ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →






SQL Server のレプリケーションを徹底解説:基礎知識から設定方法まで

企業のデータ管理において、データベース間のデータ同期はディザスタリカバリ(DR)、バックアップなどの面で重要な課題です。特に、複数のシステム間でデータを同期し、一貫性を保つことは容易ではありません。SQL Server のレプリケーション機能は、こうした課題を解決する機能です。
本記事では、SQL Serverレプリケーションの基本概念から、その種類、具体的な設定方法まで詳しく解説します。加えて、レプリケーションを簡単に自動化できるツール「CData Sync」の使い方もご紹介。SQL Server のデータ同期でお悩みの方に参考になればうれしいです。
SQL Server のレプリケーションとは?
SQL Server のレプリケーションとは、あるデータベースから別のデータベースにデータやデータベースオブジェクトをコピーして配布し、それらのデータベース間でデータを同期してデータの整合性と一貫性を維持するプロセスです。これはMicrosoft SQL Server の中心的な機能であり、スケーラビリティ、高可用性、レポート作成など、さまざまな目的のためにデータベースのコピーを複数作成して維持することができます。
Microsoft SSMS(SQL Server Management Studio)はSQL Server のデータベースをレプリケートするための便利なツールですが、できることは限られます。SQL Server 以外のデータベースをレプリケートしたい、ノーコードで手軽に設定を完了したい、という方には、データベースレプリケーションを簡単に実現できるETL ツールのCData Syncがオススメです。
この記事では、SQL Server レプリケーションに関わる主要なコンポーネント、レプリケーションの4つの手法、設定手順を解説します。
SQL Server レプリケーションの基礎知識
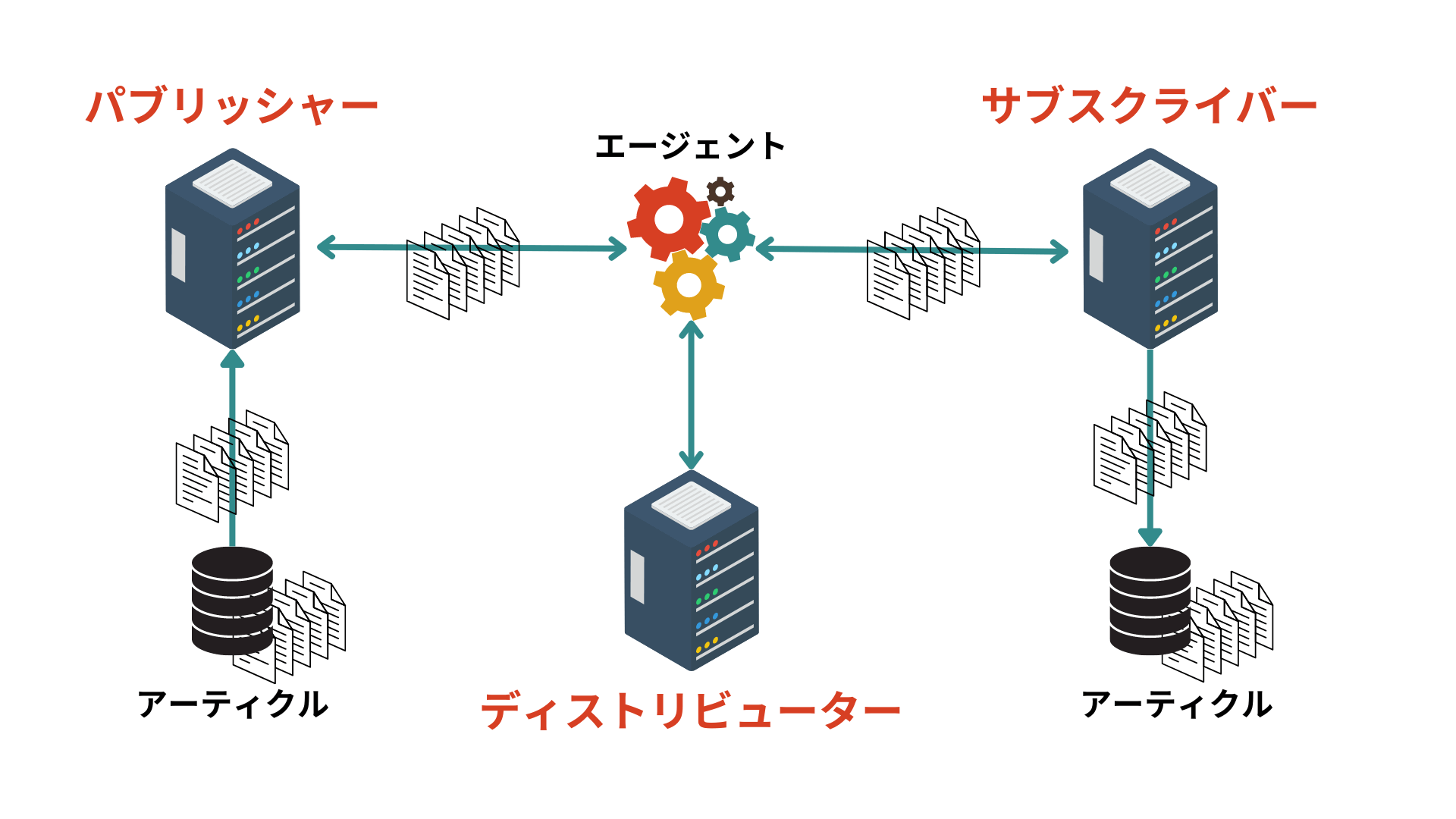
レプリケーションのプロセスはシンプルで、3つの役割を持つSQL Server インスタンスが関わってきます。英語の名称は、出版業界のアナロジーがベースになっているようです。
- パブリッシャー:ソースとなるデータを保持し、データの変更内容を流通を担うディストリビューターに渡す。
