こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Amazon QuickSight ではクラウド上でインタラクティブなダッシュボードを作成できます。CData Connect Cloud と組み合わせると、ビジュアライゼーションやダッシュボード用にSpark データにクラウドベースでアクセスできます。この記事では、Connect Cloud でSpark に接続し、Amazon QuickSight でSpark データにアクセスしダッシュボードを構築する方法を説明します。
CData Connect Cloud とは?
CData Connect Cloud は、以下のような特徴を持ったクラウド型のリアルタイムデータ連携製品です。
- SaaS やクラウドデータベースを中心とする150種類以上のデータソース
- BI、アナリティクス、ETL、ローコードツールなど30種類以上のツールやアプリケーションから利用可能
- リアルタイムのデータ接続に対応。データの複製を作る必要はありません
- ノーコードでシンプルな設定
詳しくは、こちらの製品資料をご確認ください。
Connect Cloud アカウントの取得
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
Connect Cloud からSpark に接続する
CData Connect Cloud では、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
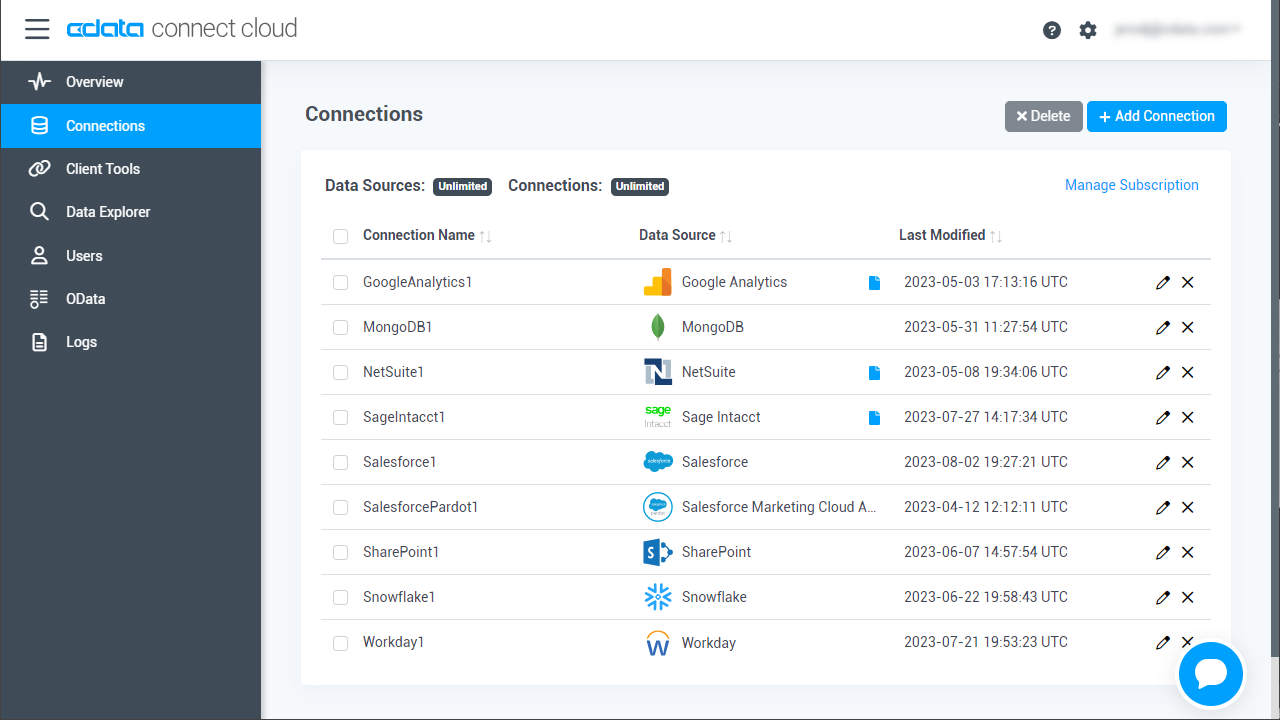
