製品をチェック
Apache Spark SSIS Component の30日間無償トライアルをダウンロード
30日間の無償トライアルへ
製品の詳細
 Apache Spark SSIS Components
相談したい
Apache Spark SSIS Components
相談したい
パワフルなSSIS Source & amp; SQL Server をSSIS Workflow 経由でApache Spark に簡単に接続することを実現するdestination コンポーネント.
Apache Spark データフローコンポーネントを使ってApache Spark データを同期しましょう。データ同期、ローカルバックアップ、ワークフローの自動化などに最適!
SSIS を使ってSpark データをSQL Server にインポート
CData SSIS Components を使用して簡単にSQL Server へSpark をバックアップします。
古川えりか
コンテンツスペシャリスト
最終更新日:2022-07-10
CData

こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
SQL Server に基幹業務データのバックアップを保管しておくことは、ビジネス上のセーフティネットとなります。また、ユーザーはSQL Server のバックアップデータからレポーティングや分析を簡単に行うことができます。
ここでは、SQL サーバー SSIS ワークフロー内でCData SSIS Tasks for SparkSQL を使用して、Spark データをMicrosoft SQL Server データベースに転送する方法を説明します。
Components の追加
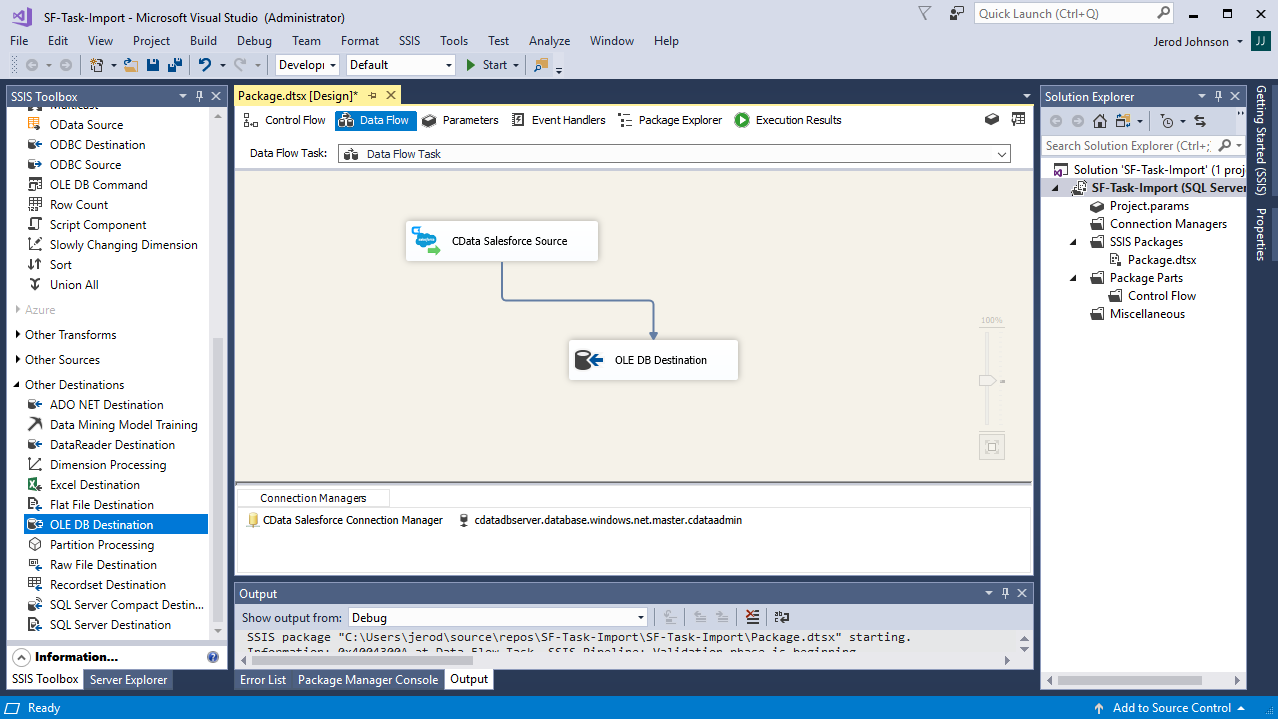
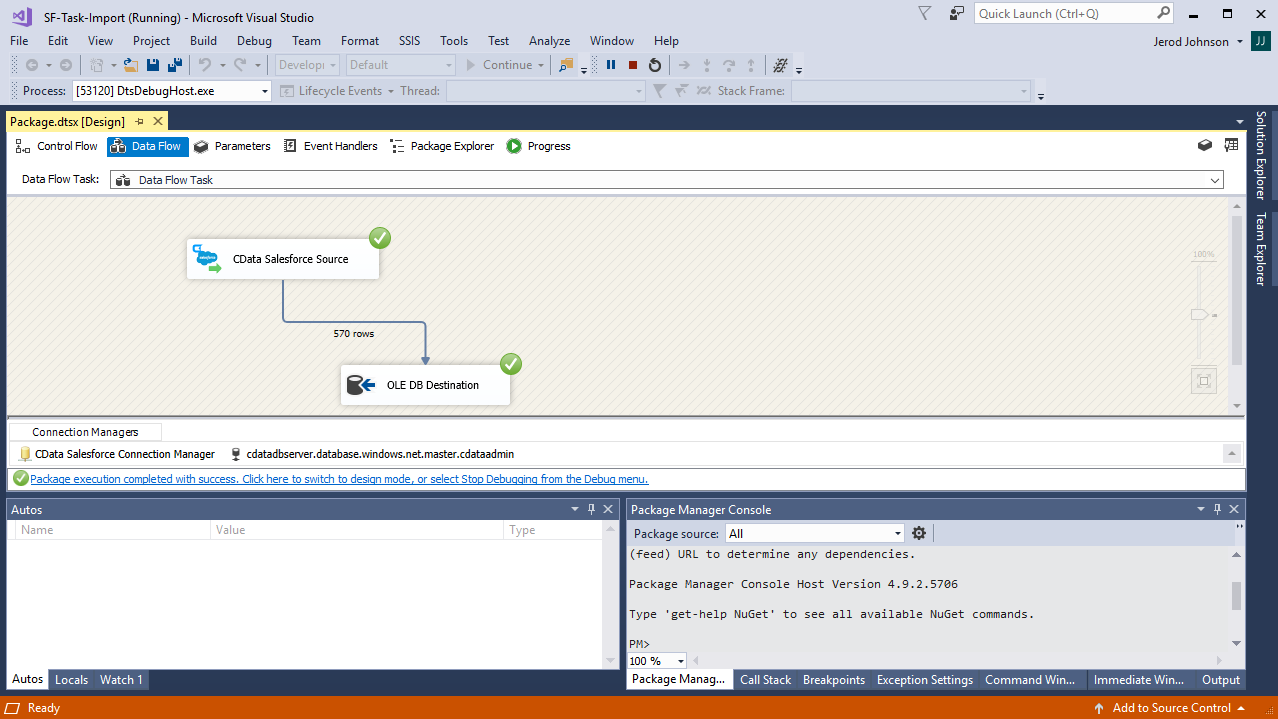
開始するには、新しいSpark ソースとSQL Server ADO.NET 転送先を新しいデータフロータスクに追加します。
![The Data Flow task used in this example.(Salesforce is shown.)]()
新しいコネクションマネジャーを作成
以下のステップに従って、接続マネジャーでSpark 接続プロパティを保存します。
- Connection Manager ウィンドウで、右クリックで[New Connection] を選択します。Add SSIS Connection Manager ダイアログが表示されます。
- [Connection Manager type]メニューでSparkSQL を選択します。CData Spark Connection Manager が表示されます。
- 接続プロパティを構成します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
Spark Source の構成
以下のステップに従って、Spark の抽出に使用するクエリを指定します。
- Spark ソースをダブルクリックしてソースコンポーネントエディタを開きます。
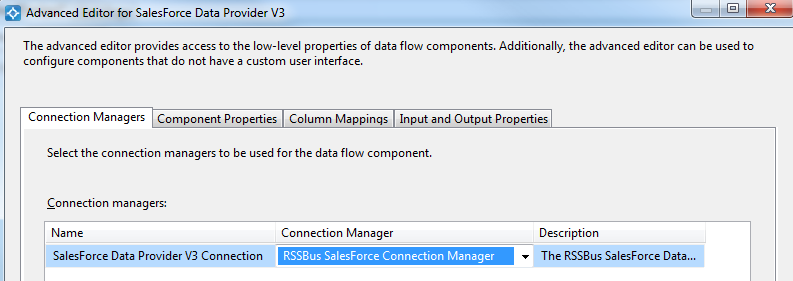
- [Connection Manager]メニューで、以前作成した接続マネジャーを選択します。
![The Connection Manager to be used for the source component.(Salesforce is shown.)]()
