各製品の資料を入手。
詳細はこちら →



CData Syncを用いたAzure SQL Database -> Amazon Redshift へのデータ統合
はじめに
CData Syncは、クラウドサービスアプリケーション(SaaS)データをRDBやDWHに高速に同期する自動データレプリケーション製品です。本製品は、SaaSデータだけではなく、RDBMSのテーブルデータも同様にデータレプリケーションのパイプラインを作成することができます。本記事では、Microsoft Azure SQL DatabaseのデータをAmazon Redshiftへデータ統合する例をご紹介します。

前提
- CData Sync製品がインストール・および、アクティベーションまで完了していること。手順はこちらのハンズオン用資料のインストール・ライセンスのアクティベーションの章をご覧ください。
- Microsoft Azure SQL Databaseの接続環境があること。
- Amazon Redshiftへの接続環境があること。
手順
Microsoft Azure SQL Databaseへの接続
接続 > 接続の追加 > データソース からSQL Serverを選択します。ここにアイコンがないデータソースは「+ Add More」から追加できます。追加した場合は内部的にサービスが再起動してログイン画面に戻りますのでご注意ください。

SQL Serverの接続設定 > 設定 にて以下の項目をセットしてAzure SQL Databaseへの接続を作成します。
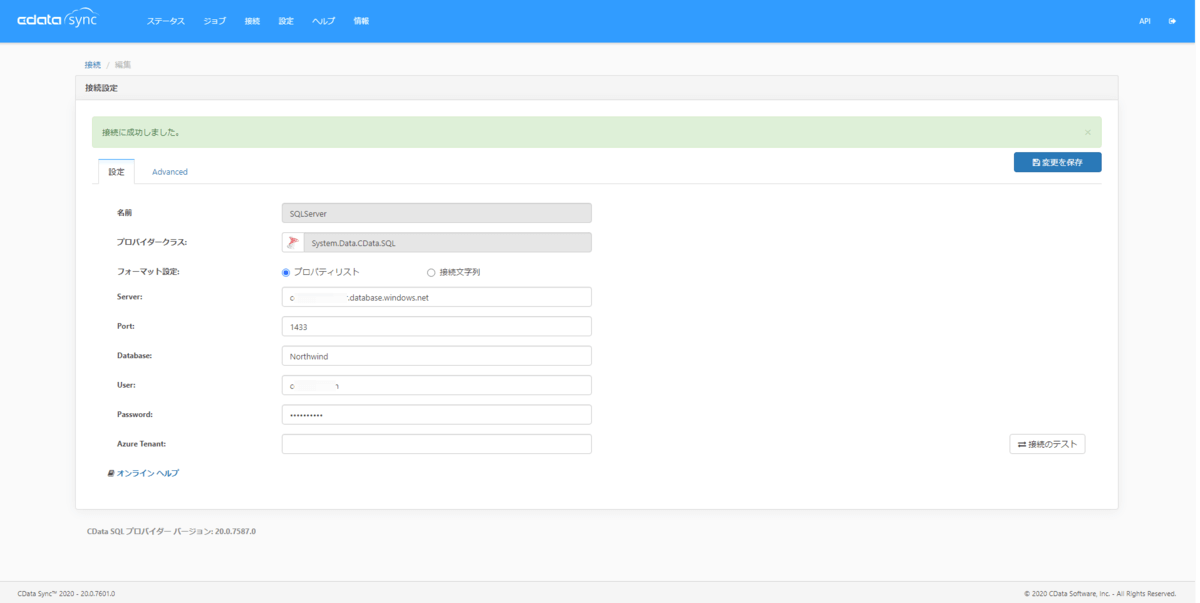
| プロパティ名 | 値 |
|---|---|
| 名前 | 任意(本例ではSQLServer) |
| Server | Azure SQL DatabaseのServer Name |
| Port | Azure SQL Databaseの接続ポート番号 |
| Database | Azure SQL Databaseの接続データベース名(Northwindを使用) |
| User | Azure SQL Databaseの接続ユーザ名 |
| Password | Azure SQL Databaseの接続パスワード |
「接続のテスト」ボタンをクリックして、接続に成功した旨のメッセージが表示されたら「変更を保存」ボタンをクリックしてください。設定済の接続にSQL Databaseへの接続が追加されたことを確認してください。

Amazon Redshiftへの接続
接続 > 接続の追加 > 同期先 からAmazon Redshiftを選択します。

Amazon Redshiftの接続設定 > 設定 にて以下の項目をセットしてAmazon Redshiftへの接続を作成します。
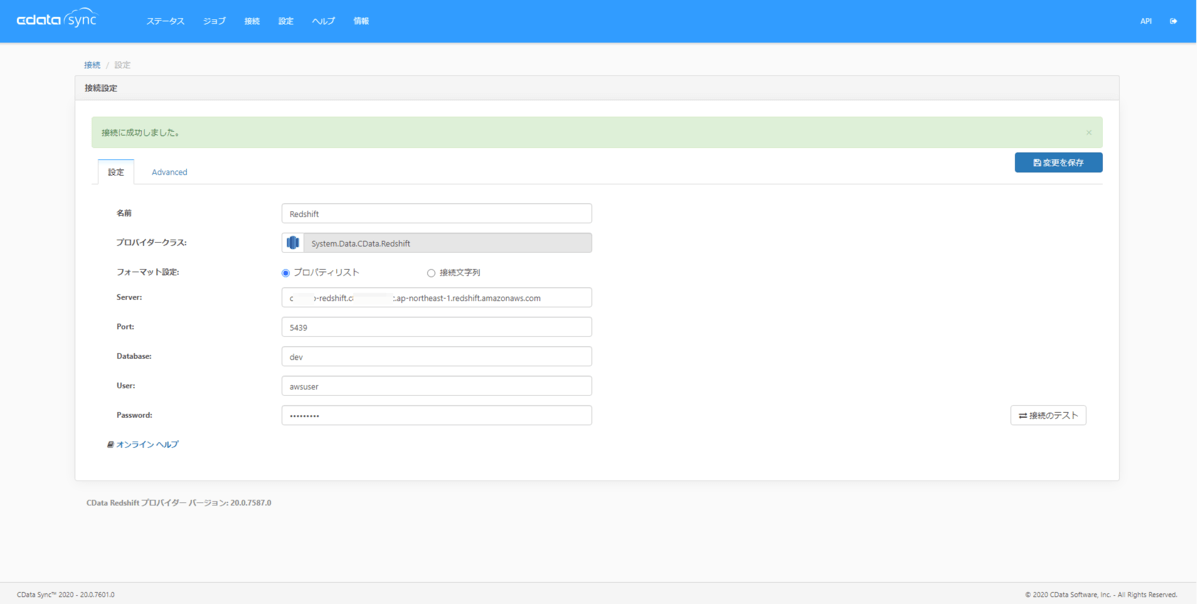
| プロパティ名 | 値 |
|---|---|
| 名前 | 任意(本例ではRedshift) |