- ディストリビューター:パブリッシャーからスナップショットやトランザクションログなど、データの変更を受け取って格納し、サブスクライバーに送る。
- サブスクライバー:ディストリビューターからデータを受け取って書き込む先。
SQL Server のレプリケーションに欠かせないその他のコンポーネントとして、以下があります。
- アーティクル:SQL Server の基本単位。ビュー、テーブル、ストアドプロシージャはすべてアーティクルに含まれます。フィルタオプションを使用すると、アーティクルの列・行に含む項目を制限でき、制限のカスタマイズによって1つのオブジェクトに複数のアーティクルを作成することができます。
- パブリケーション:アーティクルと、それらをレプリケートするために必要な関連情報の論理的な集合。パブリケーションによりアーティクルのプロパティを上位レベルで定義し設定できるため、1つのパブリケーションが含むすべてのアーティクルがプロパティを継承します。
- パブリケーションデータベース:SQL Server レプリケーションでレプリケート元となるデータを格納するデータベースインスタンス。パブリッシャーには複数のパブリケーションを含めることができ、それぞれがレプリケートするオブジェクトと、データの論理的に関連する集合を定義します。
- ディストリビューションデータベース:パブリッシャーとサブスクライバーの仲介をするサーバー。アーティクルの詳細、データ、レプリケーションのメタデータを保管し、ディストリビューションのプロセスを管理します。
- サブスクライバー:レプリケートされたデータを受信するサーバー。SQL Server のレプリケーションデータをパブリケーションから取得します。サブスクライバーは、1つ以上のパブリケーションおよびパブリッシャーからデータを受信できます。
- サブスクリプション:特定のサブスクライバーがパブリケーションのコピーを要求する操作。
- サブスクリプションデータベース:データをレプリケートする先のデータベース。
- エージェント:リレーショナルデータベース管理システムのバックグラウンドサービスとして動作するSQL Server コンポーネント。エージェントを使用すると、SQL Server のバックアップやレプリケーションなどのジョブ実行をスケジューリングできます。エージェントには5つのタイプがあり、スナップショットエージェント、ログリーダー エージェント、ディストリビューション エージェント、マージ エージェント、キューリーダー エージェントです。
