Bold BI でSpark ダッシュボードを作成
CData Connect Server を使用してSpark データの仮想MySQL データベースを作成し、Bold BI でカスタムダッシュボードを構築します。
加藤龍彦
デジタルマーケティング
最終更新日:2022-06-30
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Bold BI を使用することで、インタラクティブなBI ダッシュボードでビジュアライゼーションを作成、共有し、共同で作業することができます。CData Connect Server と組み合わせると、ビジュアライゼーションやダッシュボードなどのためにSpark データに経由でアクセスできます。この記事では、Bold BI でSpark の仮想データベースを作成し、Spark データからレポートを作成する方法を説明します。
CData Connect Server は、Spark に純粋なMySQL のインターフェースを提供し、ネイティブにサポートされているデータベースにデータを複製することなくBold BI のリアルタイムSpark データから簡単にレポートを作成できるようにします。ビジュアライゼーションを作成すると、Bold BI はデータを収集するためのSQL クエリを生成します。CData Connect Server は、最適化されたデータ処理を使用してサポートされているすべてのSQL 操作(フィルタ、JOIN など)をSpark に直接プッシュし、サーバーサイドの処理を利用して、要求されたSpark データを素早く返します。
Spark データの仮想MySQL データベースを作成
CData Connect Server は、簡単なポイントアンドクリックインターフェースを使用してAPI を生成します。
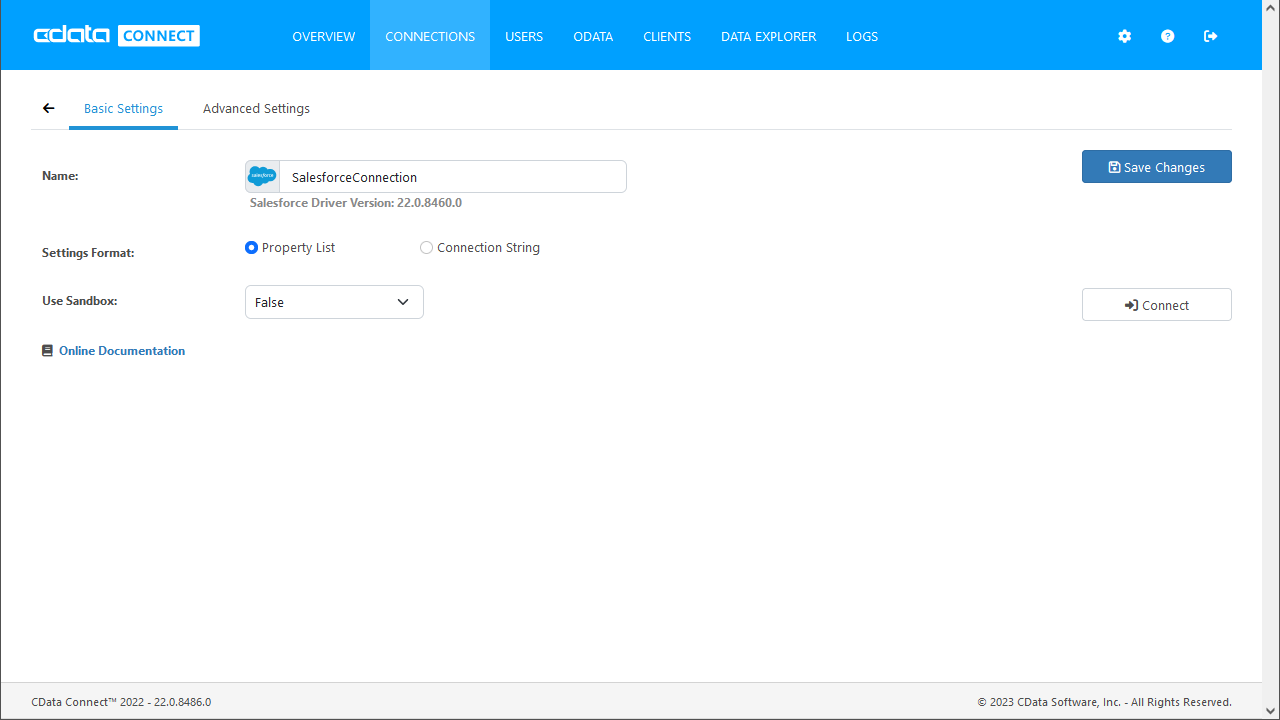
- Connect Server にログインし、「CONNECTIONS」をクリックします。
![データベースを追加]()
- [Available Data Sources]から[Spark]を選択します。
-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![Configuring a connection (Salesforce is shown).]()