- Connect Cloud にログインし、 Add Connection をクリックします。
![Adding a Connection]()
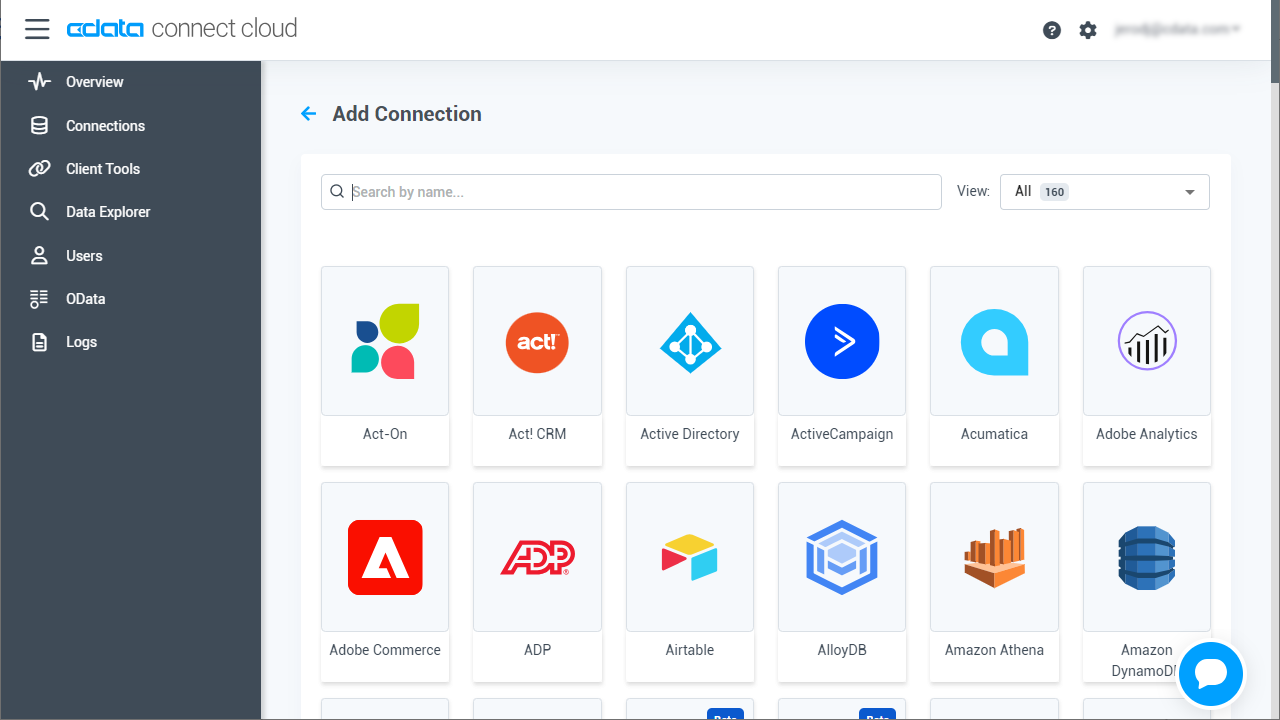
- Add Connection パネルから「Spark」を選択します。
![Selecting a data source]()
-
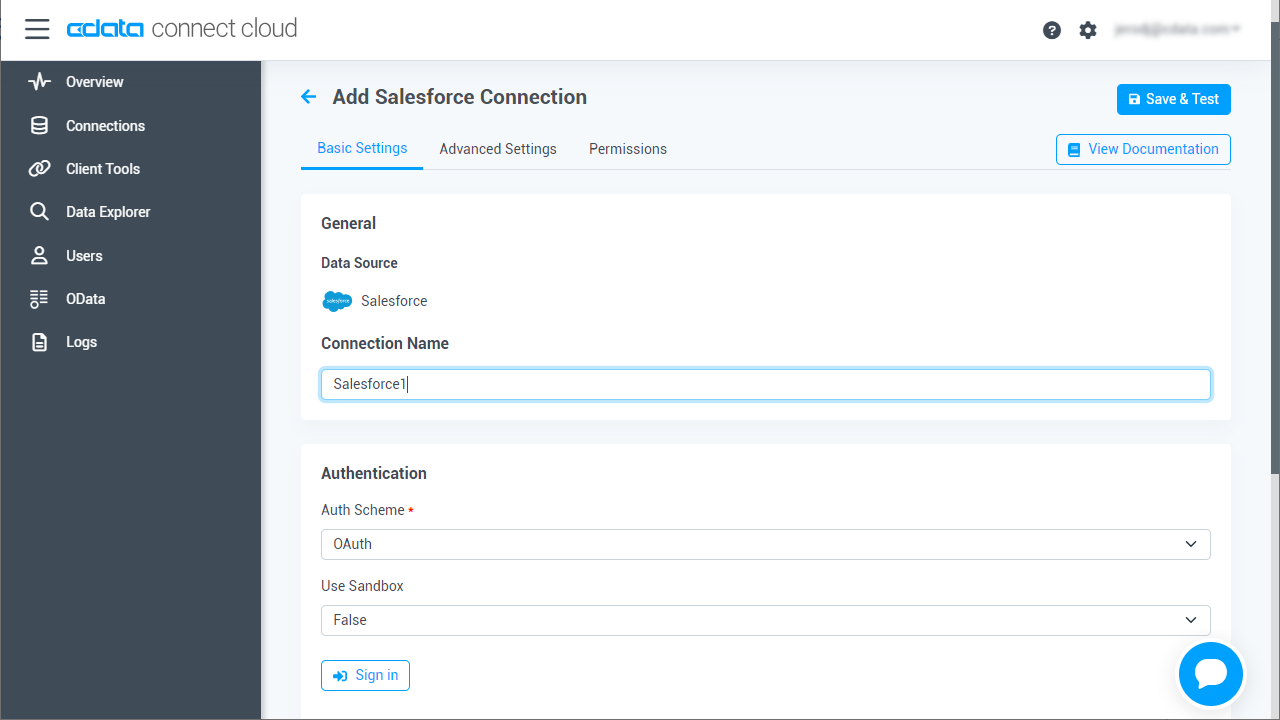
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![Configuring a connection (Salesforce is shown)]()
- Create & Test をクリックします。
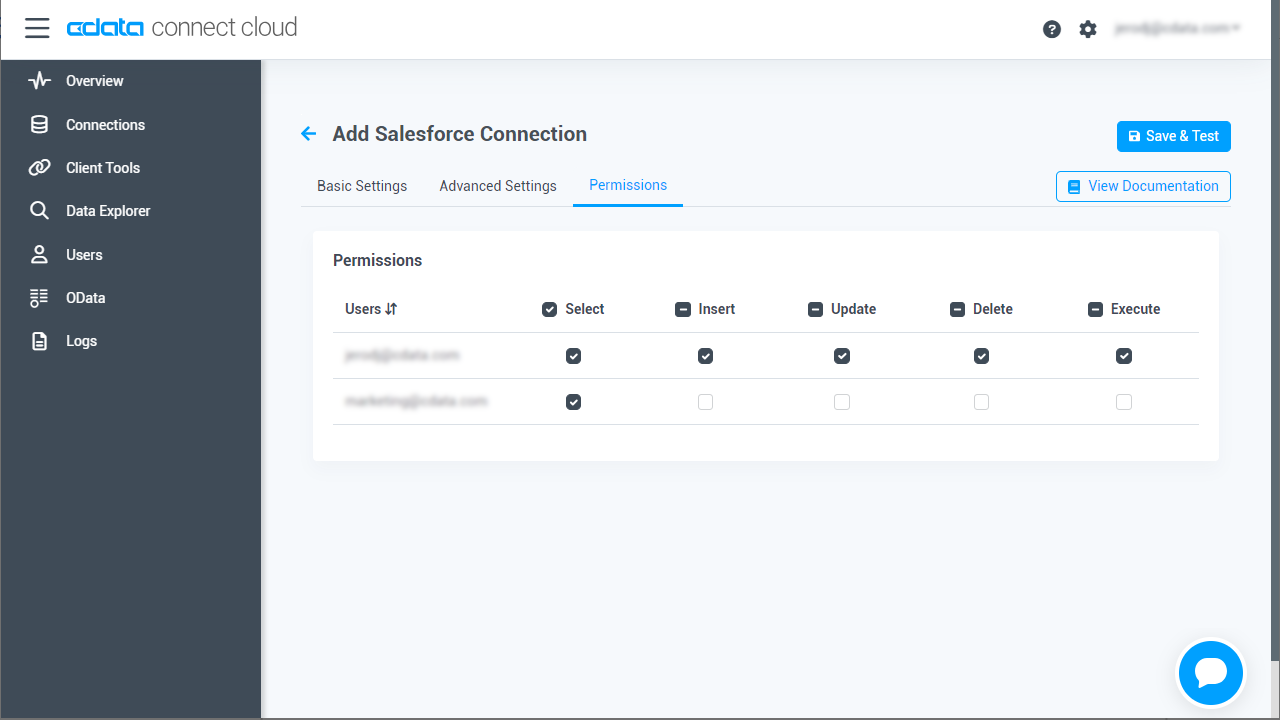