レプリケーションの主な構成要素間の関係を図示すると、以下のようになります。
SQL Server レプリケーションの種類
SQL Server で利用可能なレプリケーションには4種類あり、それぞれ目的が異なります。
スナップショットレプリケーション
データのある時点でのコピーがパブリッシャー(データソース)から取得され、サブスクライバー(同期先)に反映されます。毎回データをすべてコピーするため、スナップショットは小規模から中規模のデータベースや、データの変更頻度が低い場合に適しています。
トランザクションレプリケーション
トランザクションレプリケーションでは、トランザクションログをもとにレプリケーションを行います。トランザクションとは、DB に対して発行された追加、更新、削除といったSQL クエリのログを指します。
トランザクションレプリケーションを使えば、パブリッシャーからサブスクライバーへの個々のトランザクションをニアリアルタイムでキャプチャし、レプリケートできます。
スケーラビリティや可用性の向上、データウェアハウスへの統合やレポーティング、複数ソースからのデータ統合、バッチ処理のオフロードなど、高いスループットを必要とするシナリオに最適です。トランザクション レプリケーションは、データが頻繁に変更される大規模環境に適しています。
ピアツーピアレプリケーション
ピアツーピア レプリケーションは、パブリッシャーサーバーが同時に複数のサブスクライバーサーバーにデータをレプリケートするタイプのレプリケーションです。
異なるサーバーインスタンス(ノードとも呼ばれる)間でデータのコピーを保持することで、データの可用性とスケーラビリティを強化します。1 つの集中型データセンターが他のデータセンターのデータを管理します。ピアツーピア レプリケーションは、世界中で複数のデータセンターを保持しており、それらを連携したい、という場合に適しています。
マージレプリケーション
マージレプリケーションでは、初回にパブリッシャーからサブスクライバーにスナップショットを同期した後、パブリッシャー・サブスクライバーDB の変更を記録しておきます。そして、それぞれのDB の変更をサブスクライバーがネットワークに接続した際に統合(マージ)して、サブスクライバー側のデータを更新します。
データ同期の方法は継続的に行うこともできますし、スケジュール実行、または手動で同期することも可能です。この方法を使う場合データ同期の際競合が発生するので、競合解決の方法を設定しておく必要があります。マージレ プリケーションは、更新が複数のサーバーで発生し、同期する必要があるシナリオに適しています。