- [ Test Database ]をクリックします。
- [Permission]->[ Add]とクリックし、適切な権限を持つ新しいユーザー(または既存のユーザー)を追加します。
仮想データベースが作成されたら、Bold BI からSpark に接続することができます。
Bold BI でリアルタイムSpark データをビジュアライズ
以下のステップでは、Bold BI からCData Connect Server に接続して新しいSpark データソースを作成し、データから簡単なビジュアライゼーションを構築する方法の概要を説明します。
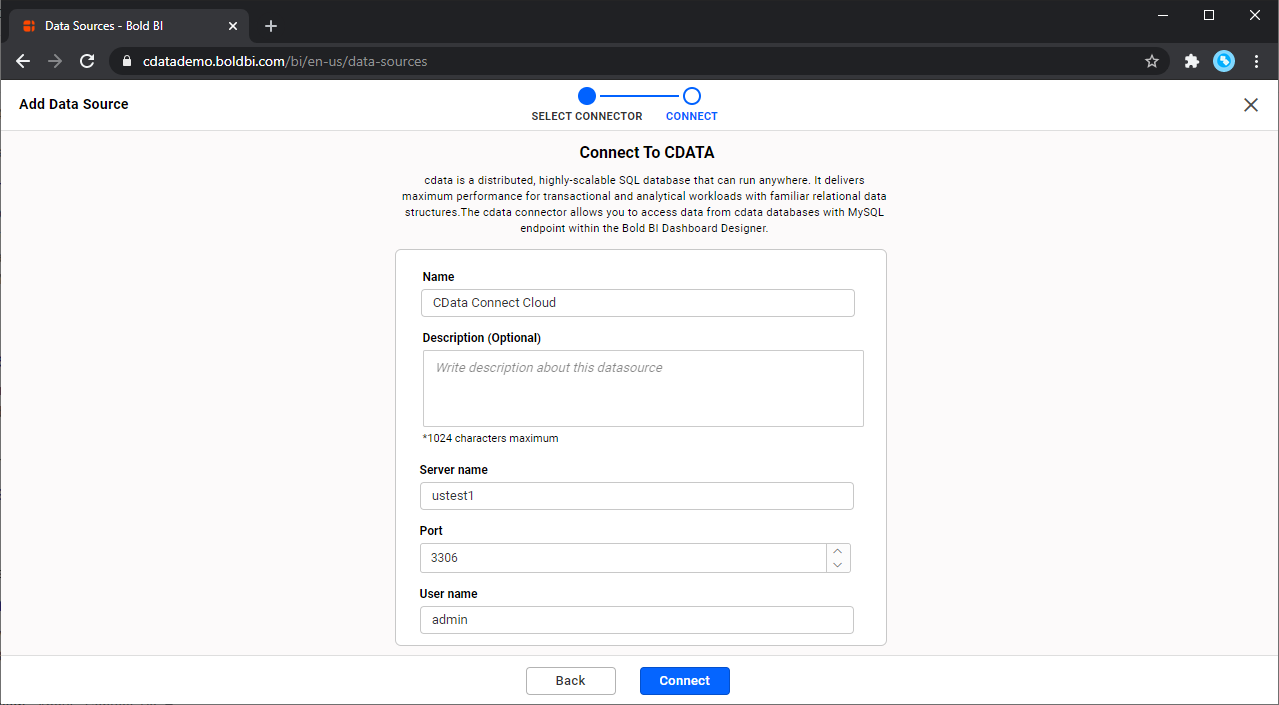
- Bold BI インスタンスにログインし、[data sources]タブをクリックしてMySQL コネクタを選択します。
![Create a new connection in Looker Studio]()
- 基本構成を選択し、接続プロパティを設定します。
- Name:接続に名前を付けます。