- Edit Spark Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。
![権限を更新]()
パーソナルアクセストークンの追加
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect Cloud アプリの右上にあるユーザー名をクリックし、User Profile をクリックします。
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
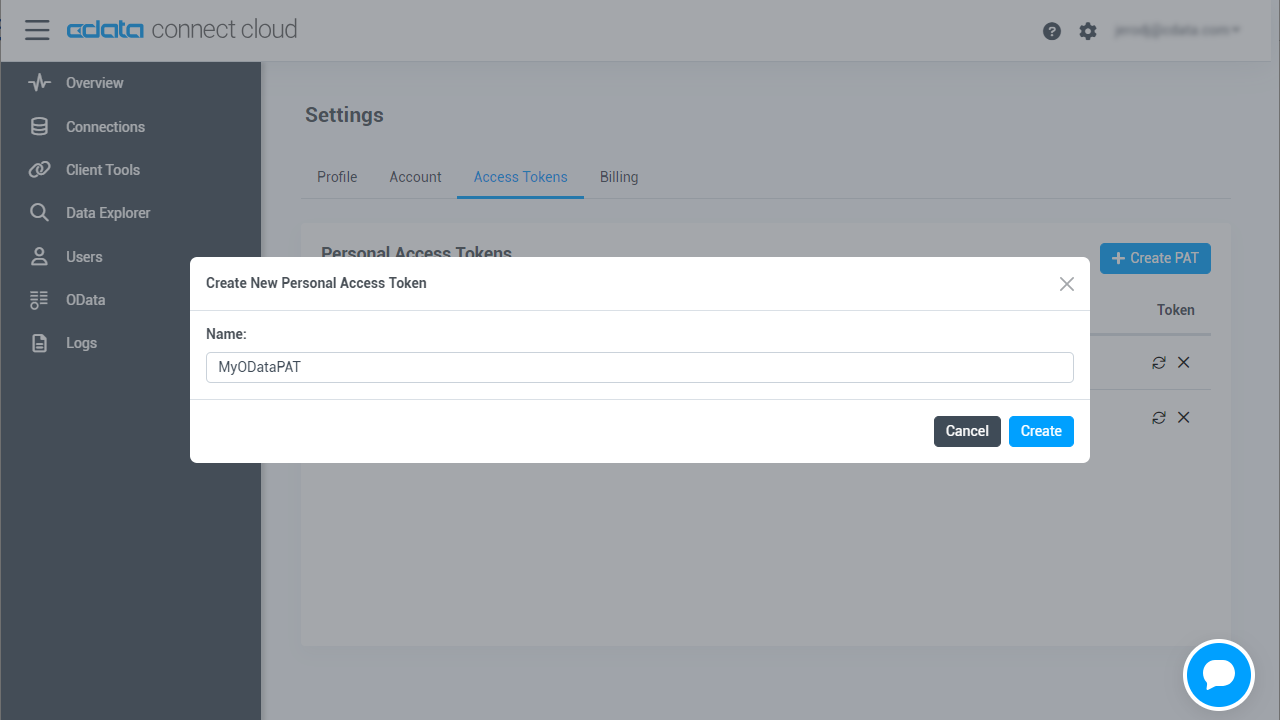
- PAT の名前を入力して Create をクリックします。
![Creating a new PAT]()
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