SQL Server レプリケーションの設定
レプリケーションの設定には、パブリケーションの構成、アーティクルの定義、サブスクリプションの作成、レプリケーションプロセスの監視が必要です。データベースのサイズ、データ変更の頻度、特定のユースケースの要件といった要素に応じて、適切なレプリケーション手法を選択することが重要です。
レプリケーションは強力な機能である一方、複雑な面もあります。レプリケーションの実装と運用を成功させるには、適切な計画と保守が不可欠です。
それでは、SQL Server のレプリケーションを行うための基本的な設定を実行してみましょう。
環境を準備する
- レプリケーションに必要な権限が設定されていることを確認します。
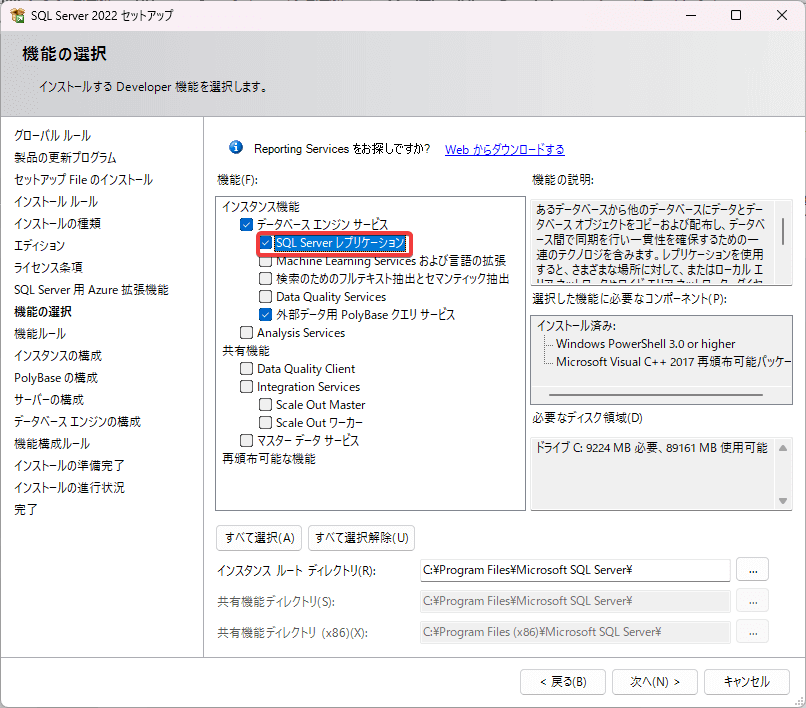
- 必要なコンポーネントがすべての利用するサーバーにインストールされていることを確認します。レプリケーションを利用するには、SQL Server のセットアップで「SQL Server レプリケーション」を選択してインストールしておきましょう。
ディストリビューションを作成する
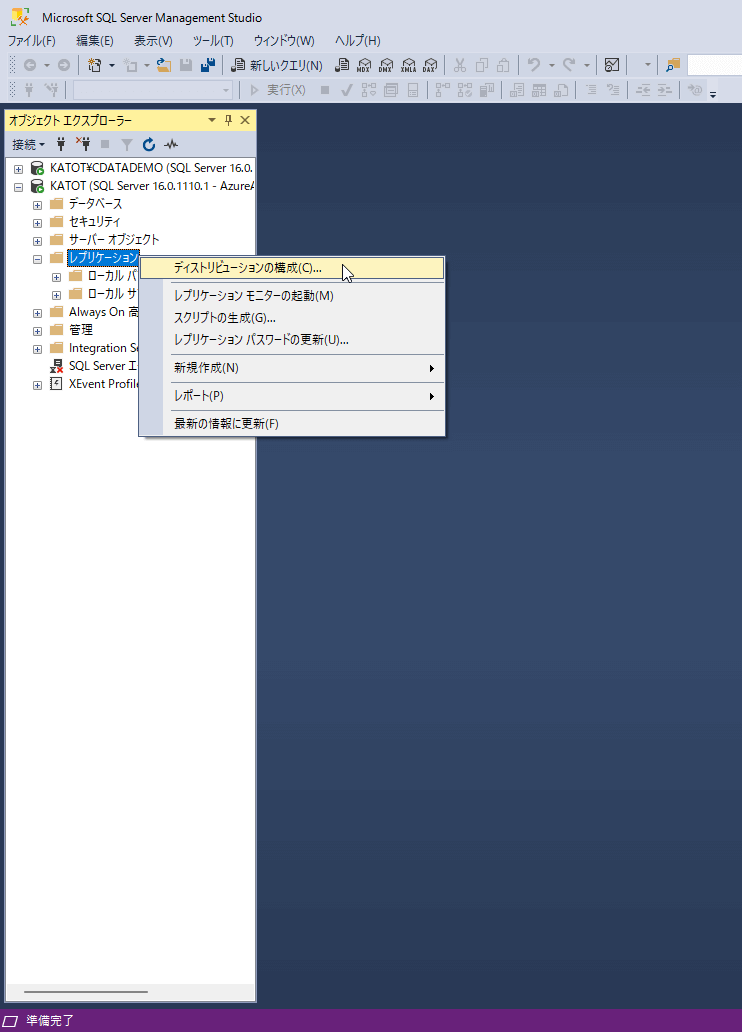
- ディストリビューションを作成するには、まずSQL Server Management Service(SSMS)を起動して、「レプリケーション」オブジェクトを右クリック → 「ディストリビューションの構成」をクリックします。
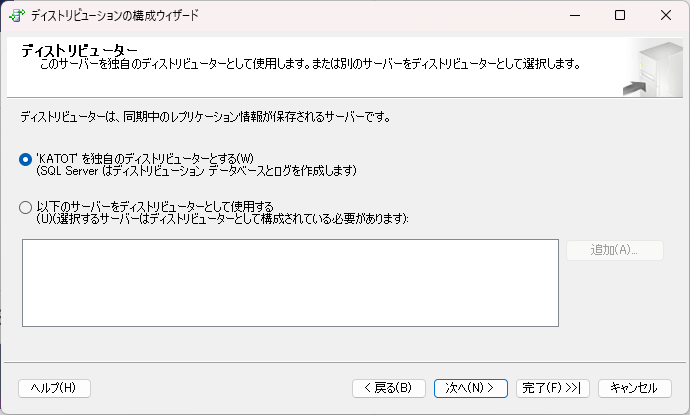
- 構成ウィザードが表示されるので、まずはディストリビューターを指定して、エージェントの起動を設定します。
- ディストリビューション名やパスを指定します。
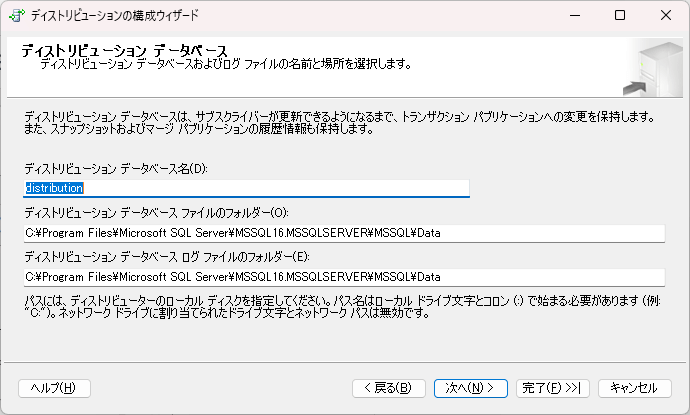
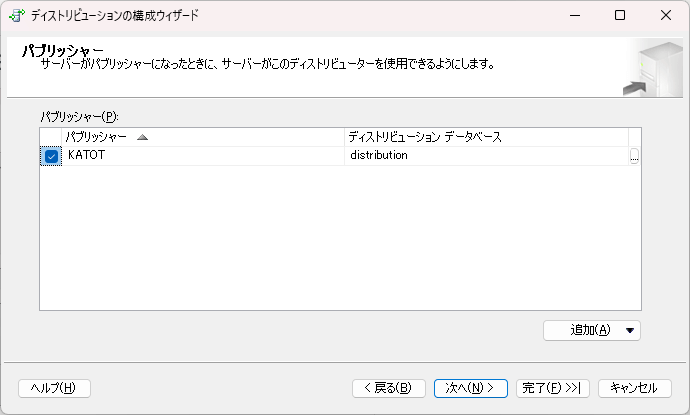
- ディストリビューターにアクセスできるパブリッシャーを指定します。
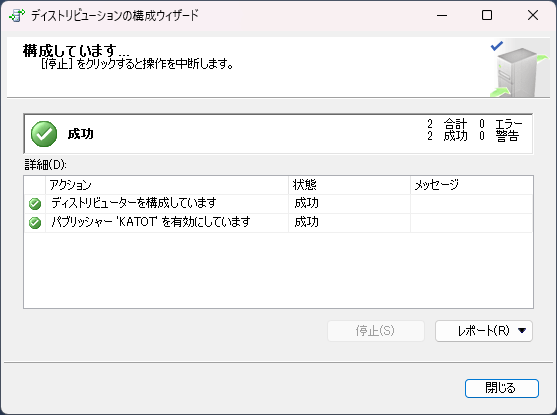
- 完了すると、成功を示すウィンドウが表示されます。
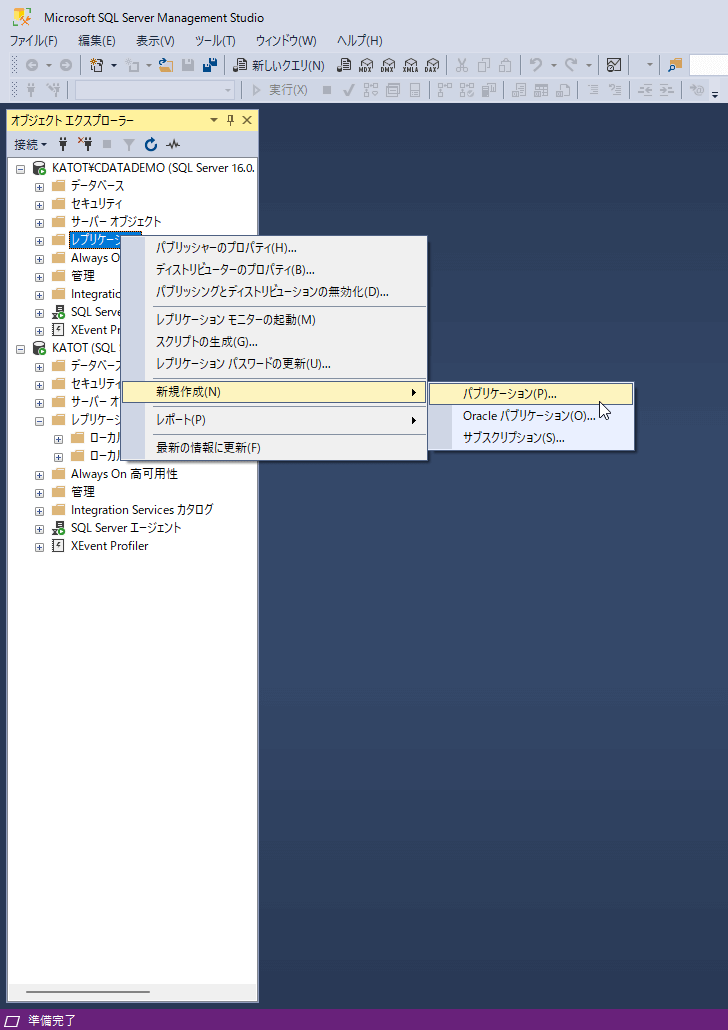
パブリケーションを作成する
