各製品の資料を入手。
詳細はこちら →Apache Kafka Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
SnapLogic はintegration Platform-as-a-Service(iPaaS)であり、ユーザーはノーコードでデータ連携フローを作成できます。CData JDBC ドライバと組み合わせることで、ユーザーはSnapLogic ワークフローからKafka を含む250を超えるSaaS、ビッグデータ、NoSQL データソースのリアルタイムデータに接続できます。
組み込みの最適化されたデータ処理によって、CData JDBC Driver はリアルタイムKafka データを高速に扱えます。プラットフォームがKafka に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をKafka に直接プッシュし、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブデータソース型を使用してKafka データを操作することができます。
SnapLogic からKafka データに接続するには、CData Kafka JDBC Driver をダウンロードしてインストールします。インストール画面に従ってください。インストールが完了すると、インストール先のディレクトリ(デフォルトでは、C:/Program Files/CData/CData JDBC Driver for ApacheKafka/lib)にJAR ファイルが作成されます。
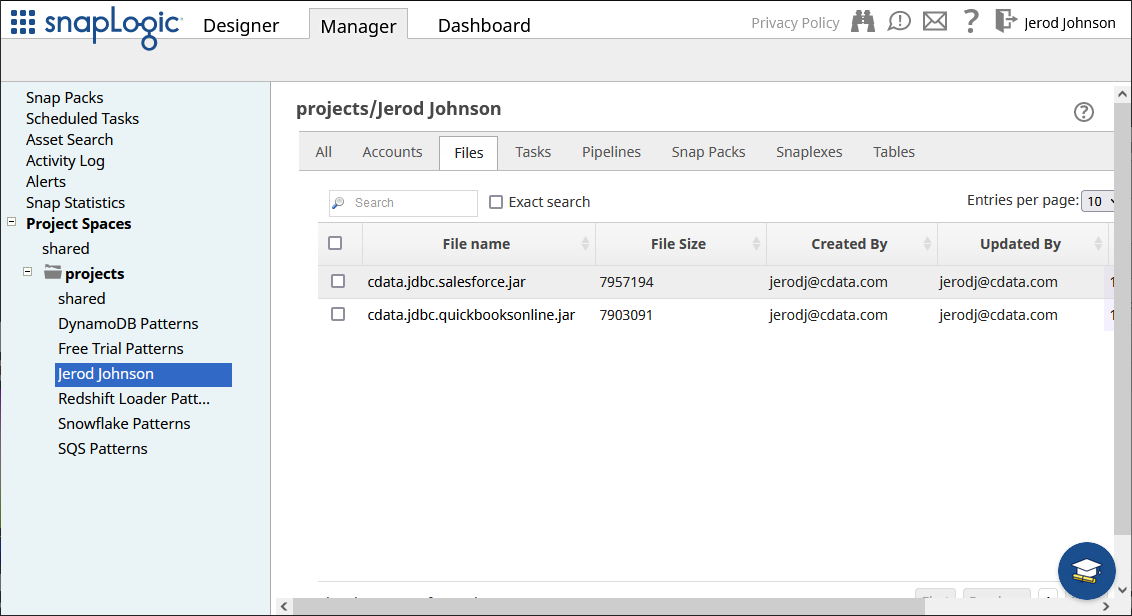
インストール後、JDBC JAR ファイルをSnapLogic 内のディレクトリ(例えば、projects/Jerod Johnson)にManager タブからアップロードします。
JDBC Driver がアップロードされると、Kafka への接続を作成できます。
JDBC URL をKafka JDBC Driver 用のJDBC 接続文字列に設定します。例えば、
jdbc:apachekafka:User=admin;Password=pass;BootStrapServers=https://localhost:9091;Topic=MyTopic;RTK=XXXXXX;です。
NOTE: RTK は評価版もしくは製品版のキーです。詳しくは、CData のサポートチームにご連絡ください。
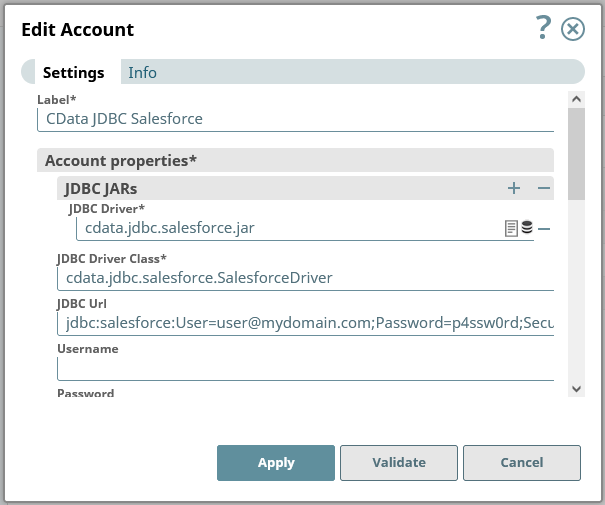
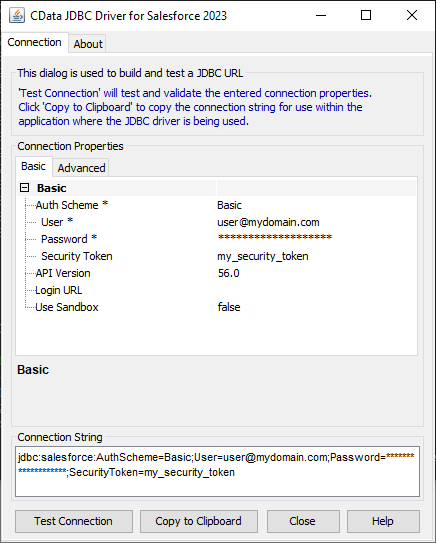