コネクションが構成されたら、Amazon QuickSight からSpark に接続できるようになります。
Spark データをSPICE にインポートしてインタラクティブなダッシュボードを作成する
以下のステップでは、Connect Cloud のSpark 接続をベースにした新しいデータセットの作成、データセットのSPICE へのインポート、およびデータからの簡単なビジュアライゼーションを構築する方法を説明します。
- Amazon QuickSight にログインし「データセット」をクリックします。
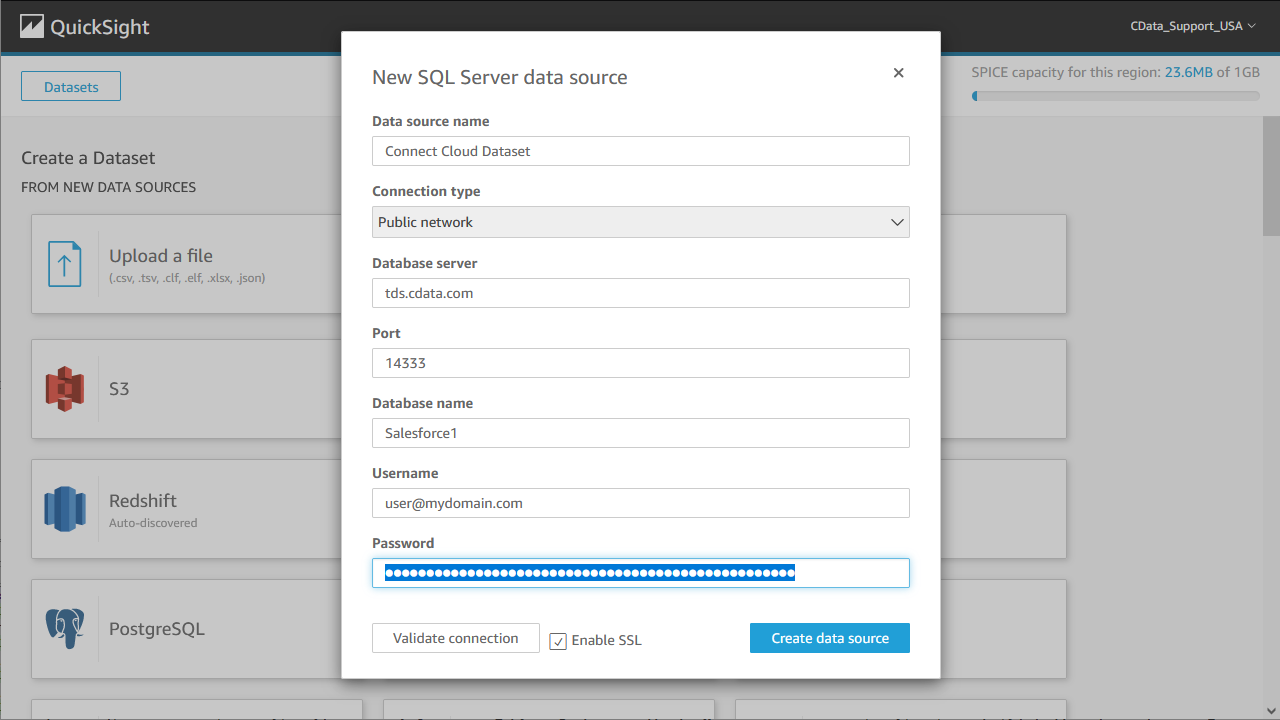
- 「新しいデータセット」をクリックし、データソースとしてSQL Server を選択しConnect Cloud のインスタンスへの接続を構成します。完了したら「データソースを作成」をクリックします。