次に、レプリケートするデータベースのアーティクル (テーブル、ビュー、ストアドプロシージャ)を設定していきます。パブリケーションを作成するには、レプリケーションオブジェクトを右クリックして表示される「新規作成」から「パブリケーション」をクリックします。
- まず、パブリケーションに使うデータベースを指定します。
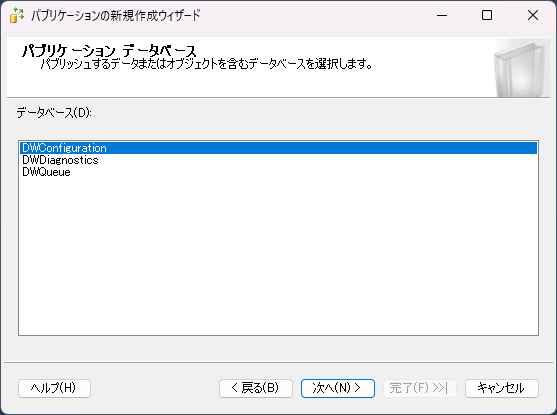
- パブリケーションの種類を指定します。今回はシンプルにスナップショットパブリケーションで設定します。
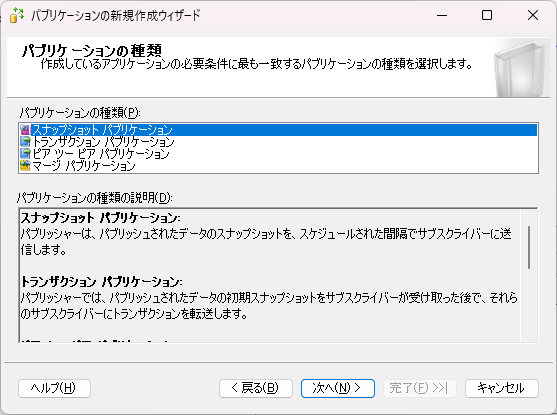
- パブリッシュするアーティクルを選択します。次の画面で必要に応じてフィルタを設定してください。
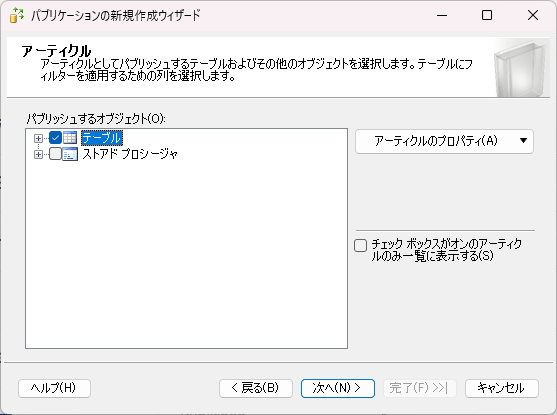
- その後エージェントの設定やパブリケーション名を指定して、「完了」をクリックします。成功を示すウィンドウが表示されればOKです。
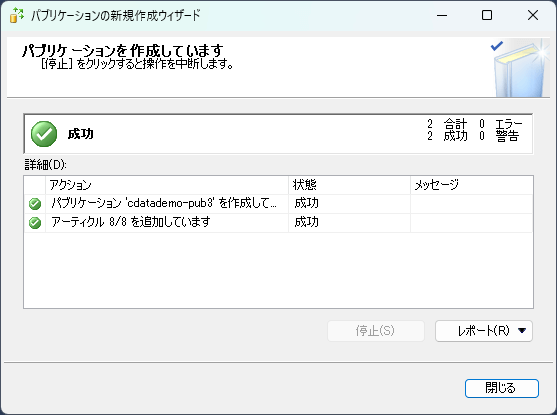
サブスクライバーを設定する
レプリケートされたデータを受信するサブスクライバー(同期先サーバー)を設定していきます。
- レプリケートされたデータを受信するサブスクライバー(同期先サーバー)を設定していきます。
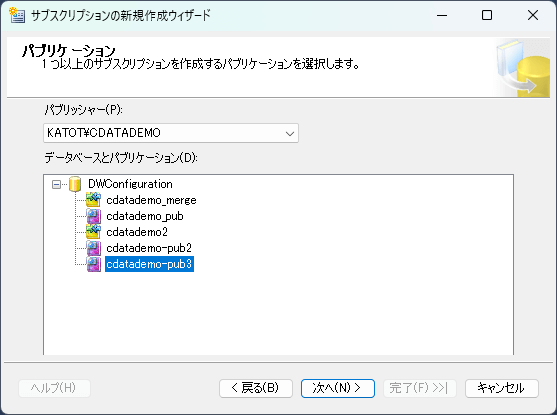
- ディストリビューションエージェントの場所を指定します。今回は、先ほど作成したディストリビューターを使用します。その他に、ディストリビューターを介さずサブスクライバー側で同期を管理することもできます。
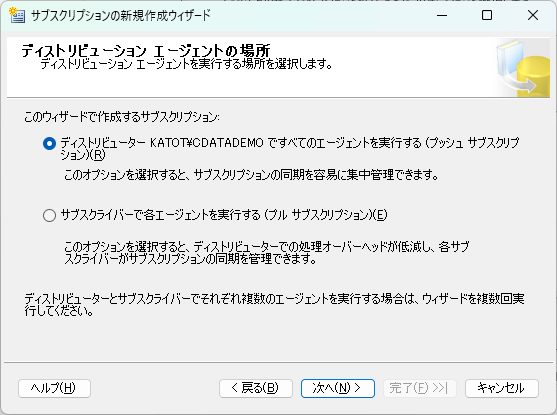
- サブスクリプションデータベースを指定、または新規作成してセキュリティ設定を行います。
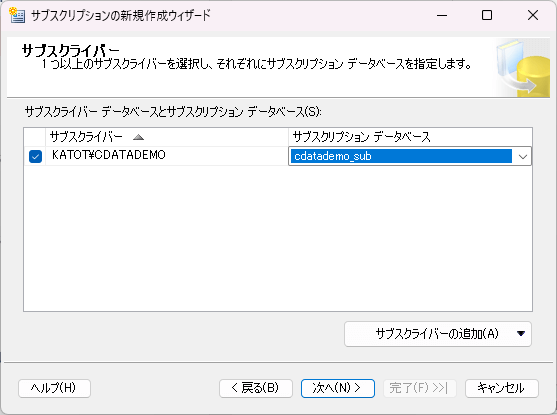
- 同期スケジュールを指定します。
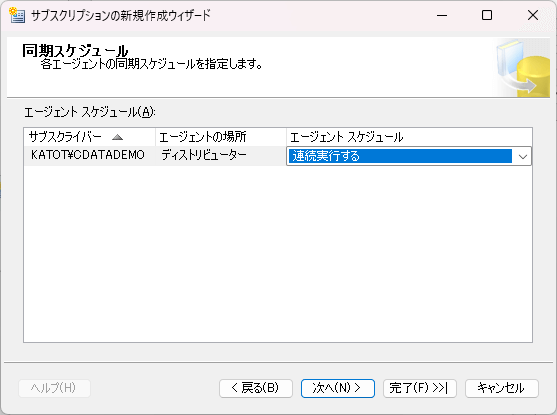
- 最後に初期化時の設定をして、準備は完了です。
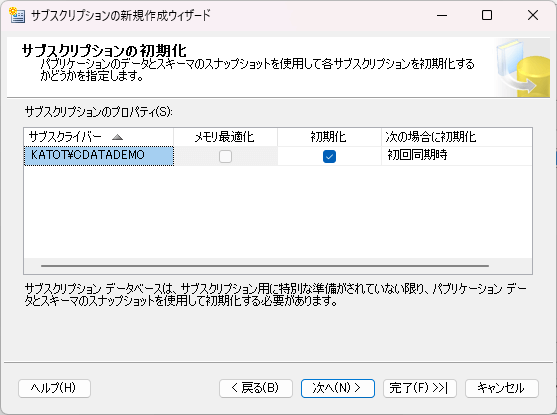
- サブスクリプションが作成できました。
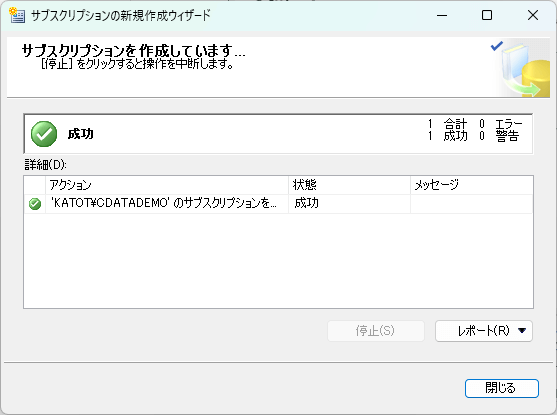
同期が完了すると、無事サブスクリプションDBにAdventureWorks のテーブルが同期されていました。
監視と保守
- レプリケーションにエラーや遅延がないか定期的に監視します。
