ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →





CData Arc 機能紹介 - Pre-Processing and Post-Processing Queries

こんにちは。CData Software Japan の色川です。
この記事では、CData Arc のデータソース系コネクタで利用できる「Pre-Processing and Post-Processing Queries」をご紹介します。
Pre-Processing and Post-Processing Queries の概要
Pre-Processing and Post-Processing Queries は、その名の通り、Select やUpsert など設定されたクエリアクションを実行する前ないし後に、追加のクエリを発行する事ができる機能です。
あるデータソースからデータを取得したり更新したりする前に(または後に)、任意の静的なクエリを発行する事ができる機能で、実行したいクエリの前処理や後処理が必要な場面で役に立つ機能です。
「Pre-Processing and Post-Processing Queries」は、SQL Server / Oracle / DB2 等の Database Connectors や、Application Connectors の内 Salesforce / NetSuite / Shopify 等のデータソース系コネクタ、CData Driers とシームレスに連携できる CData コネクタで利用することができます。
Pre-Processing and Post-Processing Queries の活用シーン
Pre-Processing and Post-Processing Queries の典型的な活用シーンの1つが、いわゆる「洗替的にデータを同期したいケース(連携先のデータを削除して、連携元のデータを丸ごと登録し直したいケース)」です。
Arc のデータソース系コネクタでは差分抽出の機構も備えていますが、差分の抽出・更新ではフィットしないケースもあるかと思います。
例えば、定期的に連携元から連携先にデータをコピーしたい場面があるとして、連携元のデータソースで物理的なレコード削除が発生するとき、発生したレコードの削除を連携先に反映したいと思っても(削除対象レコードを検知できる何らかの機構を持っていない場合は)削除されたレコードを取得する事が出来ず、差分連携(更新されたレコードだけ取得して連携するアプローチ)では反映する事ができません。
そう言った場合は、いわゆる連携元のデータで連携先のデータを丸ごと洗い替える形で実現を検討されるケースも多いと思います。クエリ処理としては「連携先の既存データをDelete(空に)」した後に「連携元から取得済のデータをInsert」するイメージです。この時、本来目的であるInsert クエリの前に、前処理としてDelete クエリを実行できるのが「Pre-Processing and Post-Processing Queries」です。
他にも「データを取得した後に任意のストアドプロシージャをCall したいとき」など、この機能の利用シーンは様々ですが、この記事では最も典型的な「洗替的なデータ連携のフロー」を例にして設定イメージをご紹介します。
Pre-Processing and Post-Processing Queries の設定手順と制約
Pre-Processing and Post-Processing Queries は、コードモードで記述する事で利用することができます。デザインモードで設定した(コネクタが生成する)クエリを、コードモードで変更して設定します。
Pre-Processing and Post-Processing Queries はUpsert アクション、Select アクション、何れのマッピングでも利用することができますが、実行できるのは静的なクエリに限られます。インプットファイルの要素を利用した動的なクエリを発行することはできません。
