ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Kafka ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Kafka ODBC Driver を使って、ODBC 接続をサポートするあらゆるアプリケーション・ツールからApache Kafka にデータ連携。
Apache Kafka データストリームにデータベースと同感覚でアクセスして、トピックに使い慣れたODBC インターフェースで双方向連携。
CData


こんにちは!リードエンジニアの杉本です。
Qlik Replicate はBI ツールのQlik Sense で有名な、Qlik 社が提供するデータ分析基盤のためのデータパイプライン・データ統合ツールです。主要なプラットフォームに多く対応しているのが特徴で、AWS・GCP・Azure・Oracle・Snowflake などのDWH に各種データを取り込むことが可能です。
Qlik Replicate ではODBC インターフェースが用意されているので、CData ODBC Driver for ApacheKafka と組み合わせることで、各種クラウドサービスのAPI にアクセスすることができるようになります。本記事では、CData ODBC ドライバを使ってQlik Replicate からKafka データをMySQL にレプリケートする方法をご紹介します。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてKafka の接続を設定、2.Qlik Replicate 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからApacheKafka ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
インストール後、ODBC DSN(データソース名)で接続プロパティを設定します。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および設定できます。
BootstrapServers およびTopic プロパティを設定して、Apache Kafka サーバーのアドレスと、対話するトピックを指定します。