- Server name:Connect Server インスタンス(CONNECT_SERVER_URL)
- Port: 3306
- Username:Connect Server のユーザー名
- Password:Connect Server のパスワード
- Mode:[Live]を選択してSpark をオンデマンドでクエリするか、[Extract]を選択してデータをBold BI にロードします。
- Database:ドロップダウンメニューから作成したデータベースを選択します。(sparkdb)
- [Connect]をクリックします。
![Configure the Connection to CData Connect Server database]()
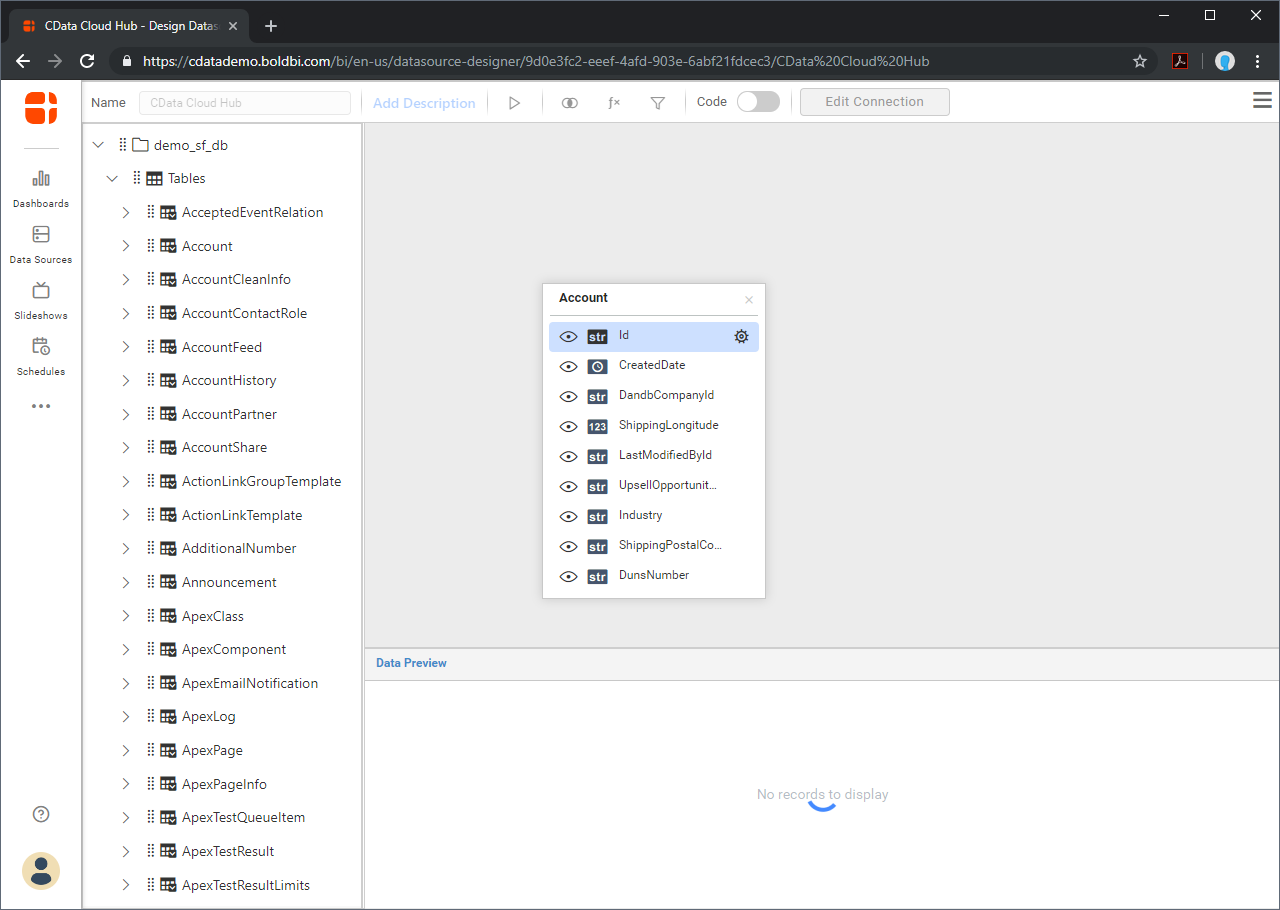
- ビジュアライズするテーブルを選択し、ワークスペースにドラッグします。
![Selecting a Table to visualize]()
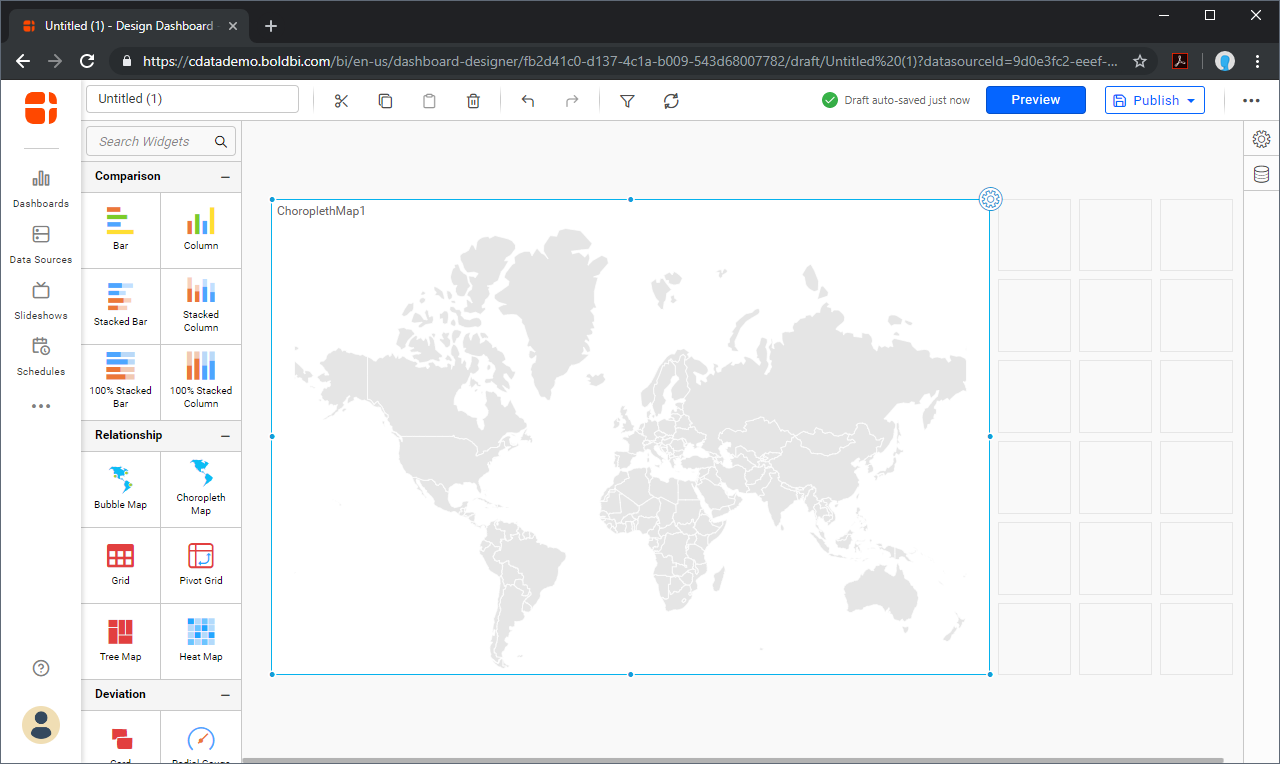