- 古いデータのクリーンアップ、インデックスの最適化など、定期的なメンテナンス作業を実施しましょう。
エラーとコンフリクトに対処する
- コンフリクトを解決するメカニズムを実装します(特にマージ レプリケーションシナリオの場合は必須)。
- レプリケーションのエラーに対処し、レプリケーションを再開するための計画を立てます。
上記の手順は概要を説明するものであり、具体的な手順はお使いのSQL Server のバージョンや環境の要件によって異なります。レプリケーションの設定に関する詳細および最新情報については、ご使用のSQL Server のバージョンに対応するMicrosoft の公式ドキュメントを参照してください。
CData Sync でSQL Server をレプリケーション
ここまでで、SSMS を利用したSQL Server のレプリケーション方法を見てきました。CData Sync を使用すると、SQL Server のレプリケーションをさらに簡単に、3ステップ・ノーコードで手軽に実現できます。
また、SQL Server 以外にも400種類以上の業務アプリケーション・DB にデータソースとして対応しているほか、SQL Server 以外に20種類以上の同期先を用意しています。SQL Server のレプリケーションをさらに手軽に設定したい方、SQL Server 間以外でのレプリケーションを検討中の方はぜひCData Sync をお試しください。
ということで、CData Sync を使ったSQL Server のレプリケーション設定方法を見ていきましょう。
レプリケーションの同期先としてSQL Server を設定する
SQL Server インスタンスに、データソース・同期先として両方で接続していきます。手順はどちらも同じです。SQL Server への接続は、データソース用とターゲット用で2回設定します。これらはそれぞれディストリビューターとサブスクライバーに対応します(CData Sync が仲介役として機能するため、パブリッシャーは不要です)。
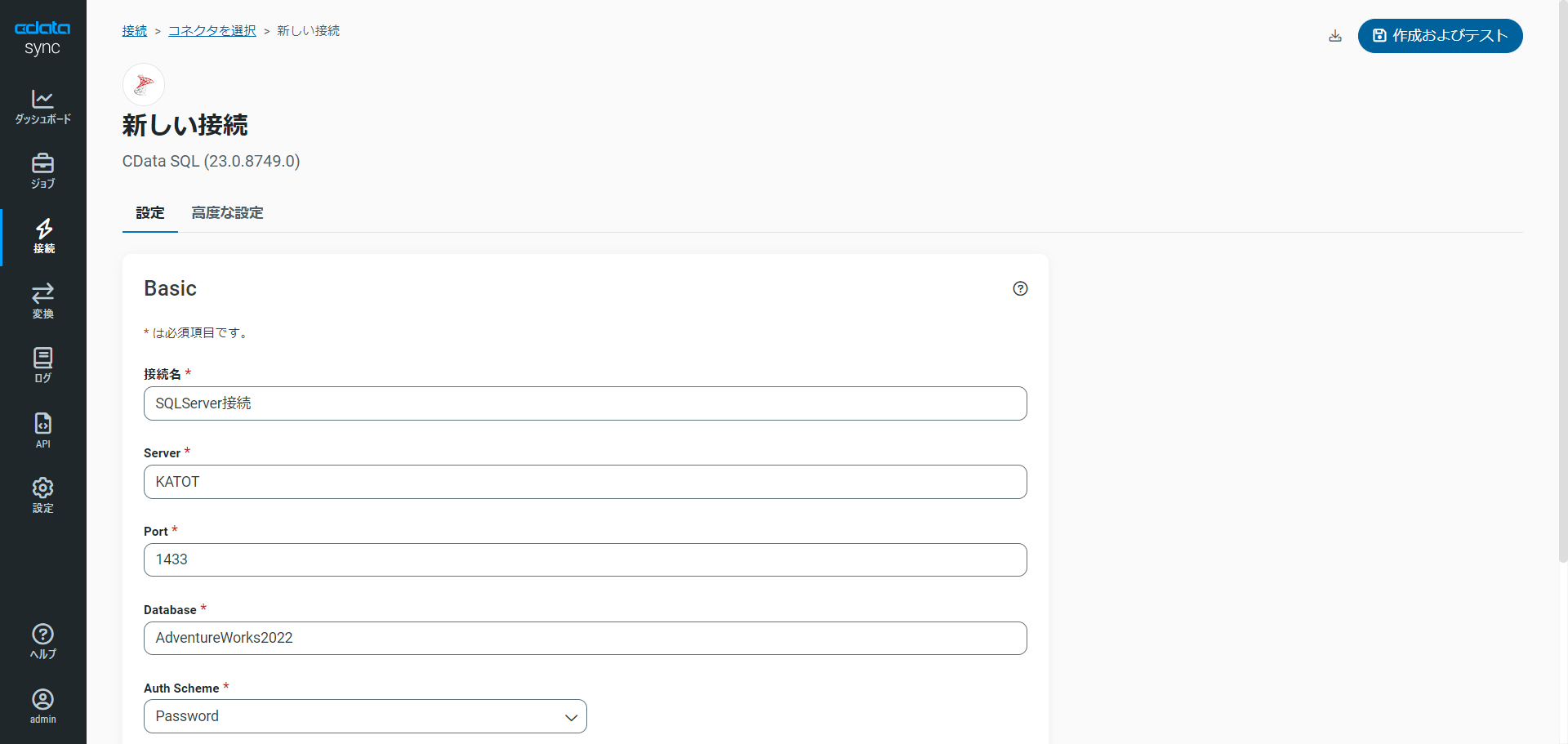
まずは、「接続」ページに移動してSQL Server への接続を追加します。SQL Server インスタンスのホストに応じて接続方法が決まります。
Microsoft SQL Server への接続
次のプロパティを使用してMicrosoft SQL Server に接続します。
- User:SQL Server での認証に使用されるユーザー名。