| Server | Amazon Redshiftのエンドポイント内のServer名(例:cdatajptest-redshift.c87a16l6xalc.ap-northeast-1.redshift.amazonaws.com) |
| Port | Amazon Redshiftの接続ポート番号(例:5439) |
| Database | Amazon Redshiftの接続データベース名 |
| User | Amazon Redshiftの接続ユーザ名 |
| Password | Amazon Redshiftの接続パスワード |
「接続のテスト」ボタンをクリックして、接続に成功した旨のメッセージが表示されたら「変更を保存」ボタンをクリックしてください。設定済の接続にAmazon Redshiftへの接続が追加されたことを確認してください。
同期ジョブの作成
ジョブ > ジョブを追加 ボタンをクリックします。
新しいジョブを作成ウィンドウが起動するので、以下の項目をセットしてジョブを作成します。
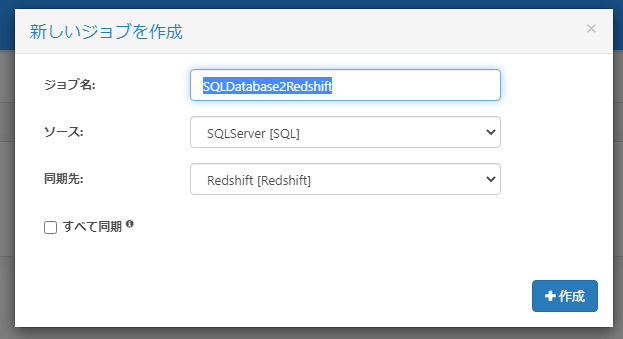
| プロパティ名 | 値 |
|---|---|
| ジョブ名 | 任意(本例ではSQLDatabase2Redshift) |
| ソース | SQLServer[SQL] |
| 同期先 | Redshift[Redshift] |
ジョブ設定 > テーブルを追加 をクリックします。
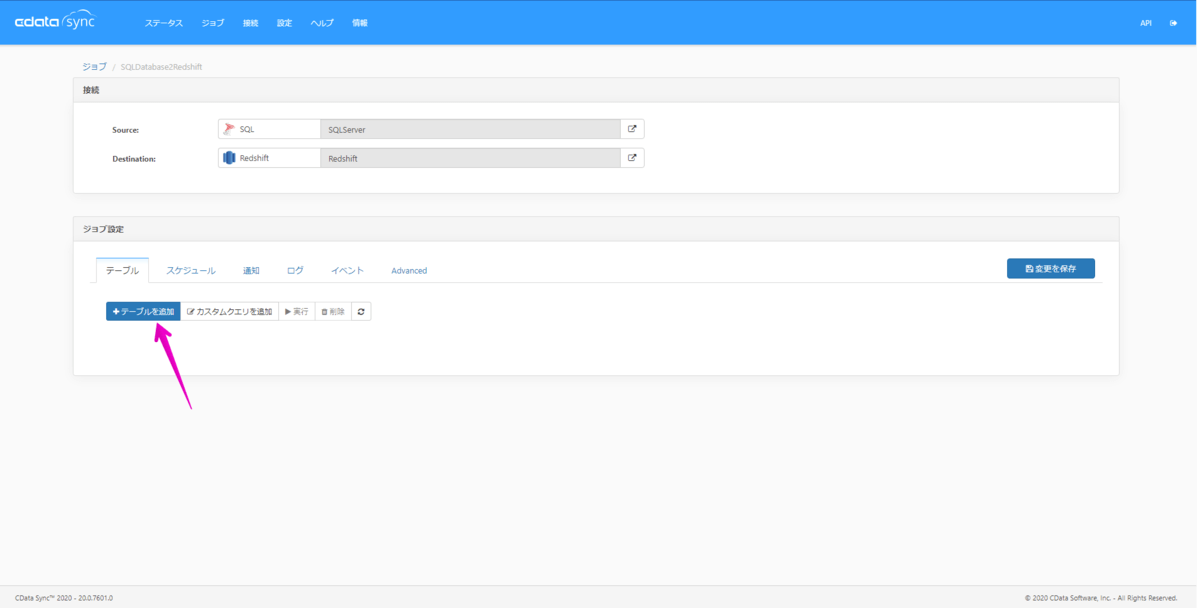