サーバー証明書を信頼する必要がある場合があります。そのような場合は、必要に応じてTrustStorePath およびTrustStorePassword を指定してください。
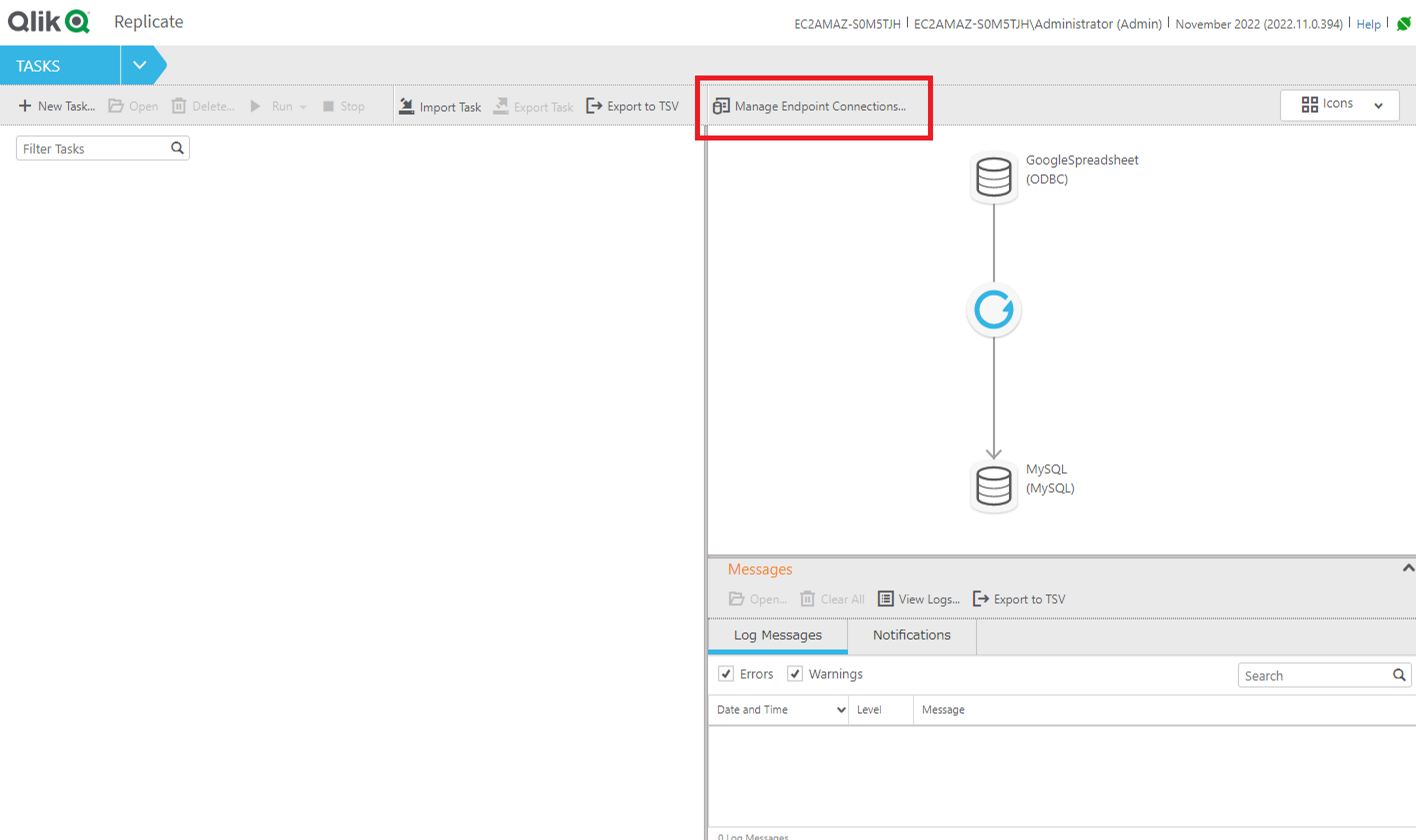
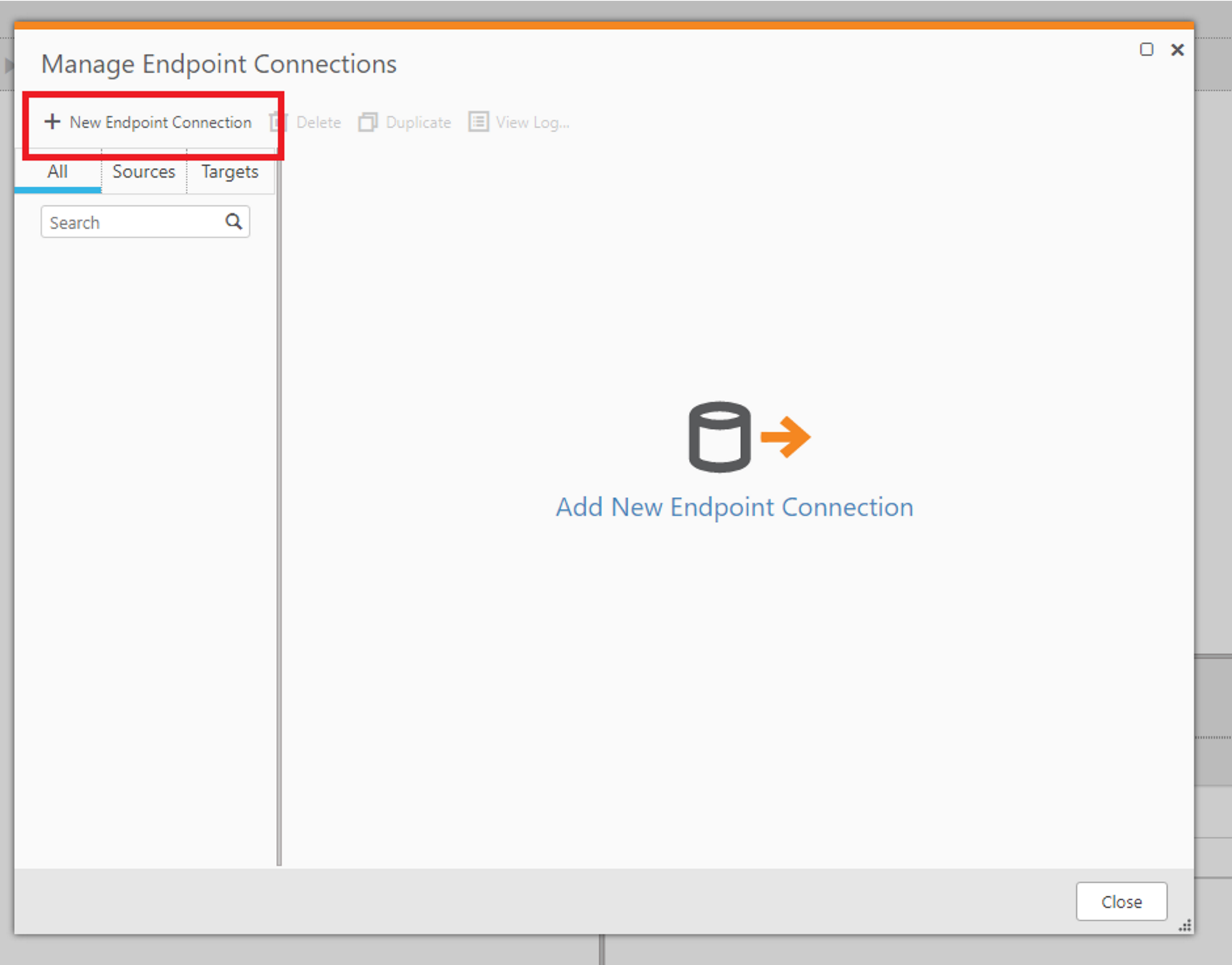
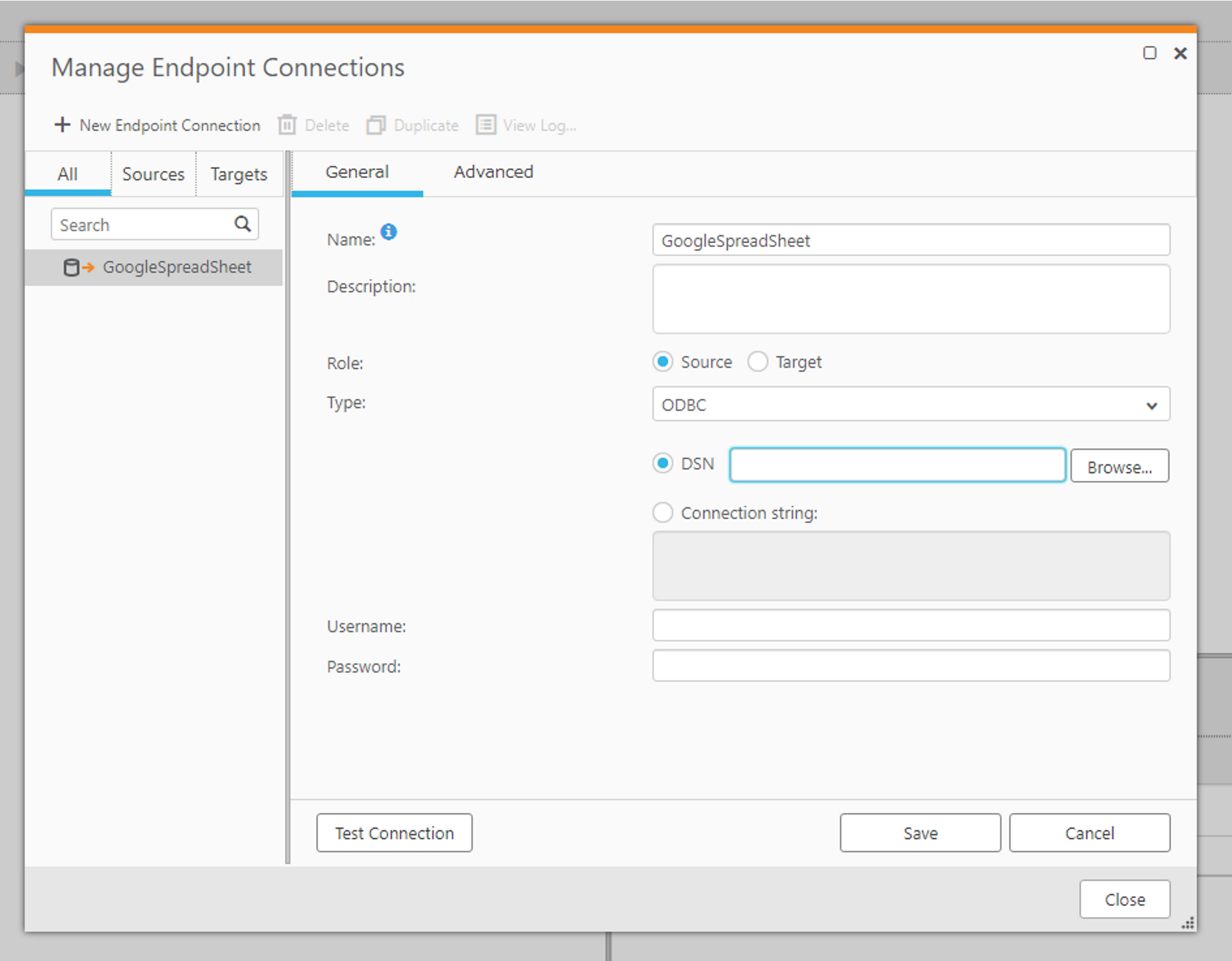
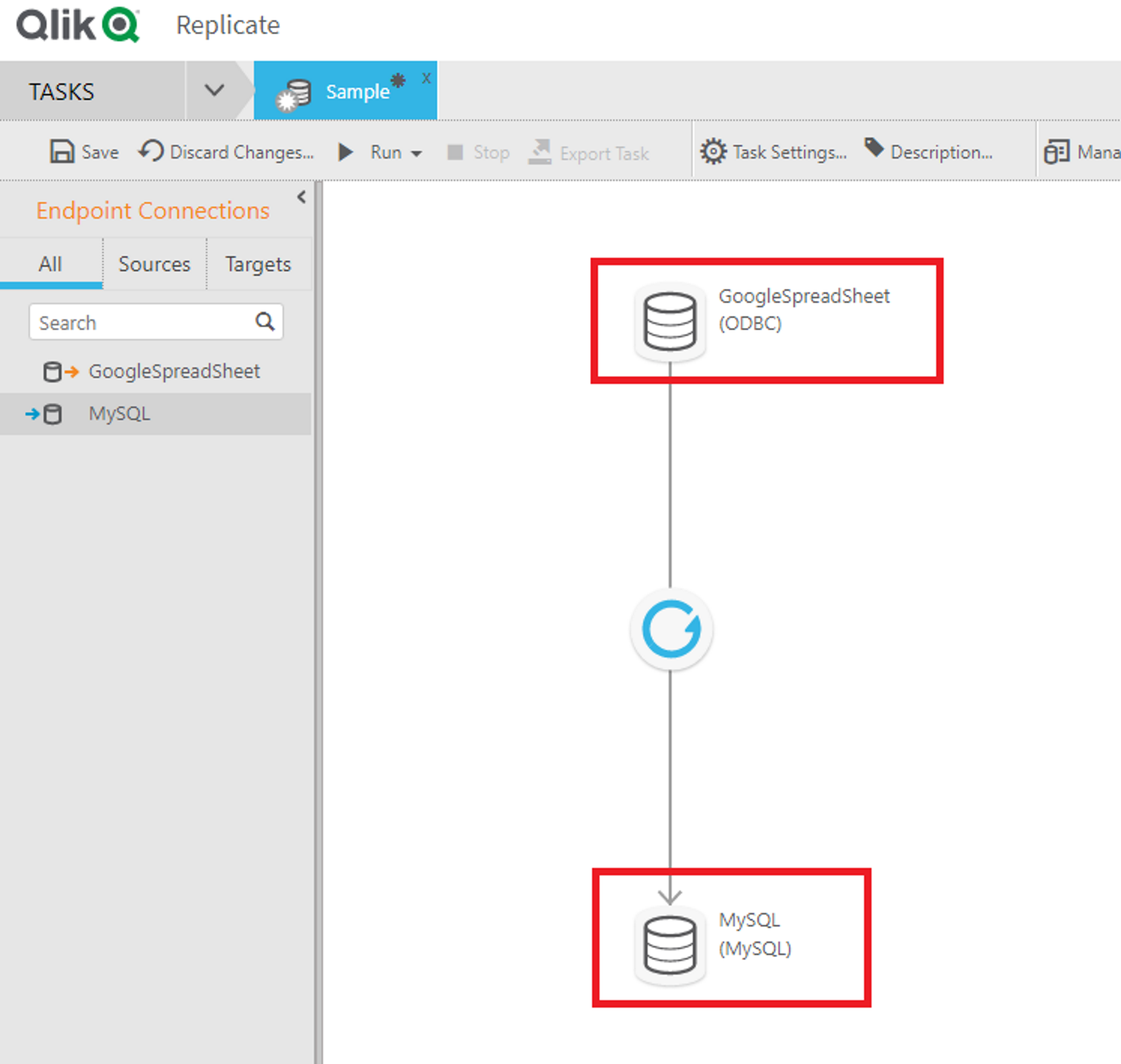