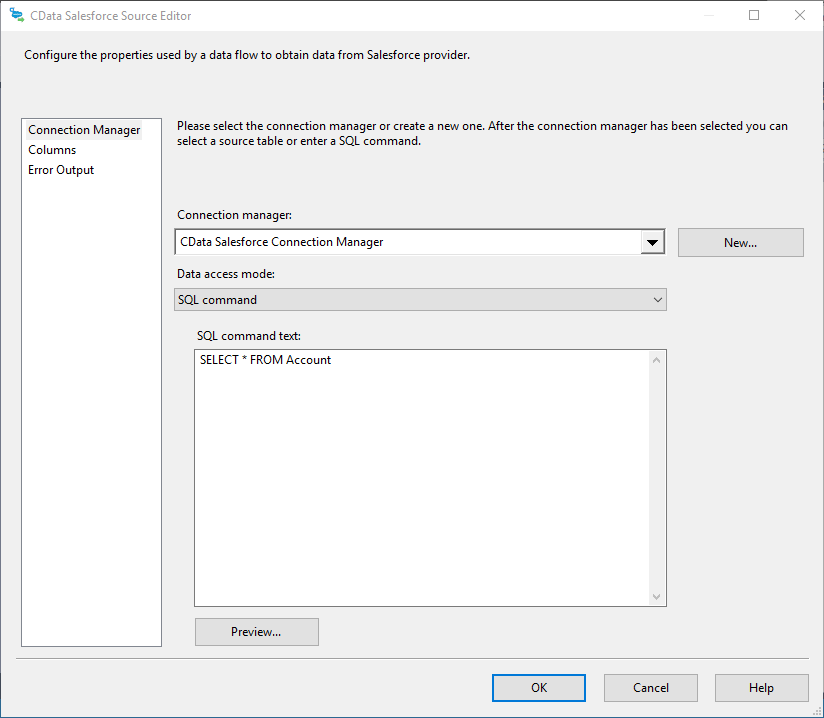
- データの書き出しに使用するクエリを指定します。例:
SELECT City, Balance FROM Customers
![The SQL query to retrieve records.(Salesforce is shown.)]()
- Spark Source コントロールを閉じて、ADO.NET Destination に接続します。
SQL Server Destination を構成する
以下のステップに従って、Spark をロードするSQL サーバーテーブルを指定します。
- ADO.NET Destination を選択して、新しい接続を追加します。接続するサーバーおよびデータベースの情報を入力。
- Data access モードメニューで、[table or view]を選択します。
- [Table Or View]メニューで、設定するテーブルまたはビューを選択します。
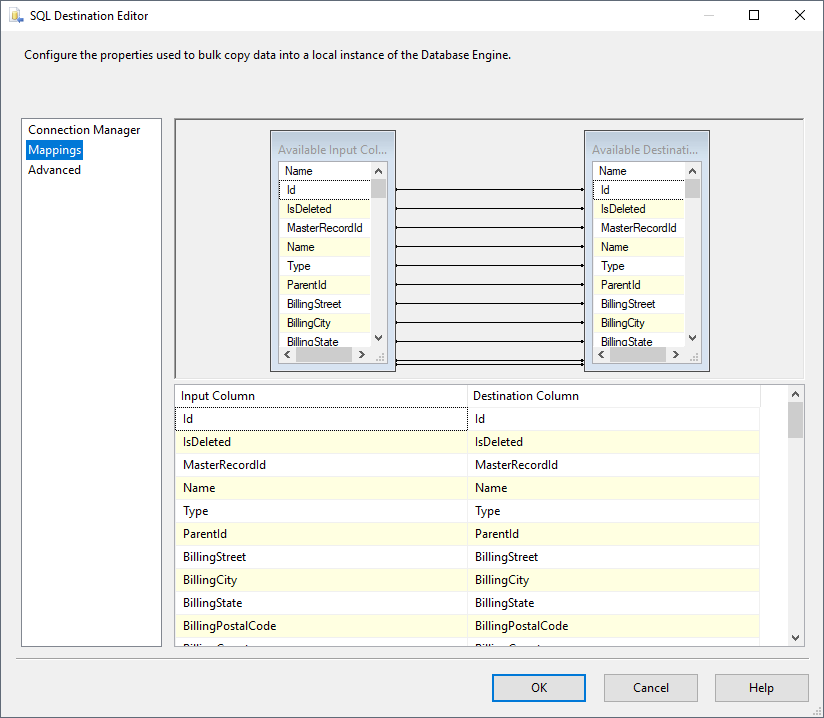
- [Mappings]画面で必要なプロパティを設定します。
![The mappings from the SSIS source component to SQL Server.(Salesforce is shown.)]()
プロジェクトの実行
プロジェクトを実行できるようになりました。SSIS Task の実行が完了すると、データベースにSpark データが入力されます。
![The completed import.(Salesforce is shown.)]()