- ビジュアライゼーションのスタイルを選択してレポートに追加します。
![Selecting a visualization]()
- ビジュアライゼーションの歯車アイコンをクリックしてビジュアライゼーションプロパティを構成し、ビジュアライゼーションにカラムを割り当てます。
![Configuring the visualization in Bold BI]()
アプリケーションからSpark データへのSQL アクセス
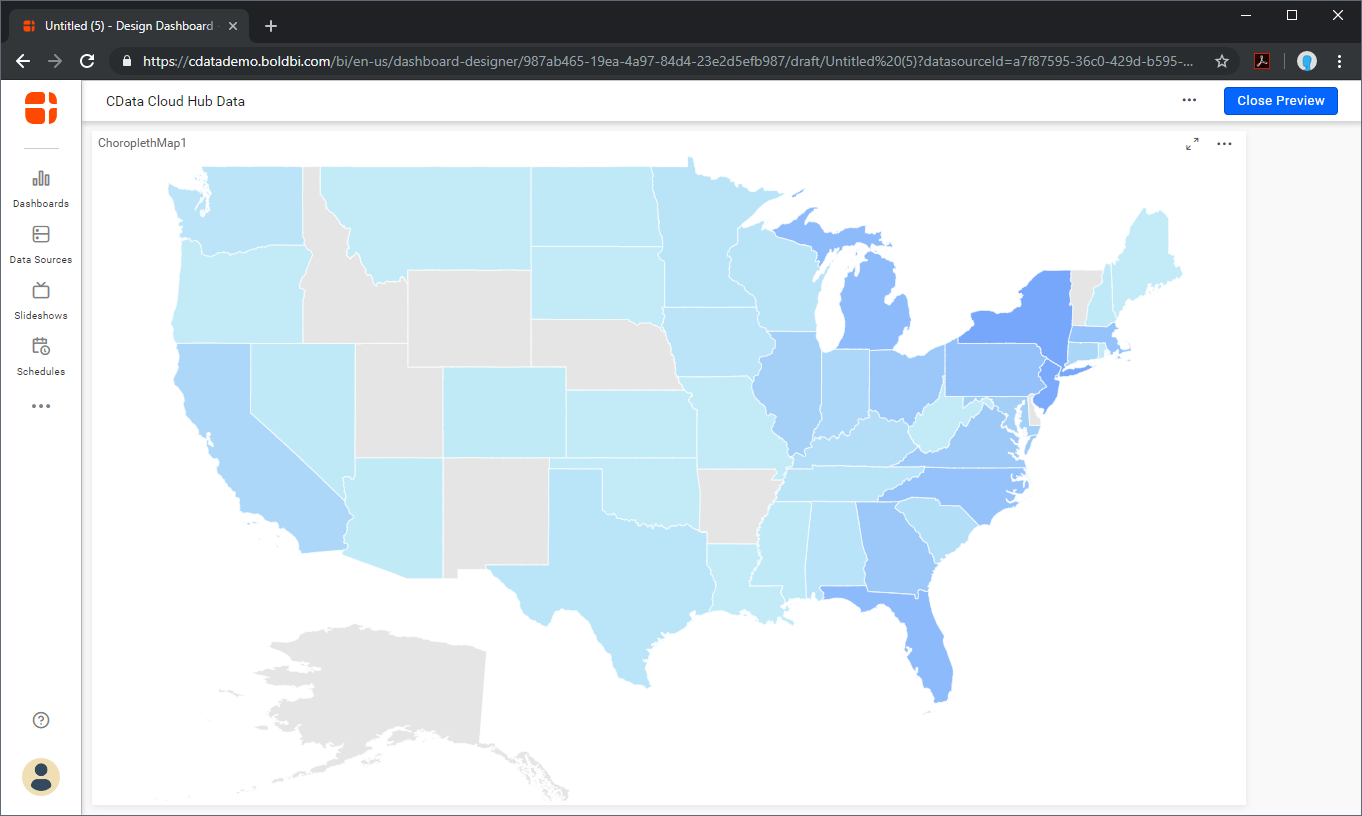
Bold BI ワークブックからリアルタイムSpark データへ直接接続ができるようになりました。これで、Spark を複製することなくより多くのデータソースや新しいビジュアライゼーション、レポートを作成することができます。
![Visualizing Spark データ in a Bold BI dashboard]()
アプリケーションから直接250+ SaaS 、Big Data 、NoSQL ソースへのSQL データアクセスを取得するには、CData Connect Server ページ を参照してください。