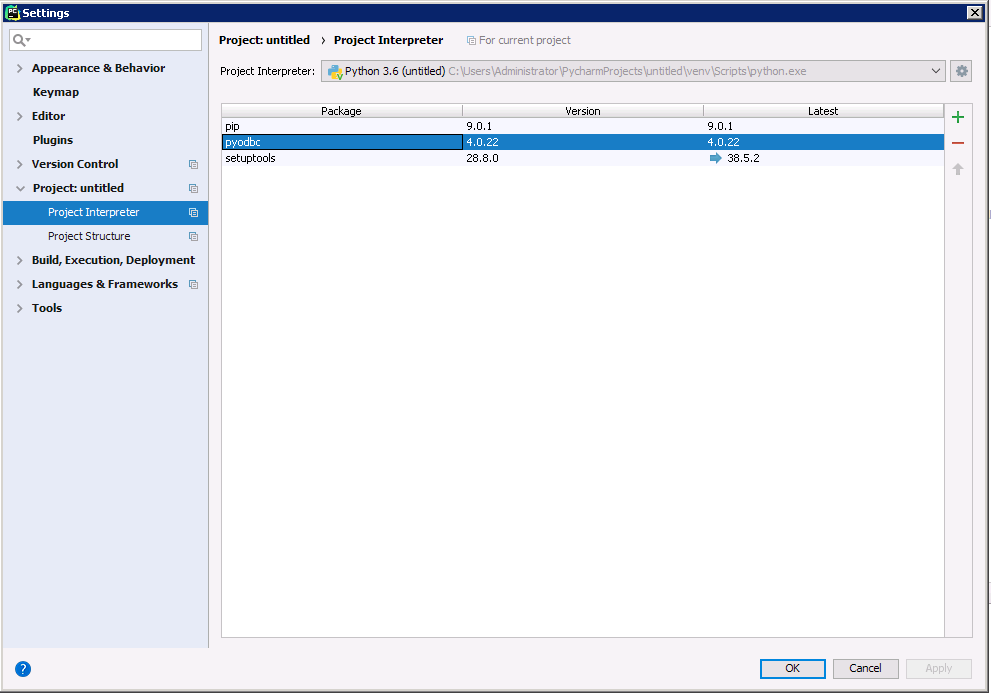
以下のステップに従って、pyodbc モジュールをプロジェクトに追加します。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.PyCharm 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
これで、ODBC 接続文字列またはDSN で接続できます。お客様のOS でDSN を作成するためのガイドについては、CData ドライバードキュメントの[はじめに]セクションを参照してください。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
以下はDSN の構文です。
[CData SparkSQL Source]
Driver = CData ODBC Driver for SparkSQL
Description = My Description
Server = 127.0.0.1
Cursor をインスタンス化し、Cursor クラスのexecute メソッドを使用してSQL ステートメントを実行します。
import pyodbc
cnxn = pyodbc.connect('DRIVER={CData ODBC Driver for SparkSQL};Server = 127.0.0.1;')
cursor = cnxn.cursor()
cursor.execute("SELECT City, Balance FROM Customers WHERE Country = 'US'")
rows = cursor.fetchall()
for row in rows:
print(row.City, row.Balance)
CData ODBC Driver を使用してPyCharm でSpark に接続すると、Spark にアクセスできるPython アプリケーションを標準データベースのように構築できるようになります。このチュートリアルに関する質問、コメント、フィードバックがある場合には、[email protected] までご連絡ください。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。