テーブルを追加 ウィンドウが起動して、SQL Database内のテーブルリストが表示されます。本例では、Northwindデータベース内のCustomers(顧客)とOrders(注文)テーブルを選択しました。選択したテーブルを追加ボタンをクリックします。
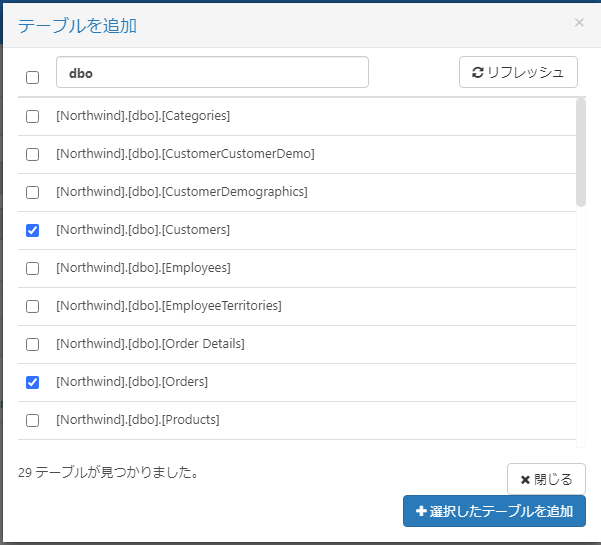
ジョブ設定に選択したテーブルが追加されたことを確認したら変更を保存ボタンをクリックしてジョブの設定を保存します。
ジョブの手動実行
それでは作成したジョブを手動で実行してみます。ジョブ設定 > テーブル 内の同期するテーブルを選択して実行ボタンをクリックします。
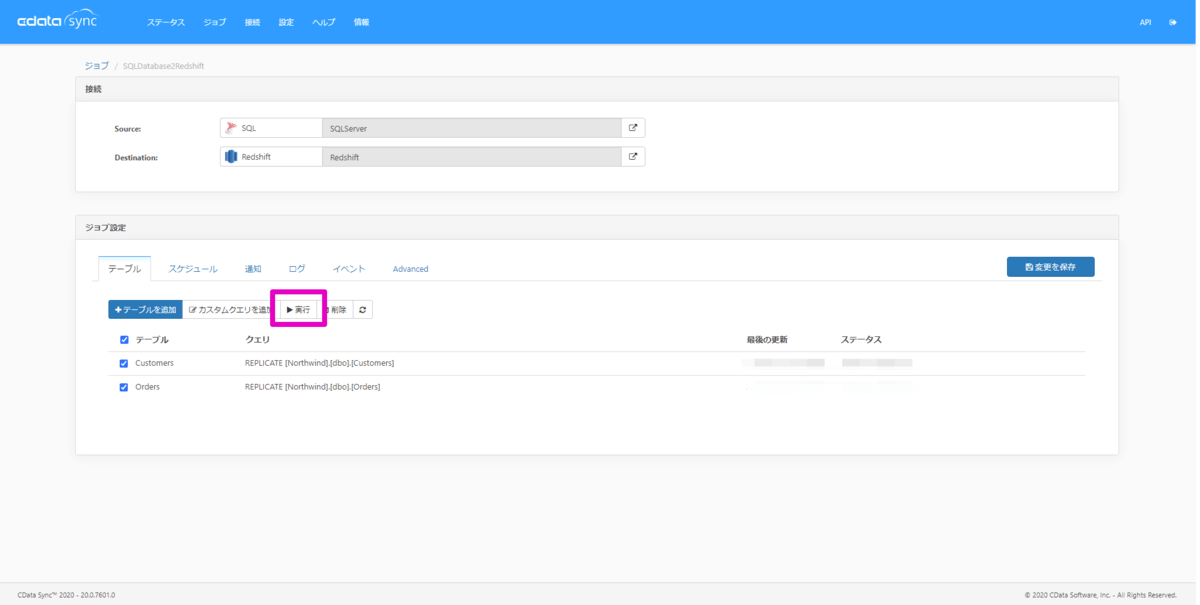
ジョブが正常に完了しました。というメッセージが表示されれば成功です。テーブルのステータス列には同期されたレコード数が表示されます。
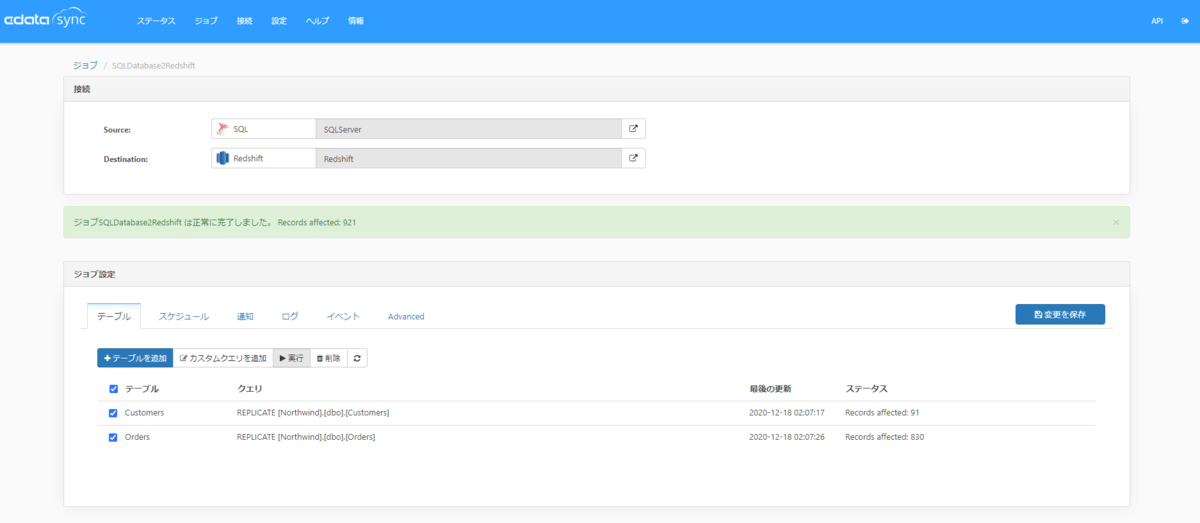
それでは、Redshiftのクエリエディタを開き、データが同期されているかみてみましょう。Customers、および、ordersテーブルが作成され、Cusotmersテーブルに対してクエリを発行するとステータス列の同期されたレコード数(本例ではCustomersテーブル:91件)が格納されていることを確認できれば成功です。
ジョブの自動実行
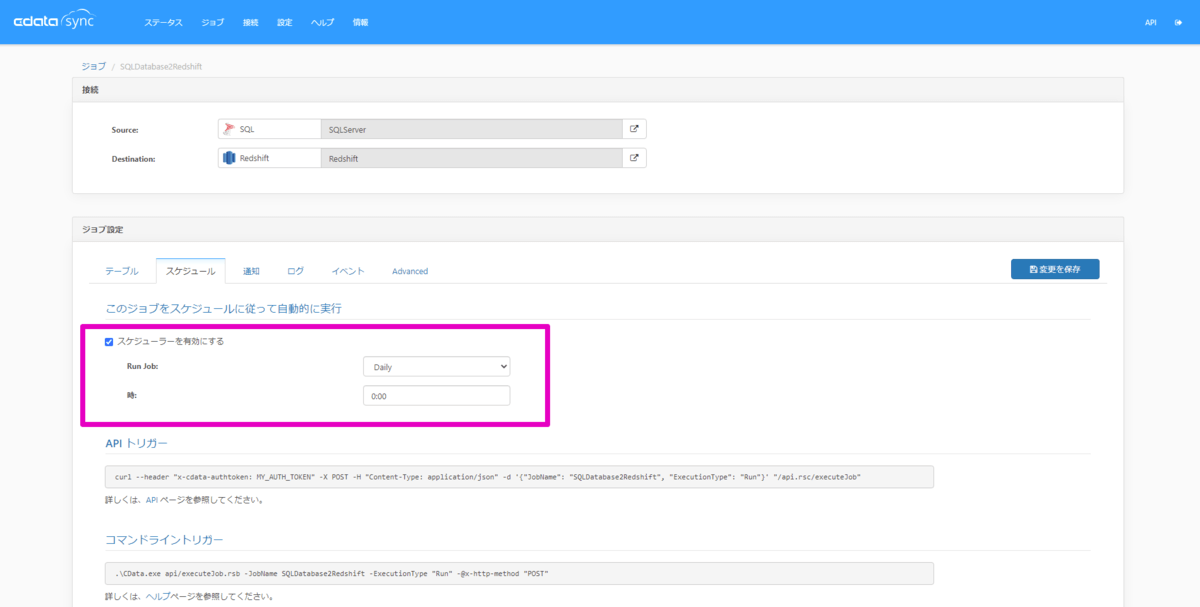