Upsert アクションでの利用イメージ
例えば「Names テーブルへのUpsert クエリを実行する前に、FlushTemp ストアドプロシージャを実行したい」場合、Pre-Processing Query として以下のように記述します。
<Items> <runFirst table="updateTable" insertQuery="EXEC [dbo].[FlushTemp]" requireInput="false" /> <Names table="`dbo`.`Names`" action="upsert"> <ID key="true" /> <Name /> … </Names> </Items>
この例で「runFirst」としている部分がPre-Processing Query を表す要素です。「runFirst」部分には任意の名称を利用する事ができます。要素は以下のような属性で構成されます。
| requireInput | false(インプットファイルの要素を求めずにクエリ発行することを指定します) |
| insertQuery | Upsert クエリの前または後に実行するクエリを記述します。 |
| table | Upsert クエリの前または後に実行するクエリで対象とするテーブル名を設定します。他のクエリで指定しているtable と明示的に区別する場合に指定します。この属性はオプションです。 |
Upsert アクションでのPre-Processing and Post-Processing Queries については、こちらのヘルプトピックも参考にしてください。
Select アクションでの利用イメージ
例えば「Names テーブルへSelect クエリを実行する前に、prepTable ストアドプロシージャを実行したい」場合、Pre-Processing Query として以下のように記述します。
<Items> <runFirst table="selectTable" selectQuery="EXEC [dbo].[prepTable]" outputResult="false" /> <Names table="`dbo`.`Names`" action="select"> <ID key="true" /> <Name /> … </Names> </Items>
この例で「runFirst」としている部分がPre-Processing Query を表す要素です。「runFirst」部分には任意の名称を利用する事ができます。要素は以下のような属性で構成されます。
| outputResult | false(クエリの結果をアウトプットファイルに出力しないことを指定します) |
| selectQuery | Select クエリの前または後に実行するクエリを記述します。 |
| table | Select クエリの前または後に実行するクエリで対象とするテーブル名を設定します。他のクエリで指定しているtable と明示的に区別する場合に指定します。この属性はオプションです。 |
Select アクションでのPre-Processing and Post-Processing Queries については、こちらのヘルプトピックも参考にしてください。
Pre-Processing and Post-Processing Queries の設定例(洗替え的な連携フローを構成する)
こちらはMySQL のテーブルから取得したデータを、SQL Server のテーブルへ連携するときの典型的なフローイメージです。
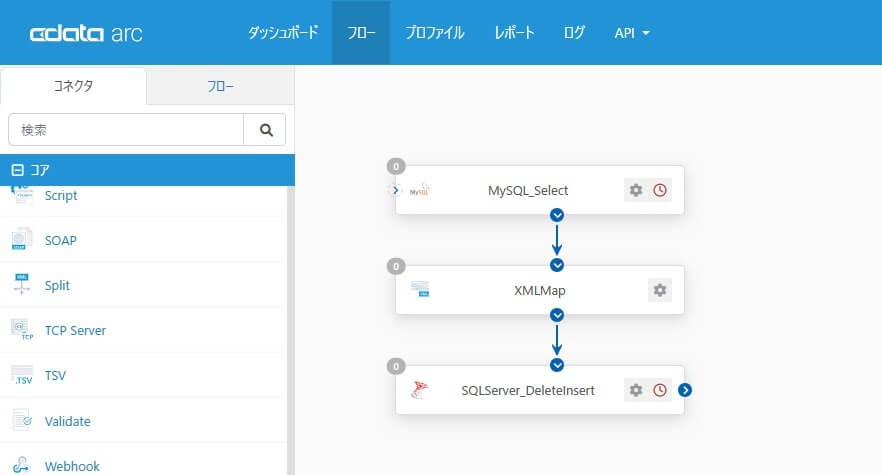
Arc での基本的なフローの作り方については、こちらの記事 などを参考にしてください。
ここでは洗替え的な連携フローとして構成するときに必要な設定上のポイントを紹介していきます。
連携元からの取得をバッチ出力で構成する
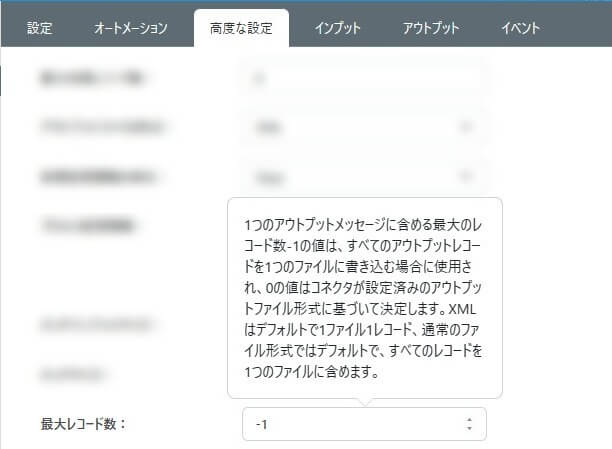
