ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Kafka ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Kafka ODBC Driver を使って、ODBC 接続をサポートするあらゆるアプリケーション・ツールからApache Kafka にデータ連携。
Apache Kafka データストリームにデータベースと同感覚でアクセスして、トピックに使い慣れたODBC インターフェースで双方向連携。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData ODBC Driver for ApacheKafka はODBC 標準のKafka からのリアルタイムデータへのアクセスを可能にし、使い慣れたSQL クエリを用いて、さまざまなBI、レポート、ETL ツールでKafka データを直接扱うことができます。この記事では、Alteryx Designer でODBC 接続を使ってKafka データに接続し、セルフサービスBI、データプレパレーション、データブレンディングから高度な分析までを実行する方法を紹介します。
CData ODBC ドライバーには最適化されたデータ処理が組み込まれており、Alteryx Designer でリアルタイムKafka データを扱う上で高いパフォーマンスを提供します。Alteryx Designer からKafka にSQL クエリを発行すると、CData ドライバーはフィルタや集計などのKafka 側でサポートしているSQL 操作をKafka に直接渡し、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブのAlteryx データフィールド型を使ってKafka データを可視化および分析できます。
CData ODBC ドライバは、以下のような特徴を持った製品です。
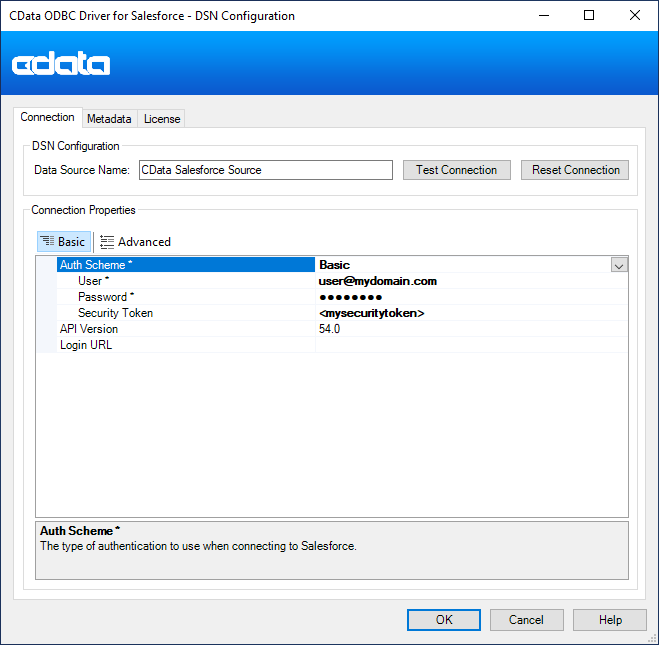
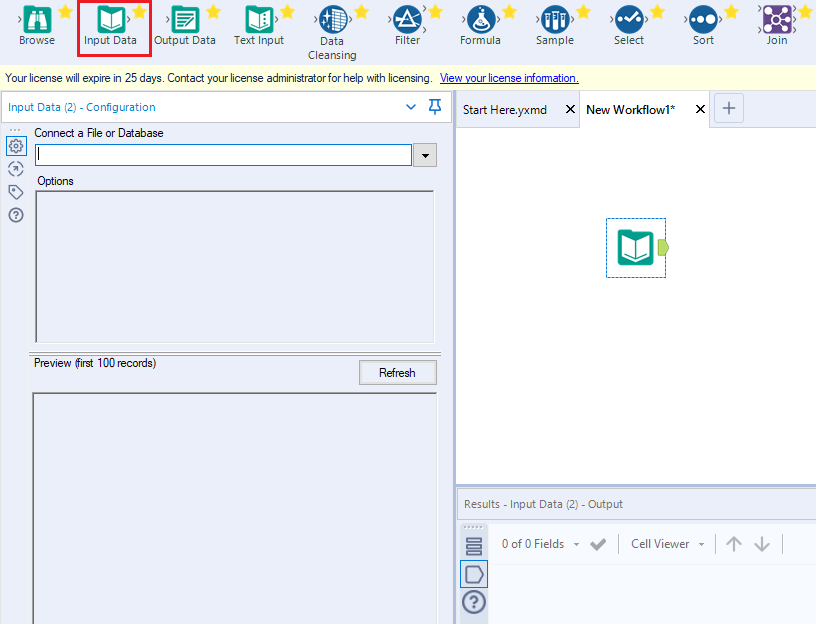
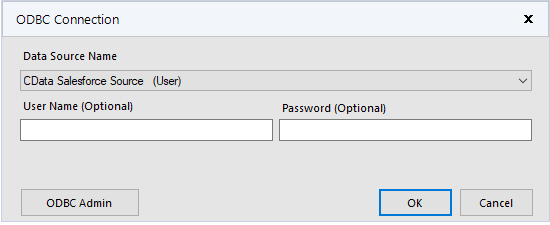
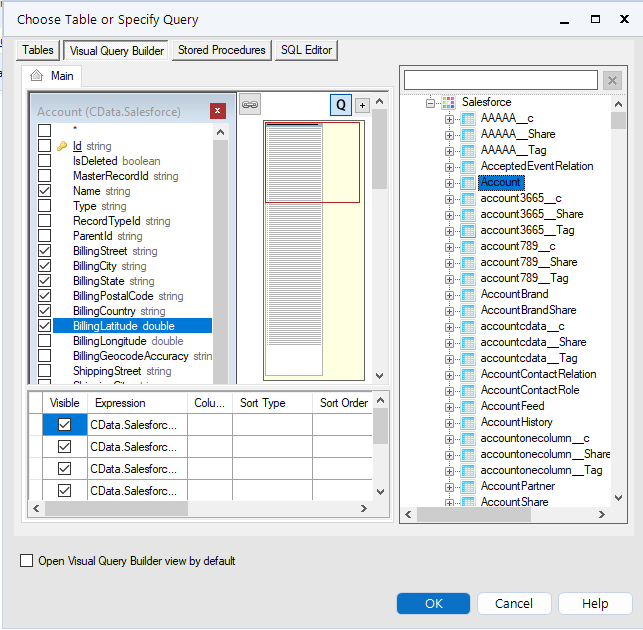
CData ODBC ドライバでは、1.データソースとしてKafka の接続を設定、2.Alteryx Designer 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからApacheKafka ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
BootstrapServers およびTopic プロパティを設定して、Apache Kafka サーバーのアドレスと、対話するトピックを指定します。
