ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →






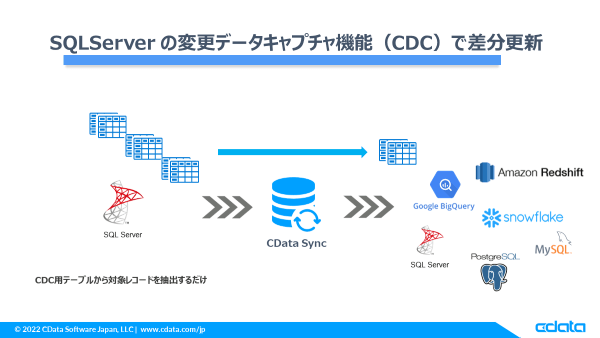
変更データキャプチャ(CDC)を使ったデータレプリケーションを SQL Server → Redshift でやってみた:CData Sync
 こんにちは、テクニカルサポートエンジニアの宮本です。
こんにちは、テクニカルサポートエンジニアの宮本です。
少し前に CData Sync で変更データキャプチャ(CDC)を使ったレプリケーション機能がリリースされました。
これにより、RDB をデータソースとしたジョブでも簡単に差分データの抽出が可能となり、毎回洗替による全件レプリケーションが不要となりました。
とは言え SQL Server の場合は、既に ChangeTracking という SQL Server の機能を使って差分更新は実現できていましたが、今回はそれに加えて CDC でのレプリケーションができるようになったという形です。
変更データキャプチャ(CDC)とは
変更データキャプチャ(CDC)は対象のテーブルに挿入、更新、削除されたときの記録を履歴テーブルのような CDC 用テーブルに保持する機能です。これにより変更があったレコードを履歴テーブルだけで確認することができるため、ETL ツールなどからアクセスする際は、元のテーブルを参照することなく変更データを取得することができます。
詳しくはマイクロソフト公式ドキュメントで。
変更追跡(Change Tracking)との違いは?
基本的にはお互い変更されたレコードだけを取得することができる機能になりますが、Change Tracking では「どこのテーブルのどのキーのレコードが変更された」という情報だけを保持しているため、元のテーブルにぶつけて対象レコードを取得するような仕組みとなっています。
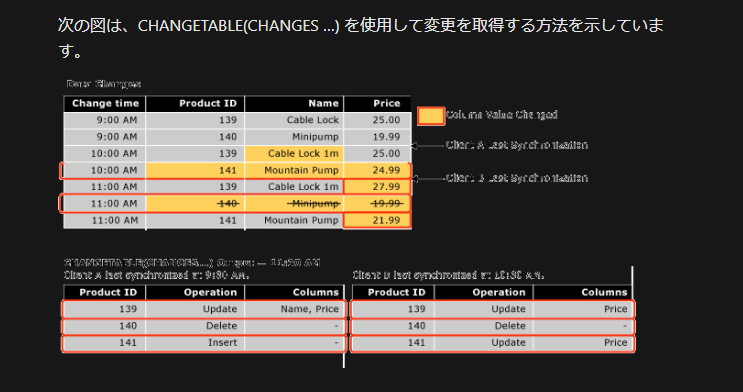
以下は公式ドキュメントに載っているサンプルの図ですが、上が変更されたテーブルの状態で、下がChangeTrackingが保持してる変更情報になります。
 変更の追跡のしくみ - SQL Server | Microsoft Docs
変更の追跡のしくみ - SQL Server | Microsoft Docs
Product ID がキーでColumns では変更カラム名だけを保持していることから、キー設定されているテーブルのみChangeTracking の対象にできるということになります。
これに対して CDC は以下の図のように変更データを履歴テーブル側で全て持っていますのでキーのないテーブルでも CDC の指定が可能となります。

「Change Tracking vs. Change Data Capture」としてCData Sync のヘルプドキュメントにも説明があります。
cdn.cdata.com
ちなみにChange Tracking によるレプリケーション記事もありますので、こちらもよろしければご参照ください。
www.cdatablog.jp
ではさっそく CDC でのレプリケーションをやってみましょう!