CData ODBC ドライバの設定が完了したら、Qlik Replicate を立ち上げてレプリケーション構成を進めていきましょう。Qlik Replicate ではタスクという単位でレプリケーション処理を構成していきますが、まずタスクで利用するデータソースとレプリケーション先のコネクション情報を登録する必要があるので、この設定を行います。
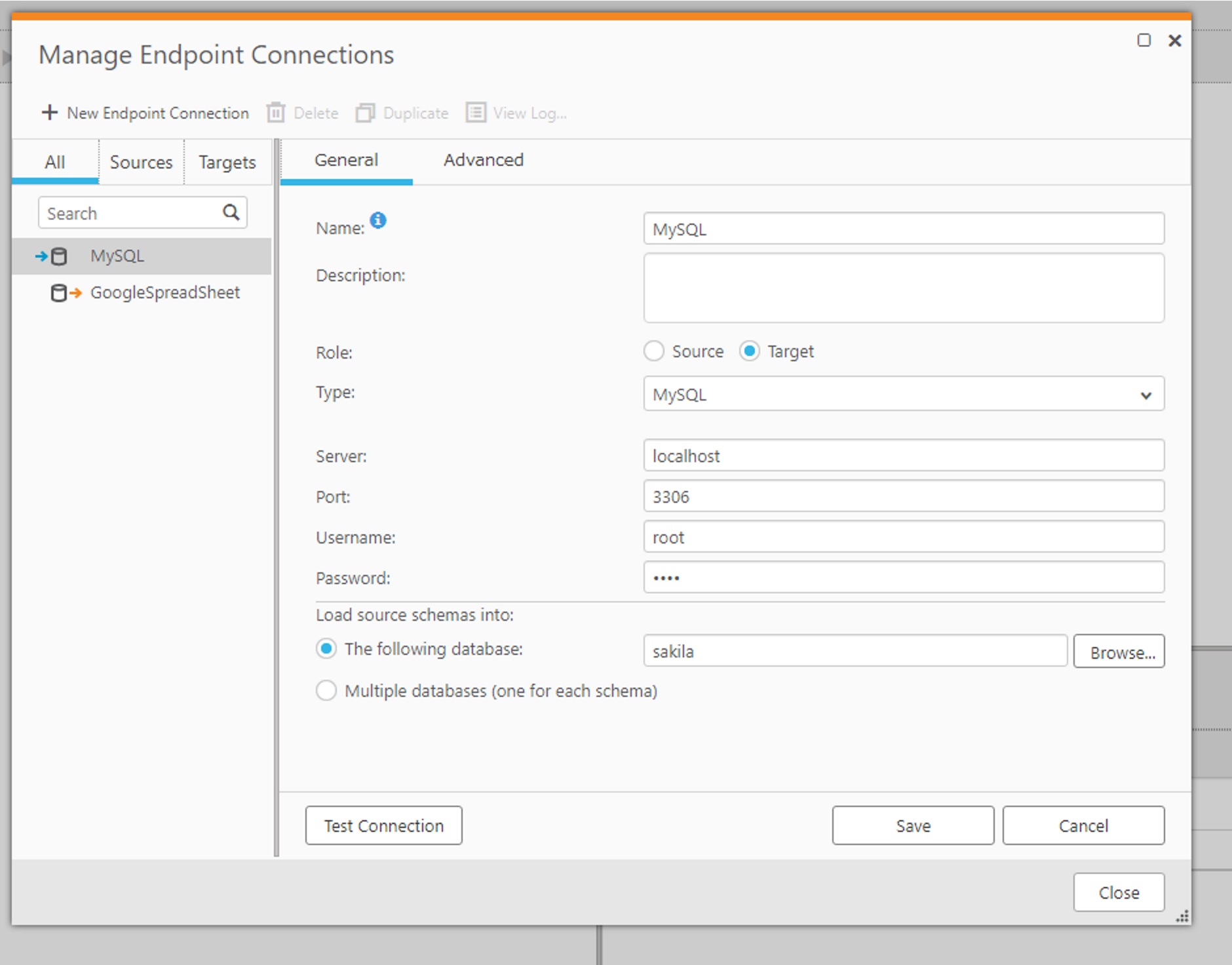
続いて、レプリケーション先となるMySQL へのコネクションも追加します。