サーバー証明書を信頼する必要がある場合があります。そのような場合は、必要に応じてTrustStorePath およびTrustStorePassword を指定してください。
DSN を構成する際、Max Rows 接続プロパティも設定することができます。これを設定すると返される行数が制限されるため、レポートやビジュアライゼーションを作成する際のパフォーマンスが向上します。
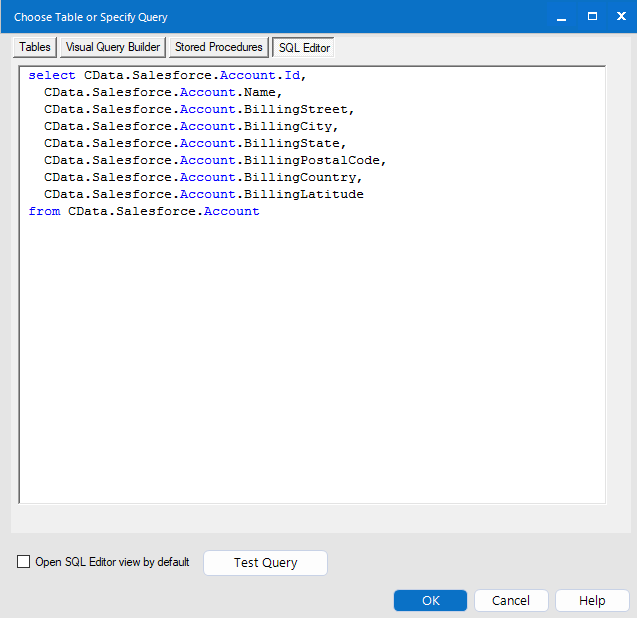
データセットをさらにカスタマイズする場合は、SQL エディタを開いてクエリを手動で変更し、句や集計などの操作を追加して、必要なKafka データを正確に取得できるようにします。
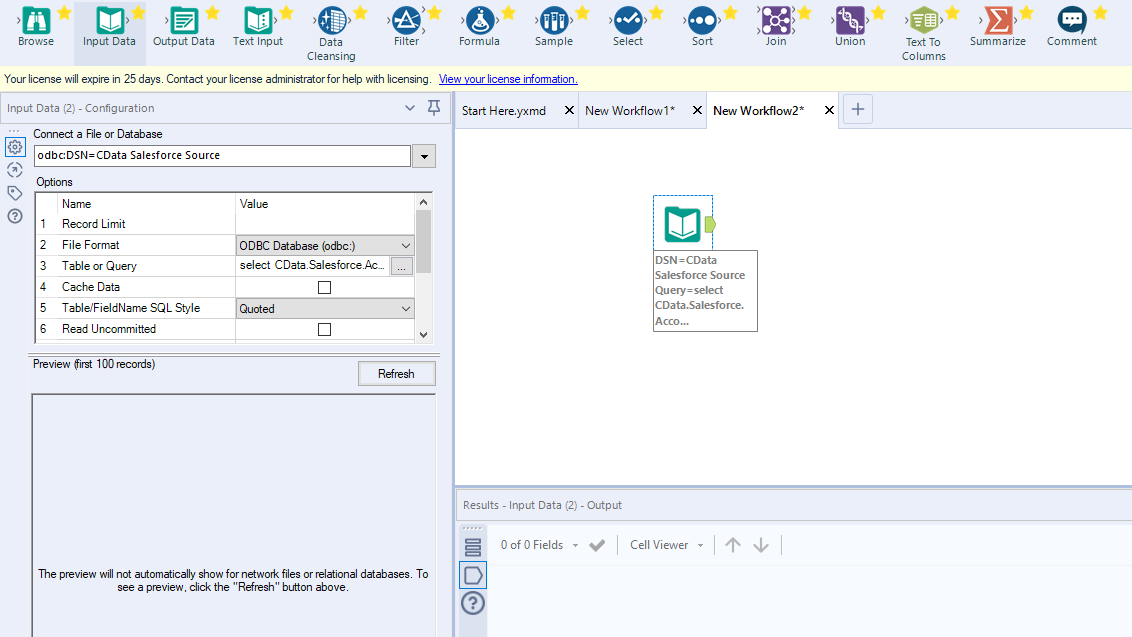
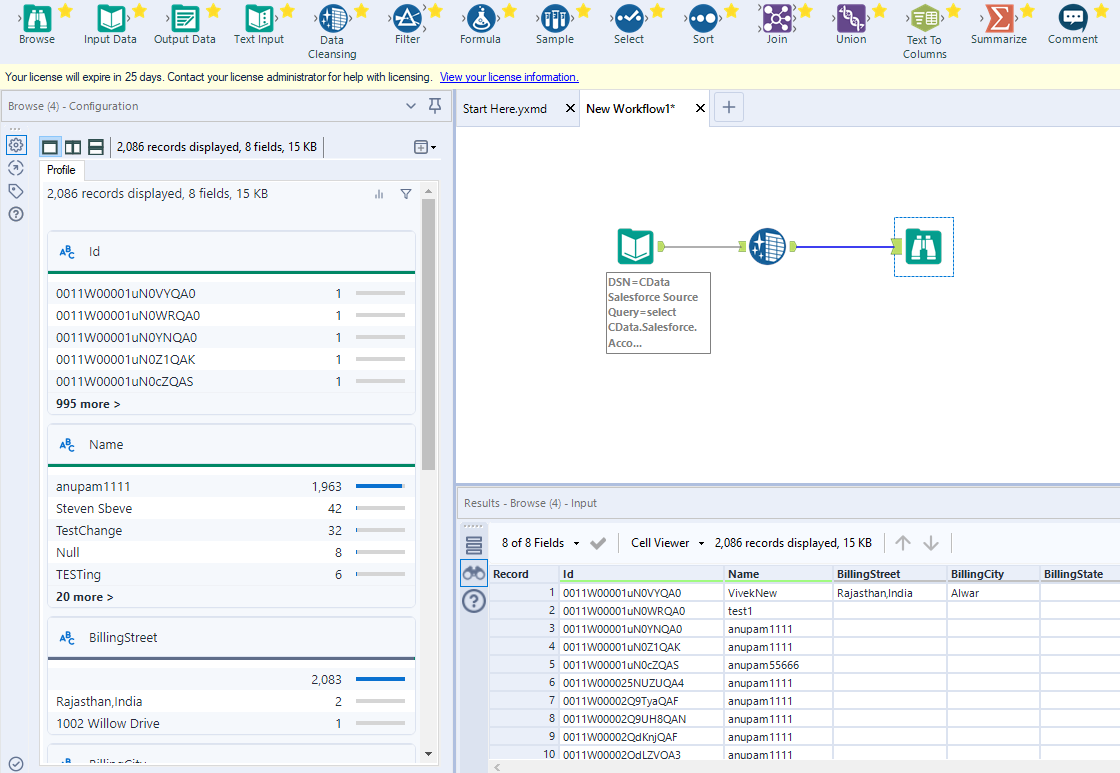