手順
最初に準備するものは以下3つになります。
- CData Sync
- SQL Server
- 同期先DB(なんでも良いですが、今回はRedshift)
SQL Server で CDC の有効化
まずは対象 DB を指定して CDC の有効化を行います。
USE cdata;
GO
EXECUTE sys.sp_cdc_enable_db;
GO
これで DB に CDC ユーザーとシステムテーブルに CDC 管理用テーブルが作成されます。
CDC 対象テーブルの指定
CDC 機能を有効化しただけではまだ何もできないので、CDC 対象として設定したいテーブルを指定します。今回は Lead というテーブルを CDC 対象にします。
EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'Lead', @role_name = N'cdc_role', -- @filegroup_name = N'cdc_fg', --本来ならファイルグループを個別に作成した方が良いらしいが、今回は作成しない @supports_net_changes = 1 GO
こうすることで cdc 関連のロールやテーブル、関数が作成されます。
最後に、変更データのキャプチャや履歴テーブルのクリーンアップを実行するためには SQL Server エージェントを開始させる必要がありますので、必ずオンにします。( SQL Server エージェントを右クリック→開始でOK)
これで SQL Server 側の設定が完了です。
CData Sync で SQL Server → Redshift のジョブ作成
やることは ① SQL Server への接続設定、② Redshift への接続設定、③レプリケートジョブの作成の3ステップになります。
①、②の接続設定はそれぞれのタブからアイコンをクリックして接続情報を設定します。

③のジョブ作成はジョブ画面を表示したら「ジョブを追加」からデータソースに SQL Server、同期先に Redshift の接続情報を指定します。
その際、レプリケーションの種類として3つラジオボタンによる選択肢がありますが、今回は CDC の検証をしているので`「変更データキャプチャ」を選択します。
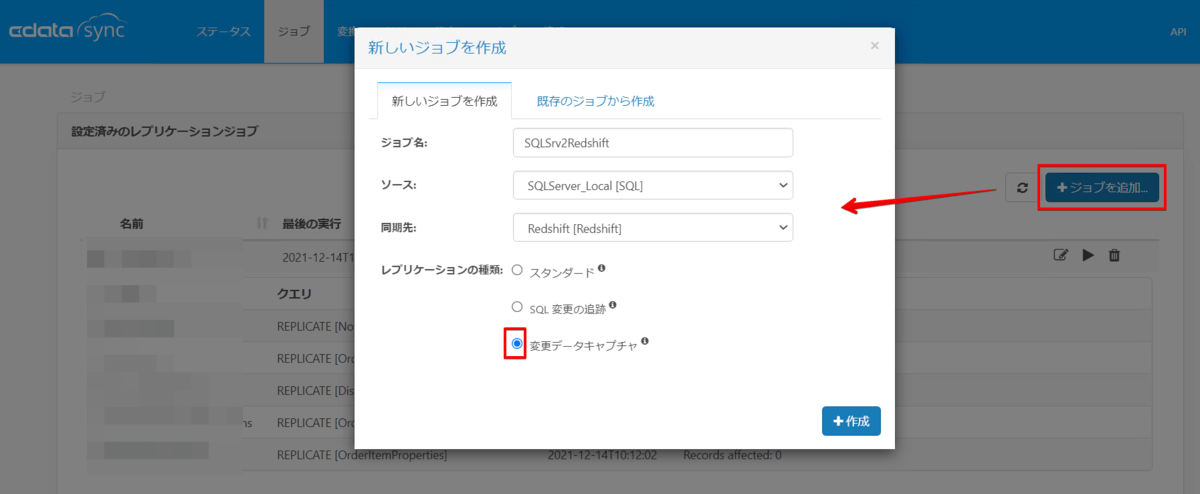
次に「テーブルを追加」ボタンをクリックして、CDC 対象にしたテーブルを選択しますと、
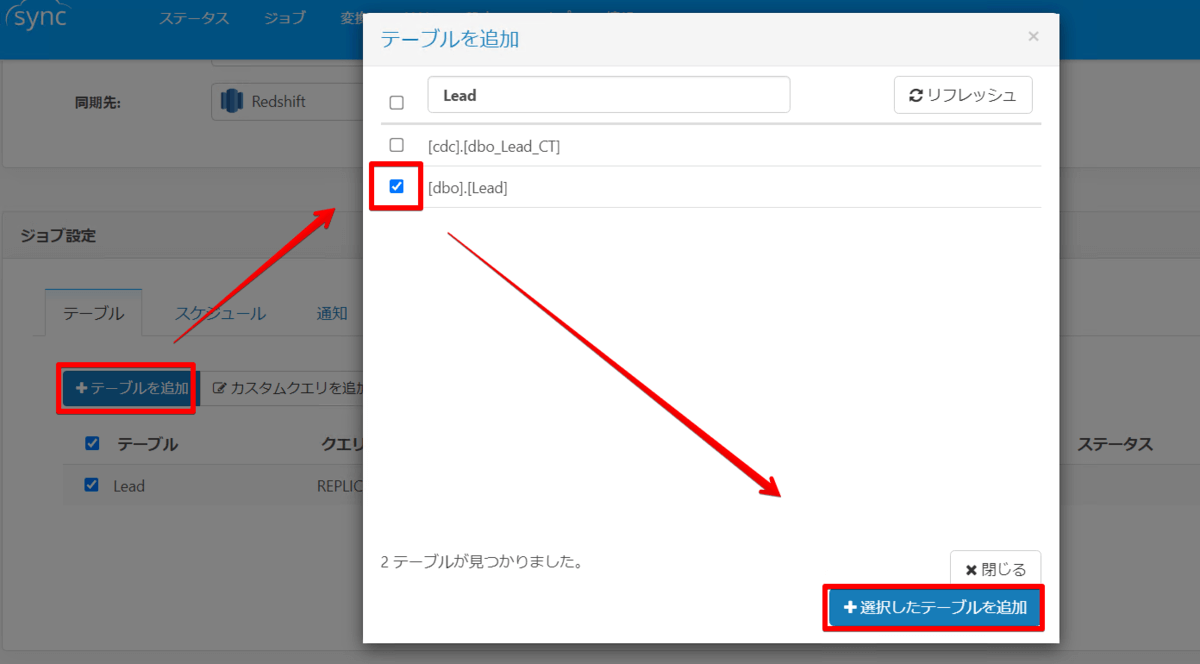
自動で連携用クエリが作成されます。

SQL Server → Redshift のジョブ実行
では作成したジョブを実行してみると 24 件を Redshift に連携しました。
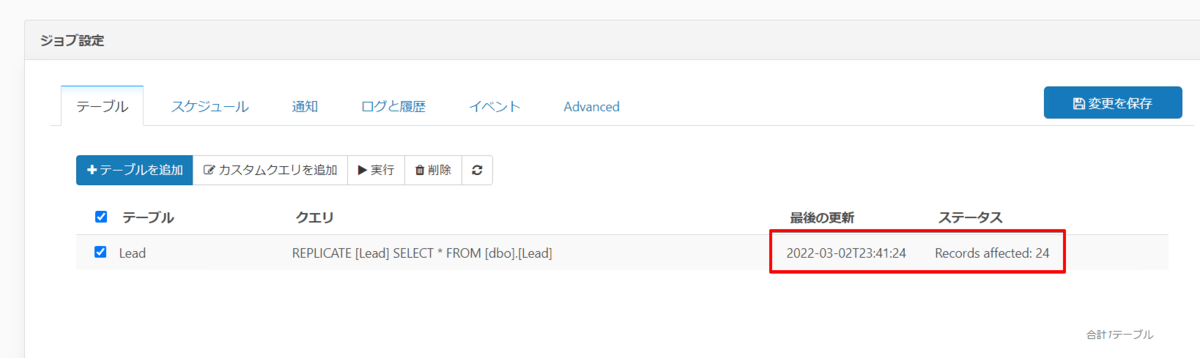
SQL Server 側の Lead テーブルを変更せずに、もう一度ジョブを実行してみるとちゃんと差分データ0件という結果になりました。