Arc のSelect アクションではデフォルトで1レコード1メッセージファイルとして出力されます。デフォルトのままでは、連携先側で構成するPre-Processing and Post-Processing Queries(delete クエリ)がメッセージファイルごとに実行されるため適切ではありません。こういったシナリオでは「最大レコード数」を「-1」として、連携したいデータを1メッセージファイルとしてまとめて出力するように構成します。
この例では、MySQL コネクタの「高度な設定」から「最大レコード数」を「-1」に設定します。
連携先への更新(Pre-Processing and Post-Processing Queries を利用したDelete/Insert)
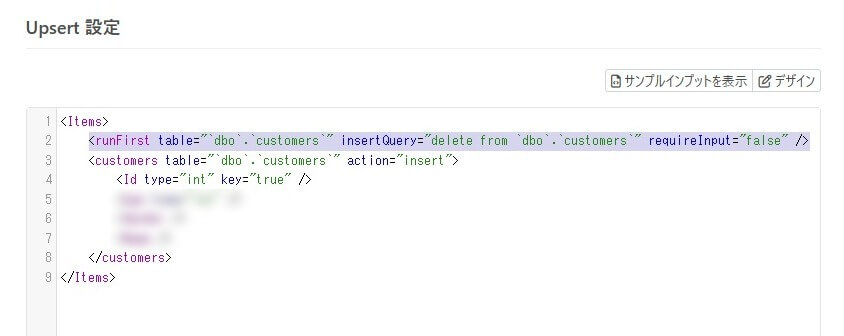
この例では、SQL Server のcustomers テーブルに連携するときに、customers テーブルの全件をdelete してから、連携データをinsert するように構成します。設定ステップを少し詳しくご紹介します。
デザインモードで、customers テーブルを選択して、Upsert アクションのクエリを自動生成します。
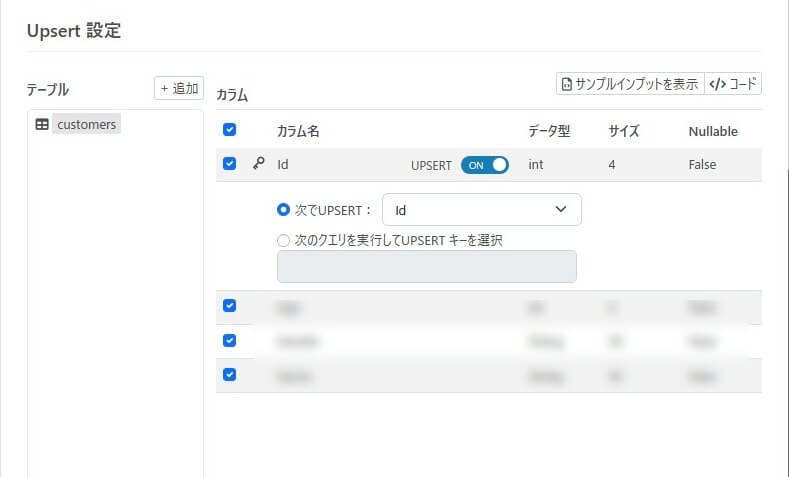
この例では、Upsert クエリの前にdelete して全件クリアするクエリをPre-Processing Query として設定しますので、Upsert クエリで実行されるクエリは全件Insert となる想定です。そのため、より効率よく動作するようにUpsert をOff で構成しておきます。
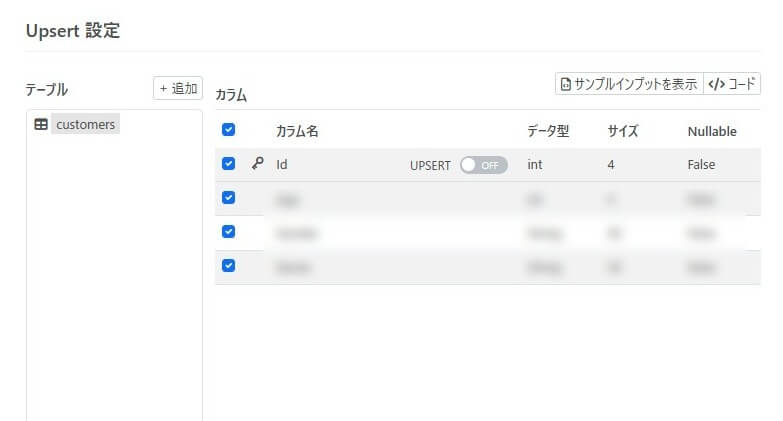
Pre-Processing and Post-Processing Queries を構成するために、コードモードで開きます。
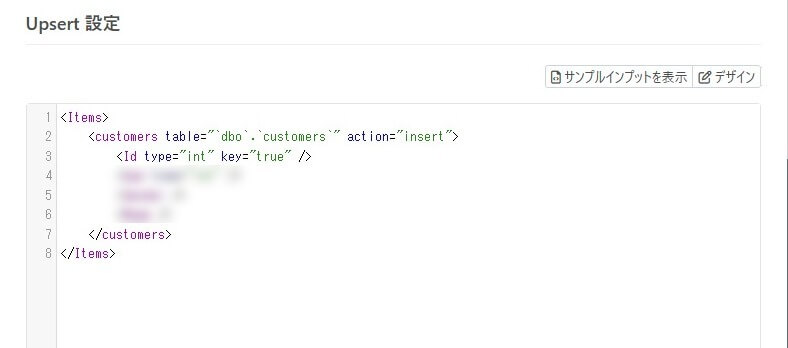
コードモードで下記のように設定します。これで「runFirst 属性に構成したPre-Processing Query(削除クエリ)が実行された後、インプットファイルに含まれる各customers レコードがマッピングされInsert されていく」と言う仕組みです。
Pre-Processing and Post-Processing Queries の関連記事
応用的な使い方としては、こちらの記事 のように、Salesforce のUpsert API を利用したバッチ処理(複数レコードを一括Upsert)なども、このPre-Processing and Post-Processing Queries の機構を活用することで実現することができます。
まとめ
この記事では、CData Arc のデータソース系コネクタで利用できる「Pre-Processing and Post-Processing Queries」をご紹介しました。
この記事でご紹介した洗替え的にデータを連携したい場合(既存レコードをクリアしてから登録したい場合)などは典型的な活用例ですが、Select やUpsert のクエリアクションの前に、任意のクエリを実行したいケースは意外と多いかも知れません。そう言ったケースでは「Pre-Processing and Post-Processing Queries」を活用することで、単一のコネクタの中で、シンプルに実現することができます。
CData Arc はシンプルで拡張性の高いコアフレームワークに、豊富なMFT・EDI・エンタープライズコネクタを備えたパワフルな製品です。CData Drivers との組み合わせで250を超えるアプリケーションへの連携を実現できます。必要な連携を低価格からはじめられる事も大きな特長です。
皆さんのつなぎたいシナリオでぜひ CData Arc を試してみてください。
製品を試していただく中で何かご不明な点があれば、テクニカルサポートへお気軽にお問い合わせください。
この記事では CData Arc™ 2023 - 23.0.8517.0 を利用しています。