上記で作成したジョブを日時のジョブとして定時実行できるようにしてみましょう。ジョブ設定 > スケジュールタブ を開きます。スケジューラを有効にするのチェックをオンにして Run Job: Daily(日次)、時:0:00と設定して変更を保存します。これで、毎日夜の0時にこの同期ジョブが自動で実行できるようになりました。
ジョブ毎の次の実行予定日時についてはジョブ一覧画面の次の実行列から確認できます。この例では、次は2020-12-19 0時の実行でセットされていることを確認できます。
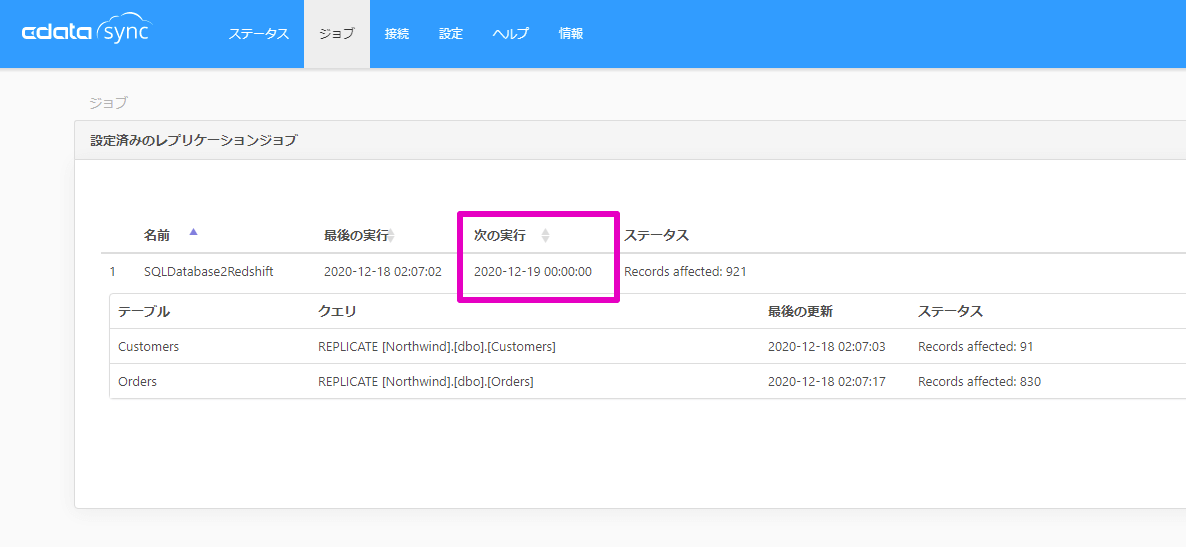
なお、ジョブの実行はWeb APIからのPOSTメソッドでのリクエストやコマンドラインからも実行できるので外部からのジョブを呼び出すことも可能です。
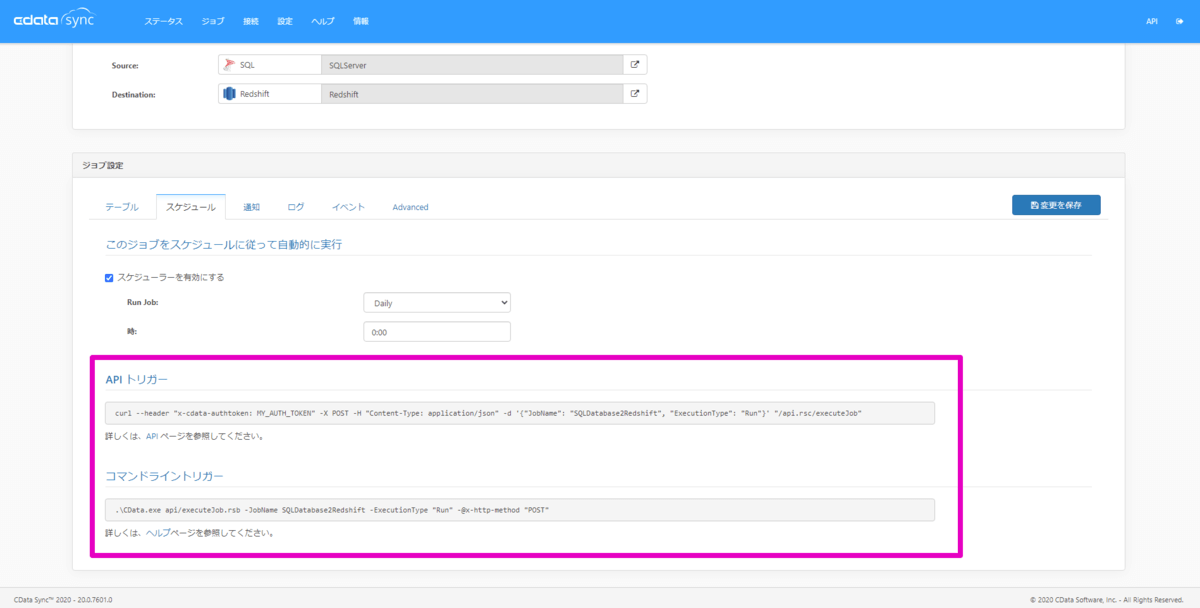
差分更新
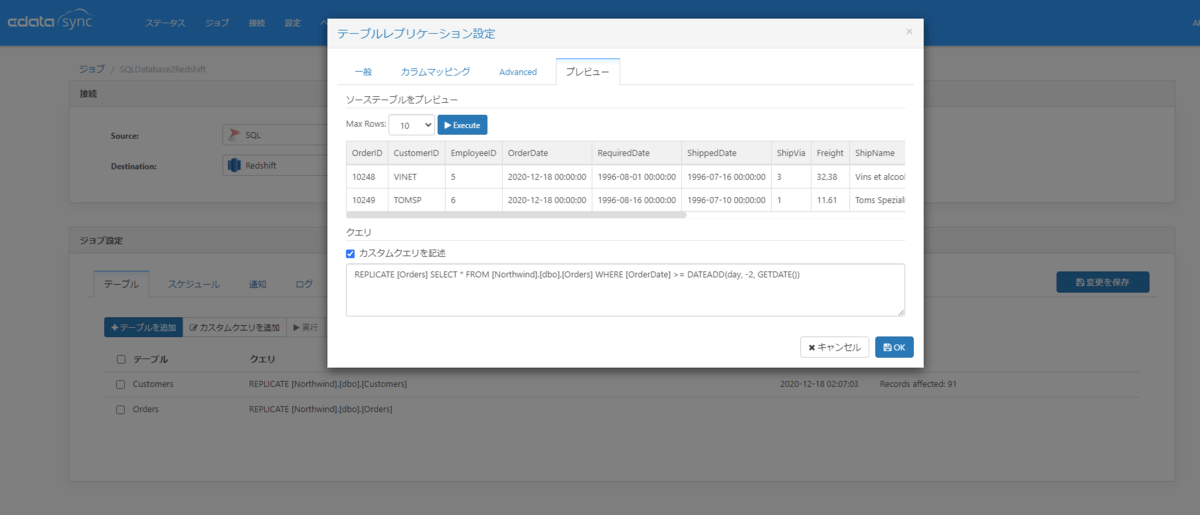
上記で作成した同期ジョブは、全件洗い替えです。Orders(注文)などのトランザクションデータは一般的に日付項目(OrderDate)を持っており、データベースに日々追加されます。CData Syncでは、日付・日時項目を持っているテーブルから「OrderDateが直近2日間のデータのみ」といったカスタムクエリでデータを抽出して同期することができます。