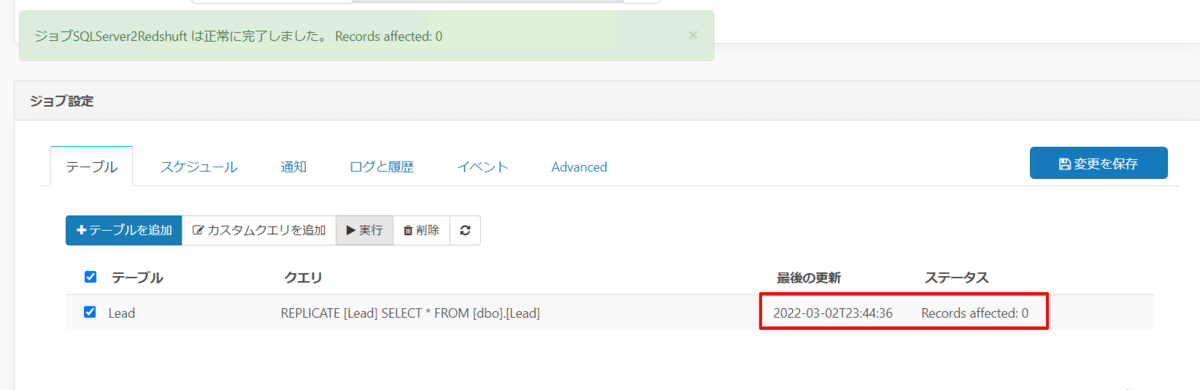
差分更新が効いているのが確認できます。
SQL Server → Redshift で差分更新の検証
差分だけが正しく同期先に連携されるのを確認するため、SQL Server 側の Lead テーブルのレコードを更新してみます。
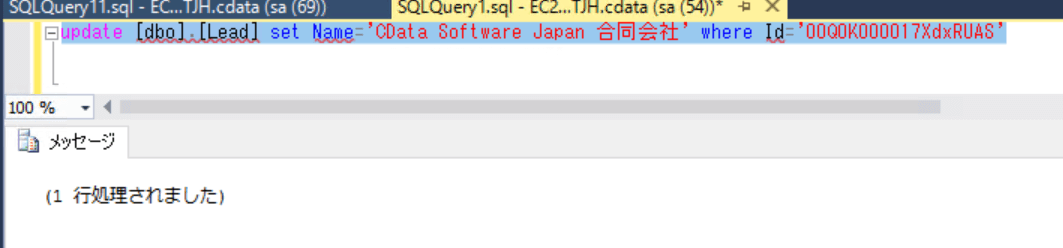
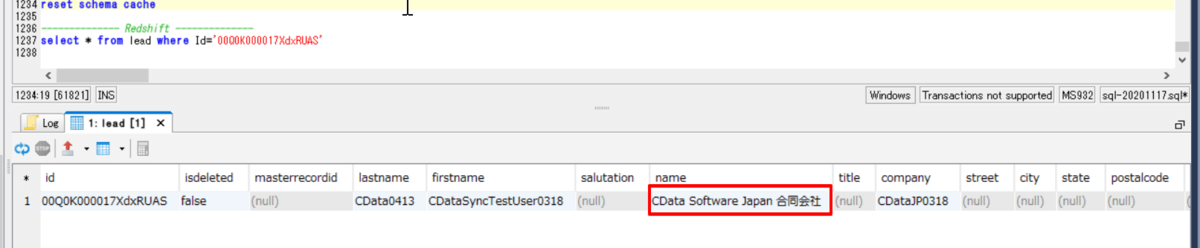
この状態で CData Sync から再度ジョブを実行すると、変更分のレコード分だけが Redshift 同期され、
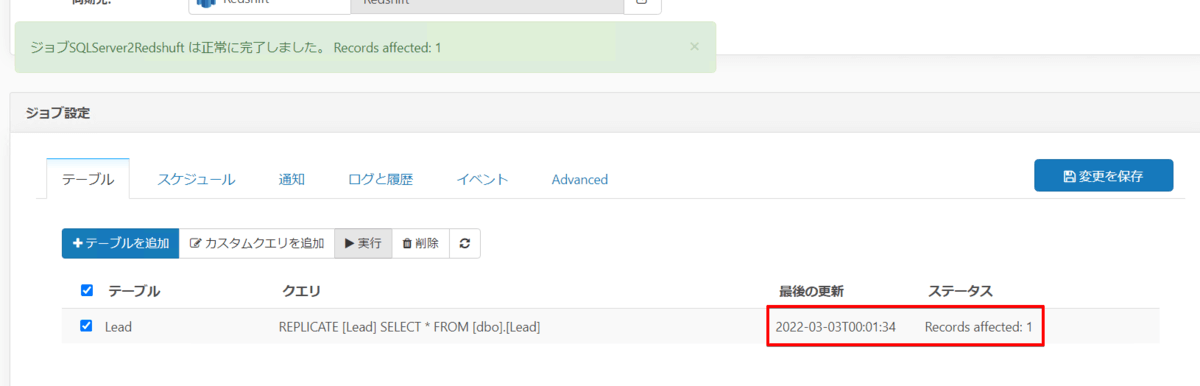
Redshift 側も確認すると、SQL Server で更新した内容が反映されていました!
おわりに
いかがでしたでしょうか。今回は SQL Server の変更データキャプチャ(CDC)機能を使って差分更新を行ってみました。大量のレコードが格納されているようなテーブルだと、毎回全件取得するようなことはレプリケート処理が完了する時間も掛かりますし、何より SQL Server 自体に負荷を掛けてしまいますので、そういったケースでは変更データキャプチャ(CDC)機能でジョブを作成してみてください。
ちなみに今回ご紹介した CData Sync は 30 日間の無償トライアルが可能ですので、是非以下リンクからダウンロードしてお試しください。