- Password:認証するユーザーに紐づくパスワード。
- Database:SQL Server データベースの名前。
Azure SQL Server およびAzure Data Warehouse への接続
Azure SQL ServerまたはAzure Data Warehouse に対して認証するには、次のプロパティを設定します。
- Server:Azure を実行しているサーバー。この情報は、Azure ポータルにログインし、「SQL データベース」(またはSQL データウェアハウス > 自身のデータベースを選択 > 概要 > サーバー名)に進むことで見つけることができます。
- User:Azure に対して認証を行うユーザーの名前。
- Password:認証するユーザーに紐づくパスワード。
- Database:Azure ポータルのSQL データベース(またはSQL ウェアハウス)に表示されるデータベースの名前。
接続を設定したら、「接続およびテスト」をクリックして設定を確認します。
レプリケーションジョブを設定する
CData Sync なら、ジョブの設定も数クリックで完了します。構成する個々のレプリケーションについて、「ジョブ」に移動し「ジョブを追加」をクリックします。レプリケーションのデータソースと同期先として、先ほど設定したSQL Server を選択します。

ジョブを追加したら、ジョブの画面に移動して同期するテーブルとカラムを選択していきます。今回は、AdventureWorks のCustomer テーブルを同期してみます。
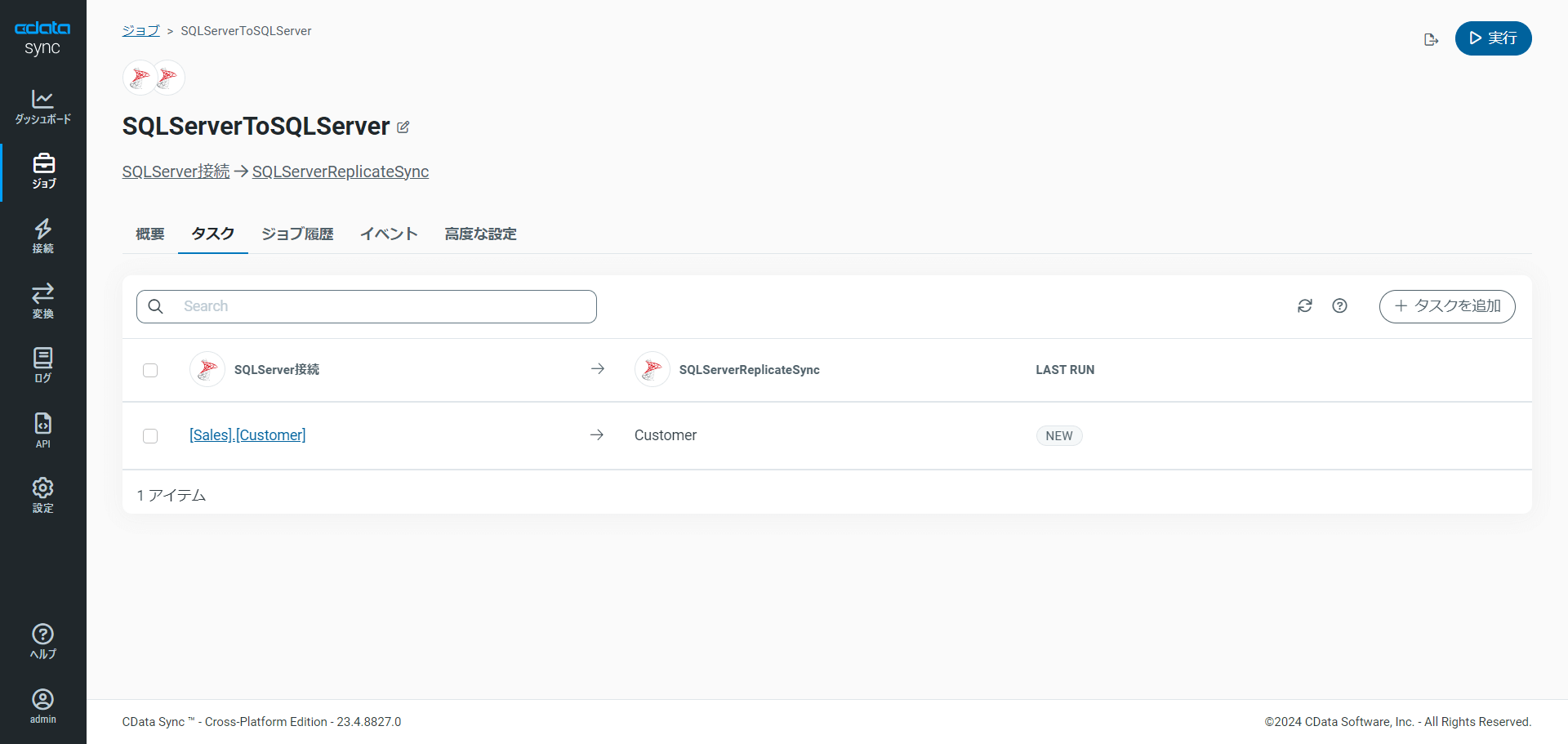
テーブル全体のレプリケート
テーブル全体をレプリケートするには、「タスク」セクションで「タスクを追加」をクリックし、レプリケートしたいテーブルを選択して「タスクを追加」をクリックします。
レプリケーションのカスタマイズ
各タスクの「カラム 」タブと「クエリ」タブを使ってレプリケーション方法をカスタマイズできます。「カラム」タブではレプリケートするカラムを指定したり、同期先でカラム名を変更したり、レプリケート前にデータの変換を実行できます。「クエリ」タブでは、SQL を使ってフィルタリング、グルーピングなどを実行できます。
それでは、実際にジョブを実行してみましょう。
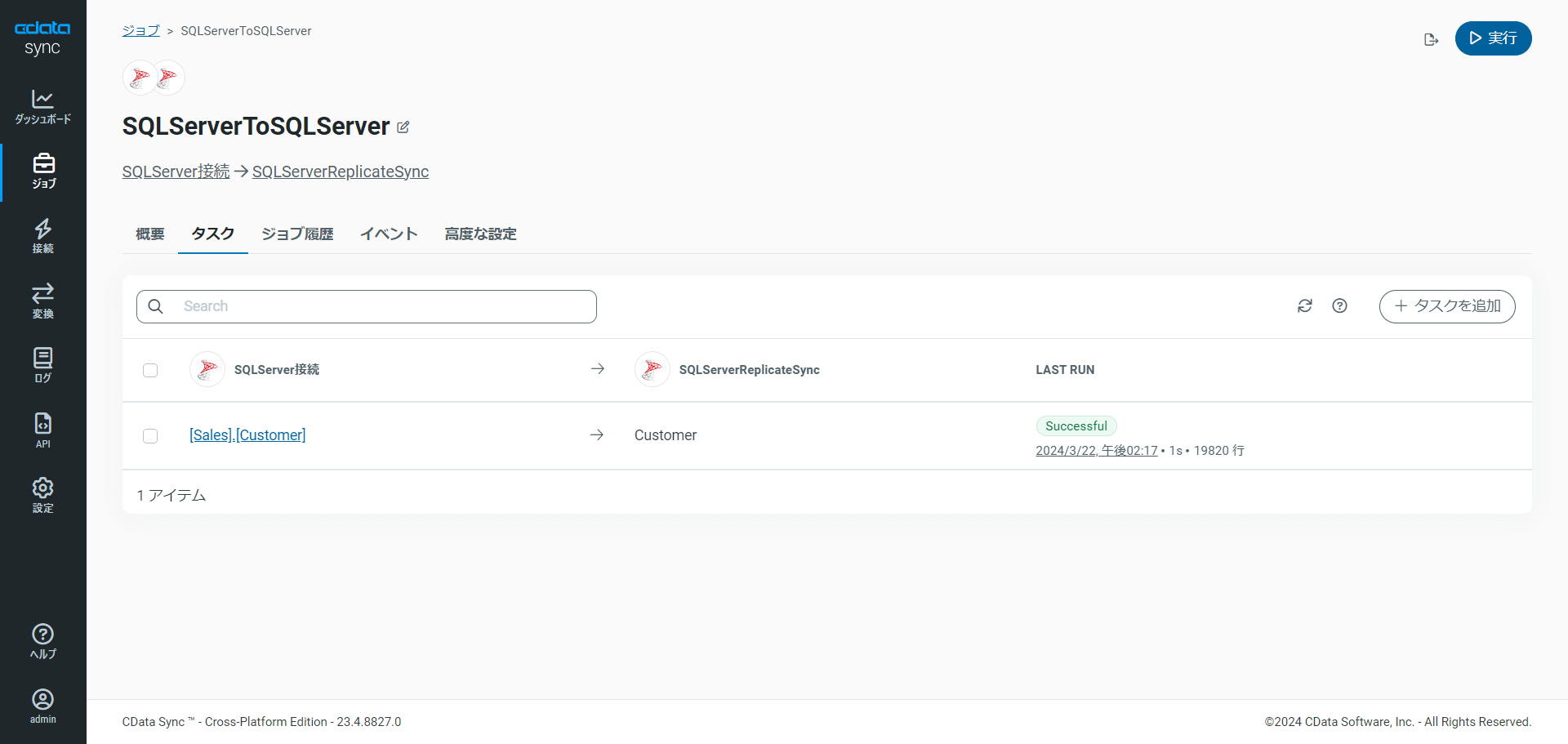
Sync 上でSuccessful と表示され、無事SQL Server 上にレプリケートされました!