![Connecting to Connect Cloud as a QuickSight data set.]()
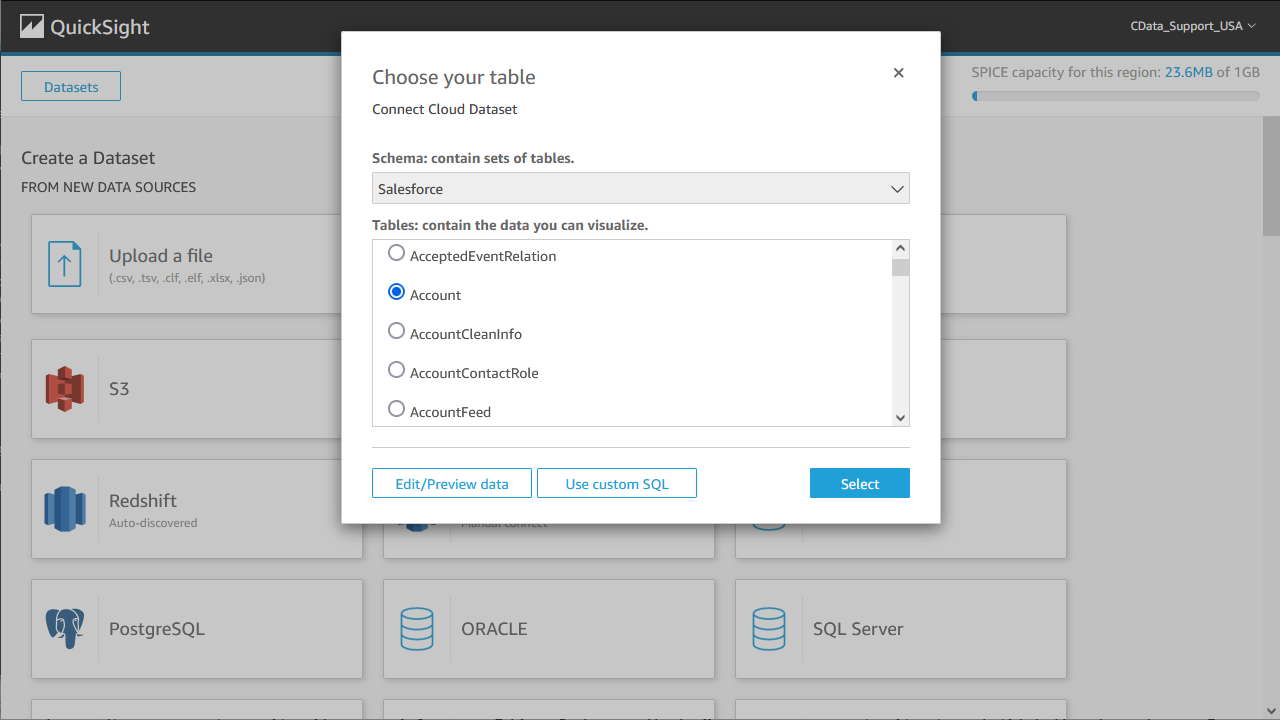
- ビジュアライズ化したいテーブルを選択するか、データのカスタムSQL クエリを発行します。
![Selecting a Table to visualize.]()
- 「データの編集 / プレビュー」をクリックしデータセットをカスタマイズします。
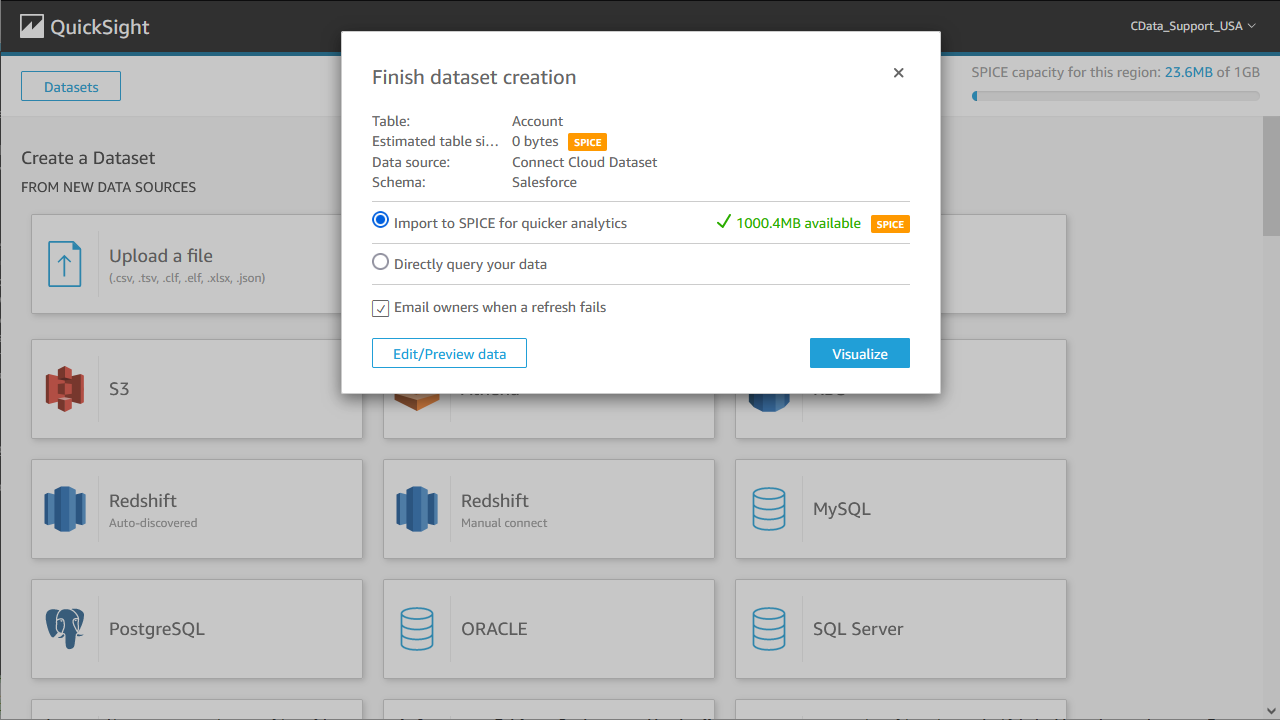
- 「迅速な分析のために SPICE へインポート」を選択し「視覚化する」をクリックします。