テーブルレプリケーションウィンドウのカスタムクエリを記述をオンにして、直近2日文の注文のみを抽出する条件「WHERE [OrderDate] >= DATEADD(day, -2, GETDATE())」のSELECT文を以下のように「REPLICATE [同期するテーブル名] 」の後に続けて記述します。
REPLICATE [Orders] SELECT * FROM [Northwind].[dbo].[Orders] WHERE [OrderDate] >= DATEADD(day, -2, GETDATE())
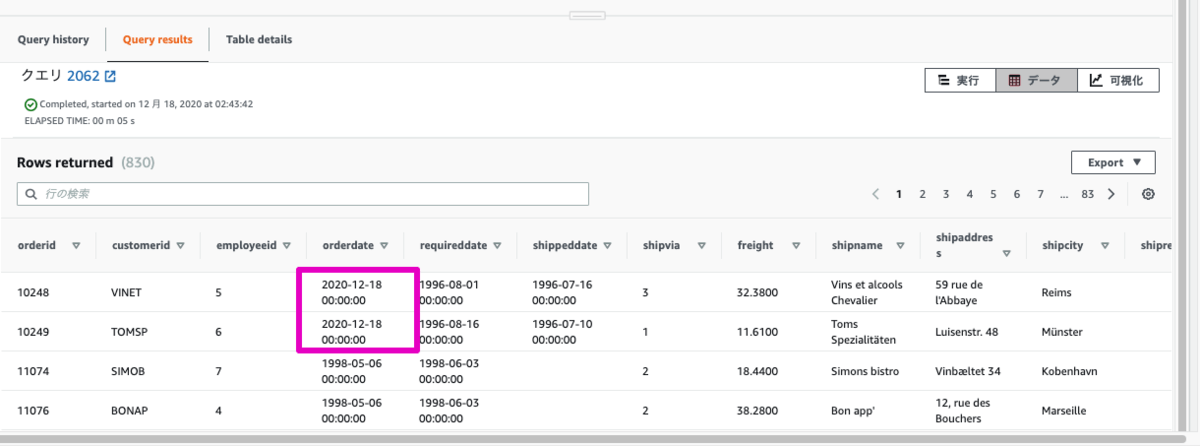
プレビュータブでこの条件で抽出されるレコードを確認できます。本例ではOrderDateが現在(2020-12-18)からみて2日以内のデータのみ抽出されていることを確認できます。
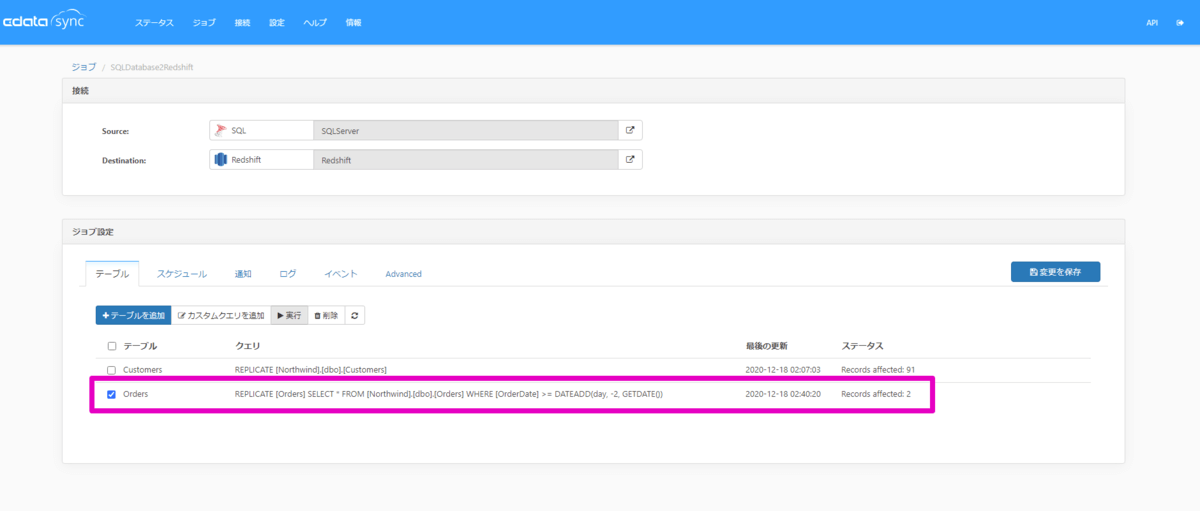
ジョブ設定を保存して再度手動実行します。すると、上記設定を加えたOrdersテーブルのステータス列を確認すると差分の2件のみの更新となっていることを確認できます。
再度、Redshift側の同期先のテーブルをみてみましょう。新しいOrderDateのレコードが追加されていることを確認できます。なお、同テーブルには今回の実行で同期された2件だけではなく前回全件同期したレコードも含まれています。