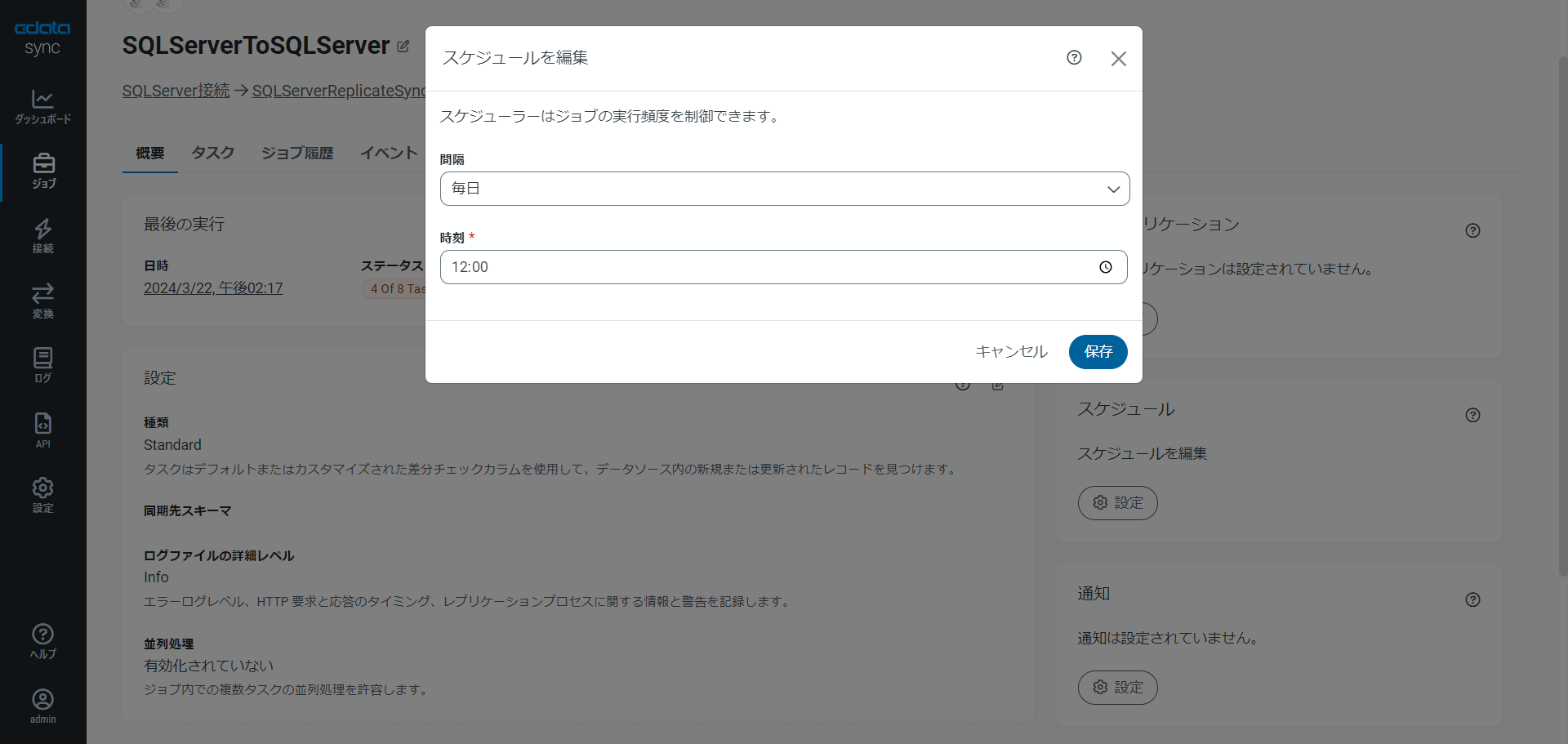
レプリケーションのスケジュールを設定する
初回実行やテスト時はこのように手動で同期してもいいのですが、運用時は自動で同期して欲しいですよね。
Sync では、タスク画面からスケジュール実行を設定できます。タスクの「スケジュール」セクションで、1分間隔でのニアリアルタイムレプリケーションから1カ月間隔、Cron 式でのカスタム間隔まで、お好みのスケジュールでジョブ実行を設定できます。レプリケーションジョブの設定が完了したら、「保存」をクリックします。SQL Server データのレプリケーションを管理するジョブはいくつでも設定できます。
おわりに
ここまでで、SQL Server のレプリケーションを解説してSSMS とCData Sync 双方での設定例を見てきました。
ノーコードのETL ツールであるCData Sync を利用することで、SSMS よりも遥かに簡単にレプリケーションの設定が可能です。また、SQL Server を含む400種類以上のSaaS やDB、および20以上の同期先に対応しています。PostgreSQL、MySQL、Oracle、SAP HANA をはじめ、その他多くの製品がサポートされています。
CData Sync は、リアルタイムのSQL Server データをミラーリングされたデータベース、常時稼動のクラウドデータベース、またほかのタイプのデータベースに数分で統合します。継続的なレプリケーションの自動化(英語記事)がサポートされており、ジョブを一度作成してスケジュールを設定すれば、必要な時に自動で実行されます。
継続的レプリケーションの他にも、CDC を活用した最終更新カラム、整数カウントカラム、バージョンカラムでの増分レプリケーションを実行することもできます。
CData Sync はSQL Server に限らず、オンプレミスサーバーとクラウドサーバーのさまざまな組み合わせのレプリケーションをサポートしており、自由に組み合わせて活用できます。またSSMS とは異なり、ETL / ELT でのデータ変換をサポートしています。
これらの機能はすべてシームレスで、数分で実装することが可能です。