JDBC URL の作成の補助として、Kafka JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.apachekafka.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
BootstrapServers およびTopic プロパティを設定して、Apache Kafka サーバーのアドレスと、対話するトピックを指定します。
サーバー証明書を信頼する必要がある場合があります。そのような場合は、必要に応じてTrustStorePath およびTrustStorePassword を指定してください。
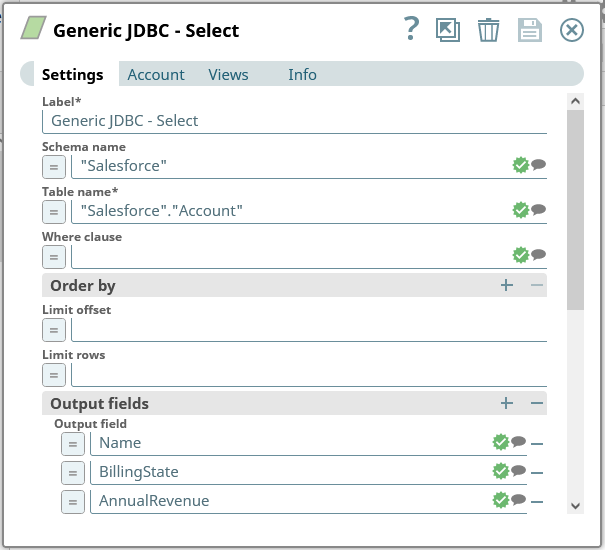
接続を検証、適用後に開くフォームで、クエリを設定します。
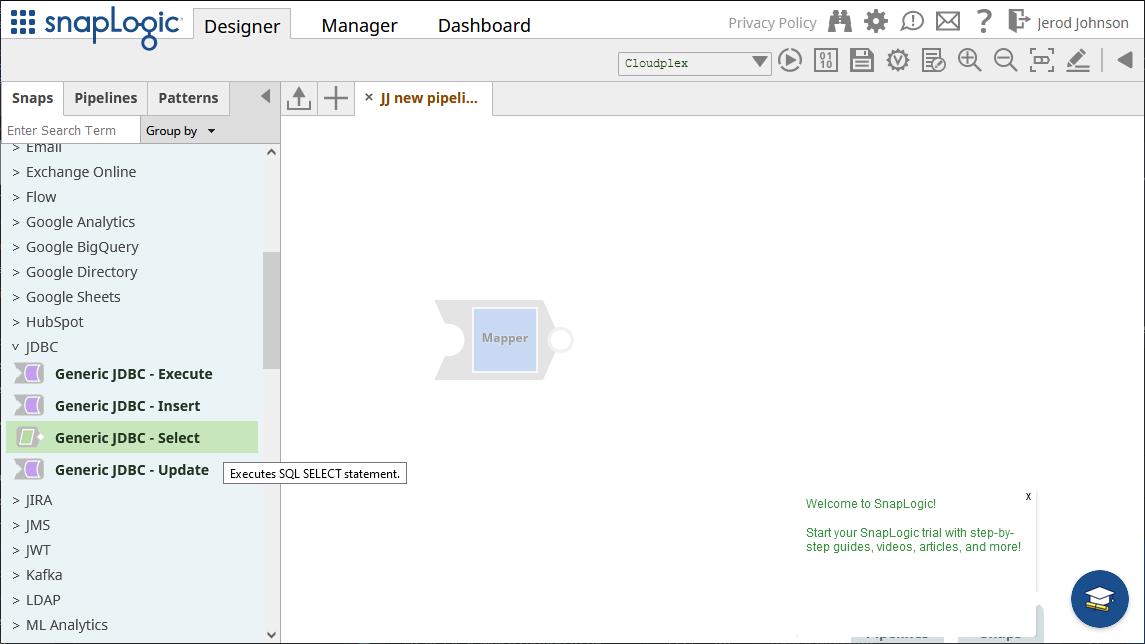
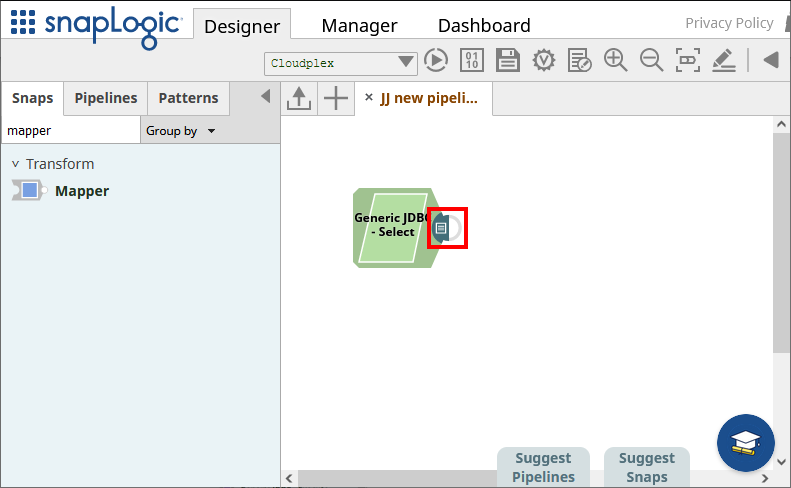
Generic JDBC - Select snap を保存します。
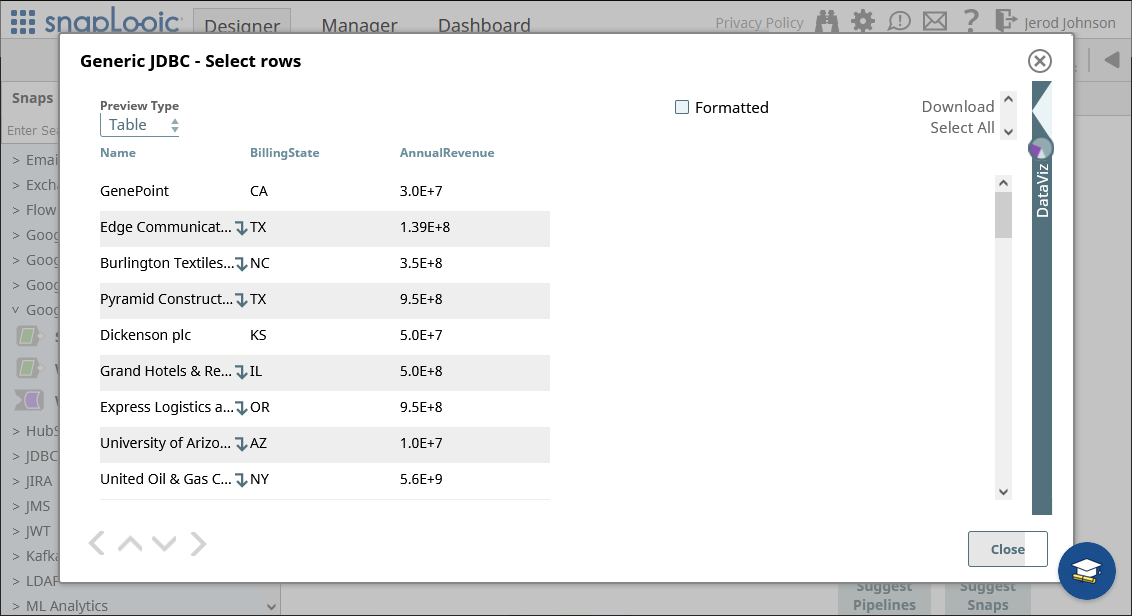
接続とクエリを設定したら、snap の終端部分(以下のハイライト部分)をクリックしてデータをプレビューします。
結果が期待どおりのものであることを確認したら、他のsnap を追加してKafka データを別のエンドポイントに渡すこともできます。
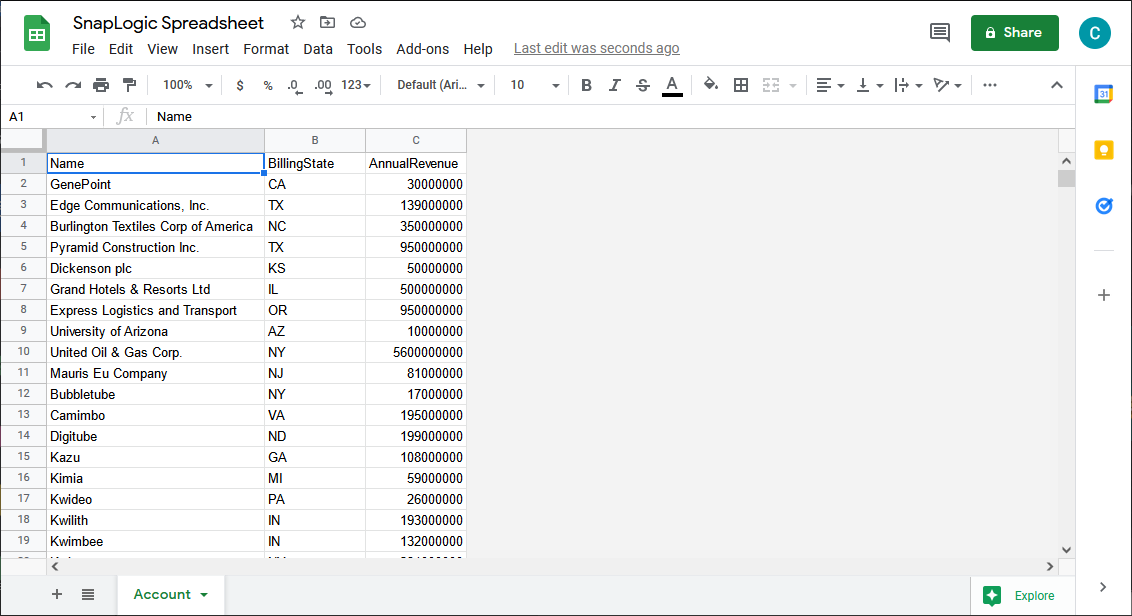