差分更新時にRedshiftにどのようなクエリが発行されているかRedshiftのクエリヒストリーから確認してみましょう。Redshiftの一時テーブルに差分で抽出したレコードをINSERTしてRedshift内の既存テーブルとキー(orderid)が一致するレコードをDELETEして、一時テーブルのデータをINSERTする流れとなっています。
INSERT INTO "Orders_cdata_replicate_temporary_table" ("orderdate","orderid","employeeid","shipregion","shipcountry","shipaddress","shippostalcode","shipcity","freight","requireddate","shippeddate","shipname","customerid","shipvia") VALUES ('2020-12-17T00:00:00.000+09:00',10252,4,null,'Belgium','Boulevard Tirou, 255','B-6000','Charleroi',51.3,'1996-08-06T00:00:00.000+09:00','1996-07-11T00:00:00.000+09:00','Suprêmes délices','SUPRD',2), ('2020-12-18T00:00:00.000+09:00',10248,5,null,'France','59 rue de l''Abbaye','51100','Reims',32.38,'1996-08-01T00:00:00.000+09:00','1996-07-16T00:00:00.000+09:00','Vins et alcools Chevalier','VINET',3), ('2020-12-18T00:00:00.000+09:00',10254,5,null,'Switzerland','Hauptstr. 31','3012','Bern',22.98,'1996-08-08T00:00:00.000+09:00','1996-07-23T00:00:00.000+09:00','Chop-suey Chinese','CHOPS',2) DELETE FROM "Orders" USING "Orders_cdata_replicate_temporary_table" WHERE "orders".orderid="orders_cdata_replicate_temporary_table".orderid; INSERT INTO "Orders" SELECT * FROM "Orders_cdata_replicate_temporary_table";
まとめ
本記事では、RDBMS -> DWHへのデータ統合としてAzure SQL Database -> Amazon Redshiftの例でご紹介しましたが、CData Syncは他にも主要なRDB、DWH、NoSQL系データベースへの接続をサポートしています。CData Syncは30日間の無償評価版もございますので是非お試しください。