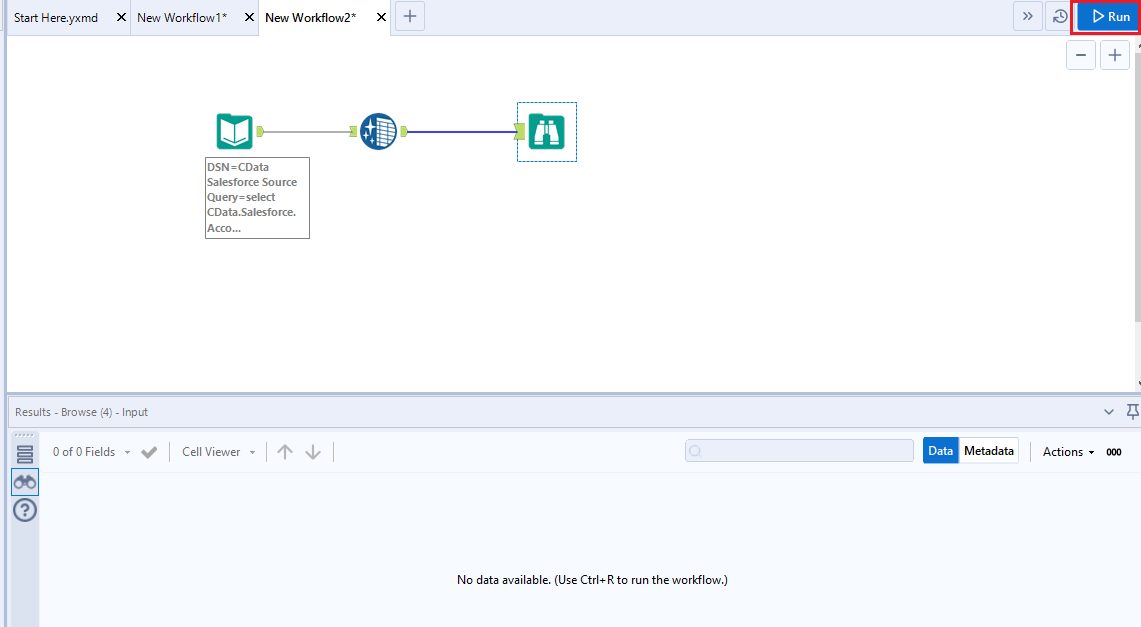
クエリを定義したら、Alteryx Designer でKafka データを操作できるようになります。
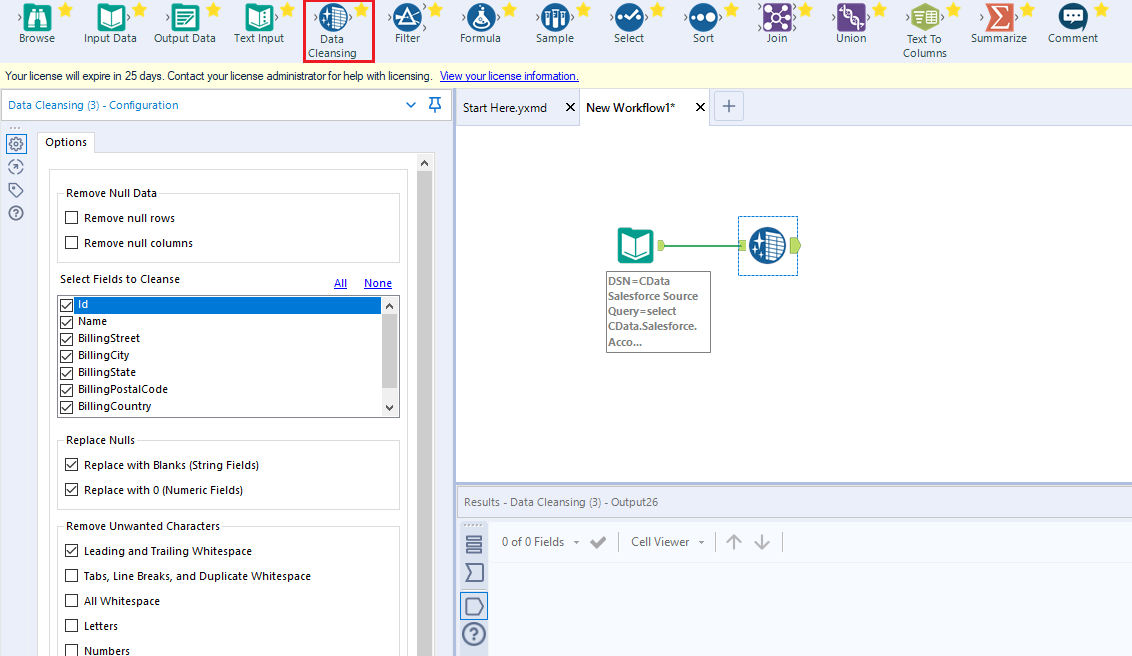
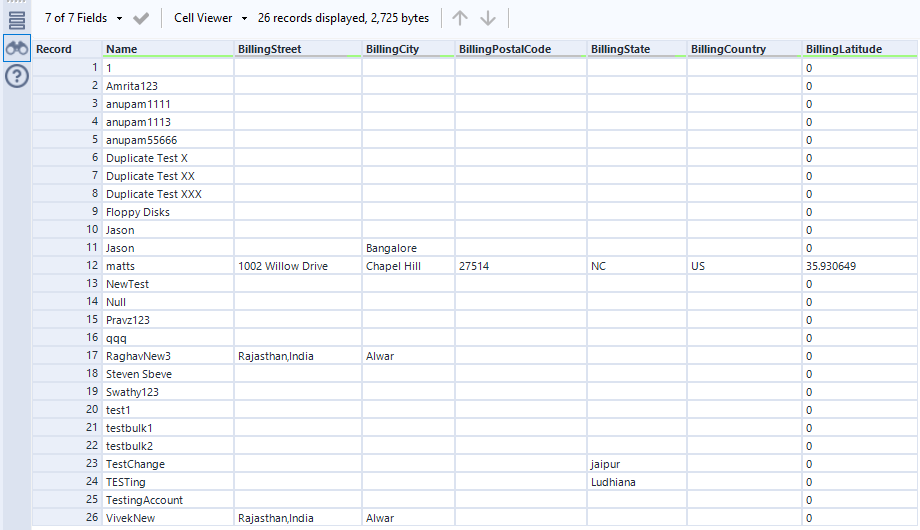
これで、Kafka データを準備、ブレンディング、分析するためのワークフローを作成する準備ができました。CData ODBC ドライバは動的なメタデータ検出を実行し、Alteryx データフィールドタイプを使用してデータを表示し、Designer ツールを活用して必要に応じてデータを操作し、意味のあるデータセットを構築できるようにします。以下の例では、データをクレンジングして参照します。
高いパフォーマンスを発揮する組み込みのデータ処理により、Alteryx でKafka データを迅速にクレンジング、変換、分析することができます。