本記事では、データをGoogle Spreadsheet にロードします。他のあらゆるサポートされているsnap が使用でき、Generic JDBC snap を他のCData JDBC ドライバと利用してデータを外部サービスに移すこともできます。
これで、接続済みのパイプラインを実行してKafka からデータを抽出し、Google Spreadsheet にプッシュできます。
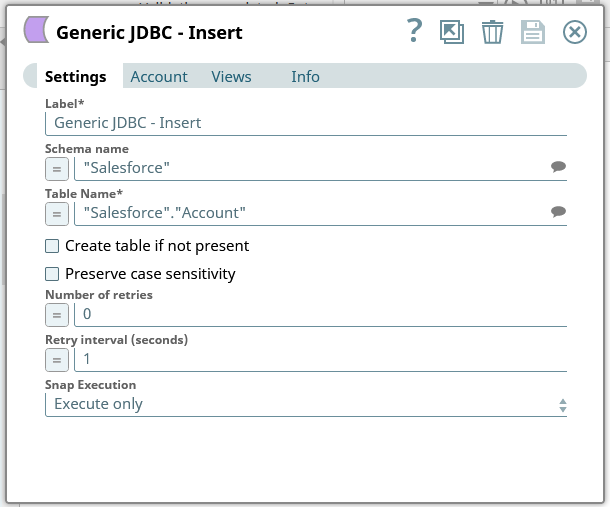
上述のように、JDBC Driver for ApacheKafka をSnapLogic から使用してデータをKafka に書き込むことができます。まずは、Generic JDBC - Insert またはGeneric JDBC - Update snap をダッシュボードに追加します。
これで、Kafka にデータを書き込んだり、新しいレコードを挿入したり、既存のレコードを更新するsnap が設定できました。
CData JDBC Driver for ApacheKafka を使えば、Kafka データを外部サービスに連携するためのパイプラインをSnapLogic で作成できます。Kafka への接続に関する詳細については、CData のKafka 連携ページを参照してください。30日の無償評価版をダウンロードして今すぐ使い始めましょう。