コネクションの作成が完了したら、実際のレプリケーション処理であるTask の作成を進めていきましょう。
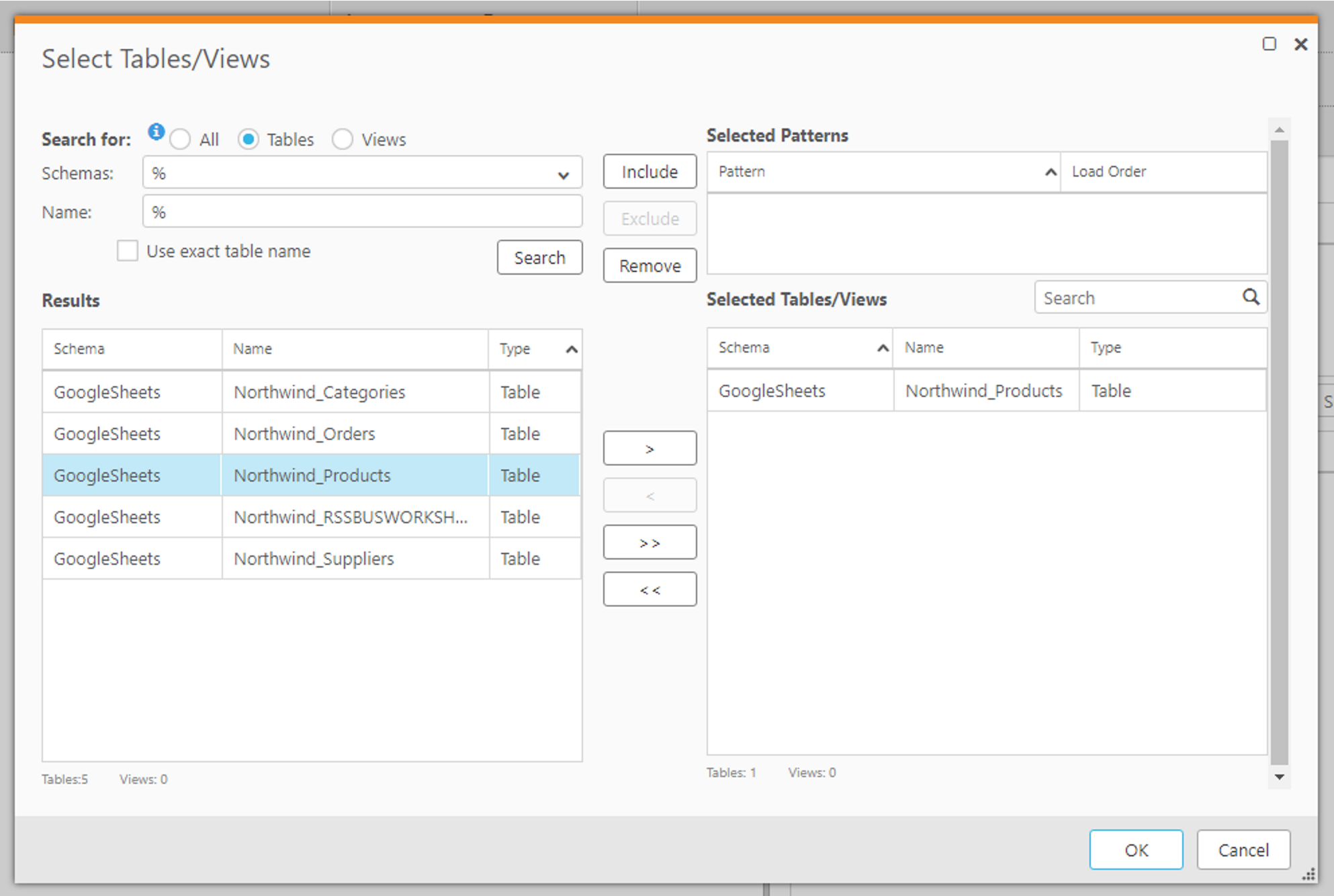
データソースとターゲットを決めたら、レプリケーション対象のテーブルを指定しましょう。
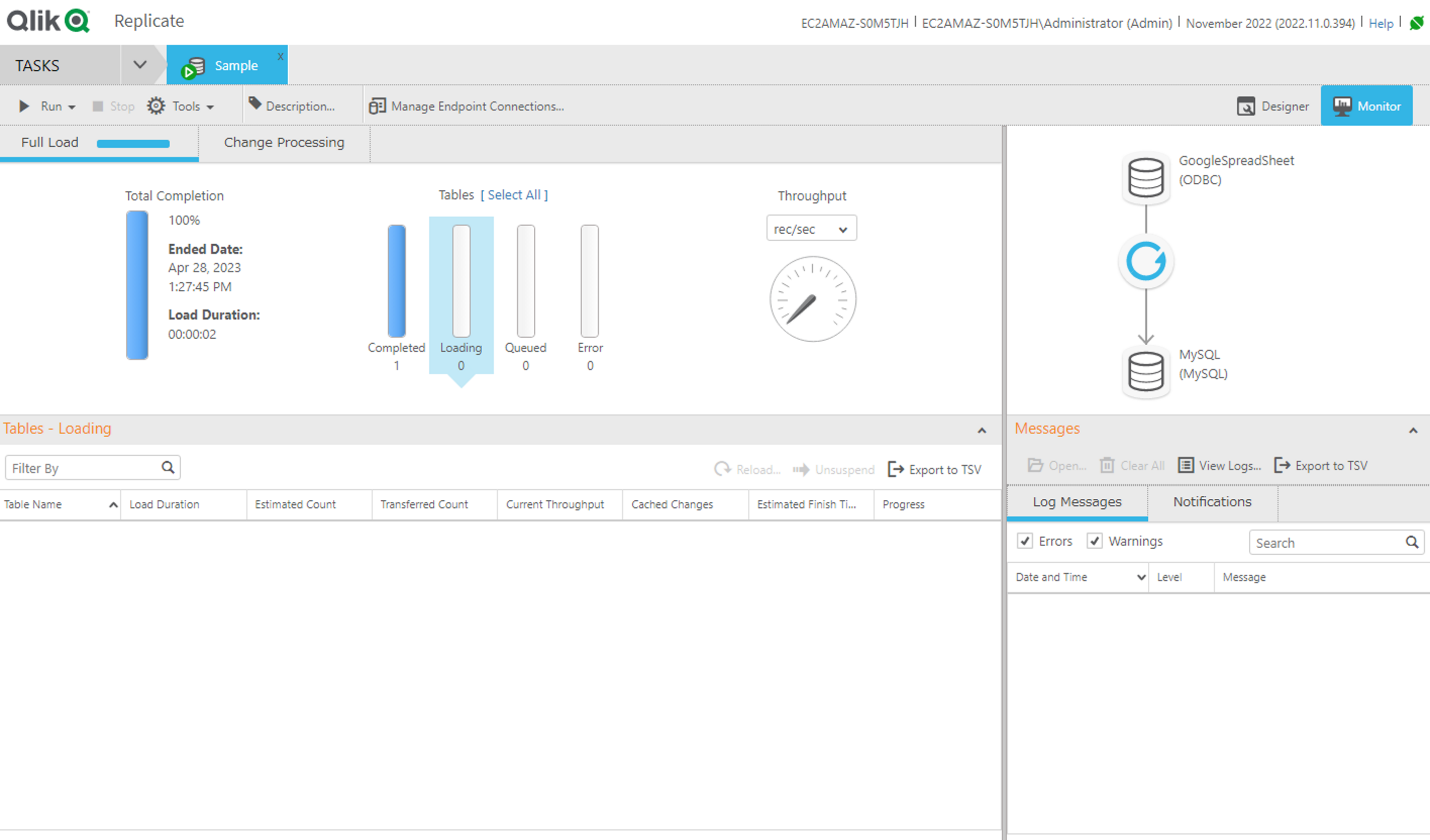
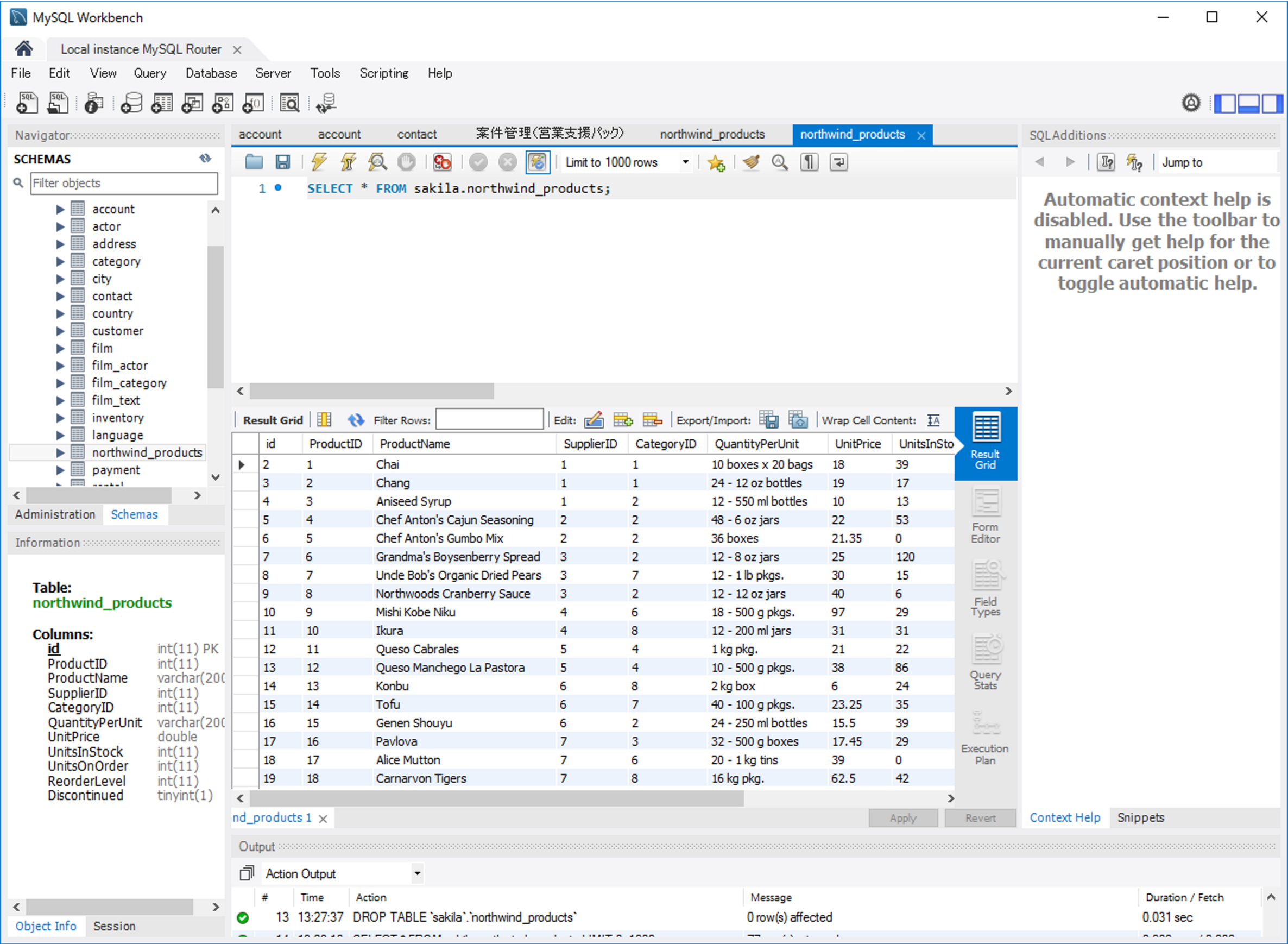
それでは作成したTask を実際に実行してみましょう。
このようにCData ODBC ドライバを利用することで、各種クラウドサービスをQlik Replicate の接続先として利用できるようになります。 CData ではKafka 以外にも270種類以上のデータソース向けにODBC Driver を提供しています。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
日本のユーザー向けにCData Sync は、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。