![Importing data to SPICE for quicker analytics.]()
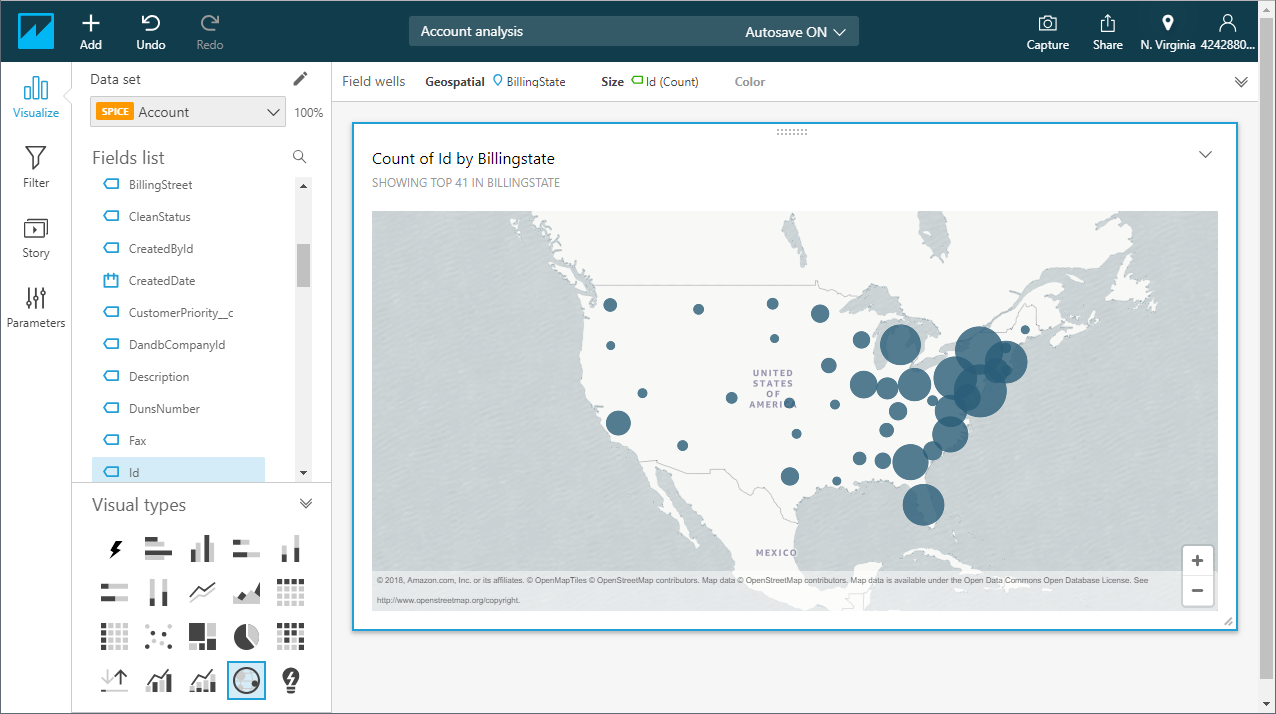
- ビジュアライズしたいフィールドとタイプを選択します。
![Visualizing data in QuickSight via Connect Cloud (Salesforce is shown).]()
SPICE データセットの更新をスケジュールする
QuickSight のユーザーはSPICE にインポートしたデータセットの更新をスケジュールし、分析されるデータが最新で更新されたものだけであることを確認できます。
- QuickSight のホームページへ移動します。
- 「データの管理」をクリックします。
- 更新したいデータセットを選択します。
- 「更新をスケジュール」をクリックします。
- 「作成」をクリックし、更新スケジュール(タイムゾーン、繰り返しの頻度、開始日)を設定し、「作成」をクリックします。
![Scheduling a refreshing of the data imported into SPICE.]()
クラウドアプリケーションからSpark データへのSQL アクセス
これで、Amazon QuickSigh ダッシュボードからSpark へ直接クラウドベースで接続できます。新しいビジュアライゼーションを作成したり、インタラクティブなダッシュボードを作成したりすることができます。Amazon QuickSight のようなクラウドアプリケーションで、100 を超えるSaaS、Big Data、NoSQL ソースのデータにライブアクセスする方法の詳細については、Connect Cloud ページを参照してください。