ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →こんにちは!プロダクトスペシャリストの宮本です。
常時起動のアプリケーションは、自動フェイルオーバー機能およびリアルタイムなデータアクセスを必要とします。CData Sync は、リアルタイムConfluence データをミラーリングデータベース、上記稼働のクラウドデータベース、レポーティングサーバーなどのほかのデータベースに連携し、Windows からリモートConfluence に接続し、自動的に同期を取ります。
CData Sync を使って、Confluence をクラウド・オンプレにかかわらず複数のデータベースレプリケーションします。レプリケーションの同期先を追加するには、[接続]タブを開きます。
それぞれのデータベース向けに以下を行います:
データソース側にConfluence を設定します。[接続]タブをクリックします。
API token は、アカウントへの認証に必須です。トークンの生成には、Atlassian アカウントでサービスにログインし、API tokens > Create API token に進みます。生成されたトークンが表示されます。
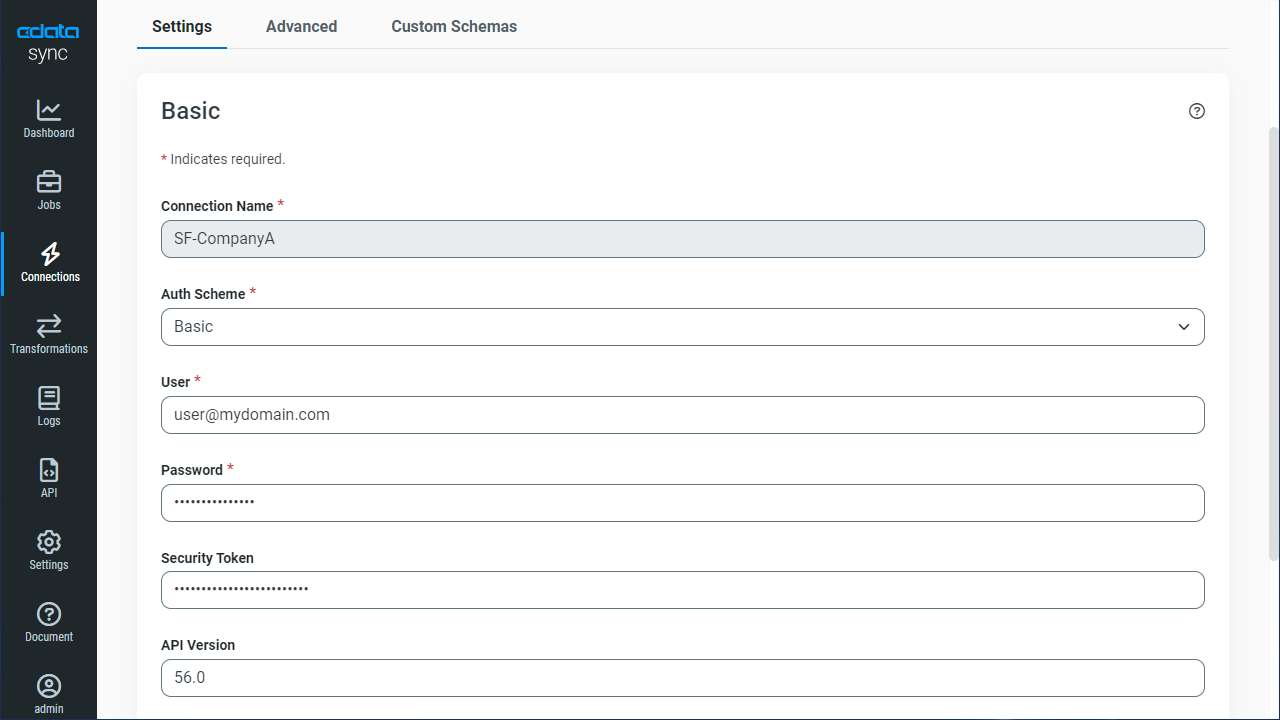
Cloud アカウントへの接続には、以下のプロパティを設定します(Password は、Server Instance への接続時のみ必要で、Cloud Account への接続には不要になりました。):
Server instance への接続には以下を設定します:
CData Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。 次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
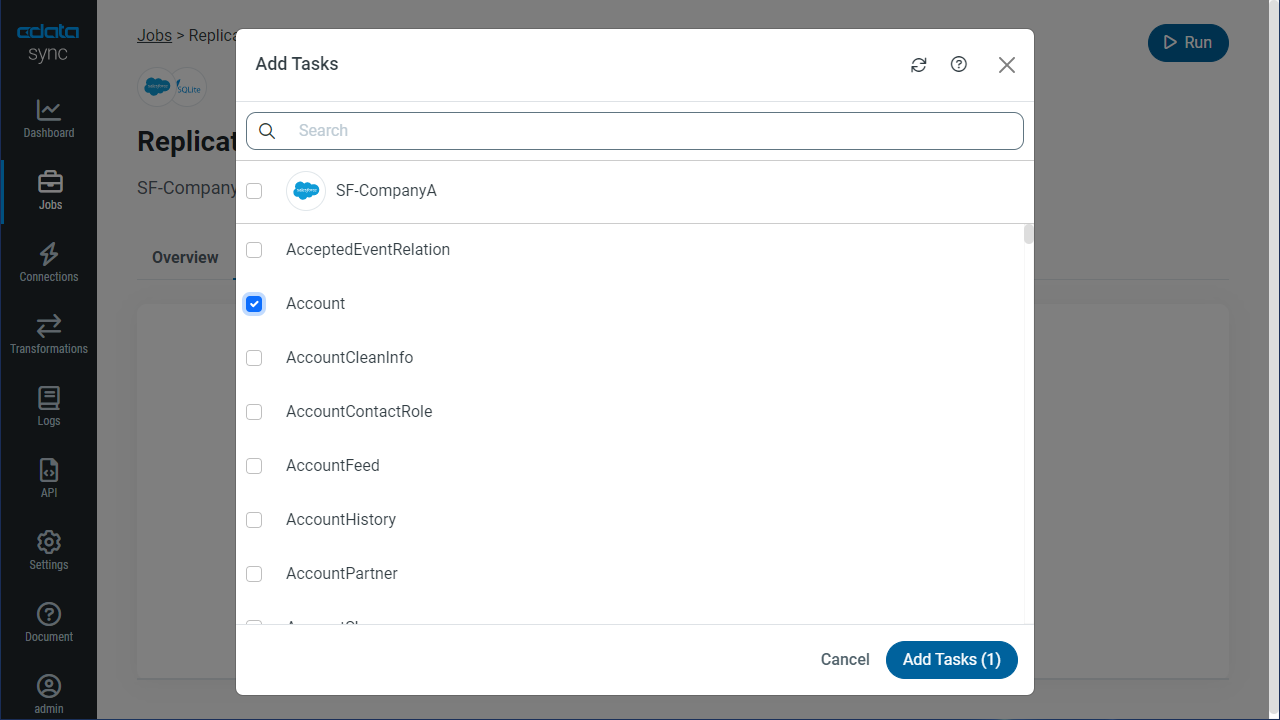
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。
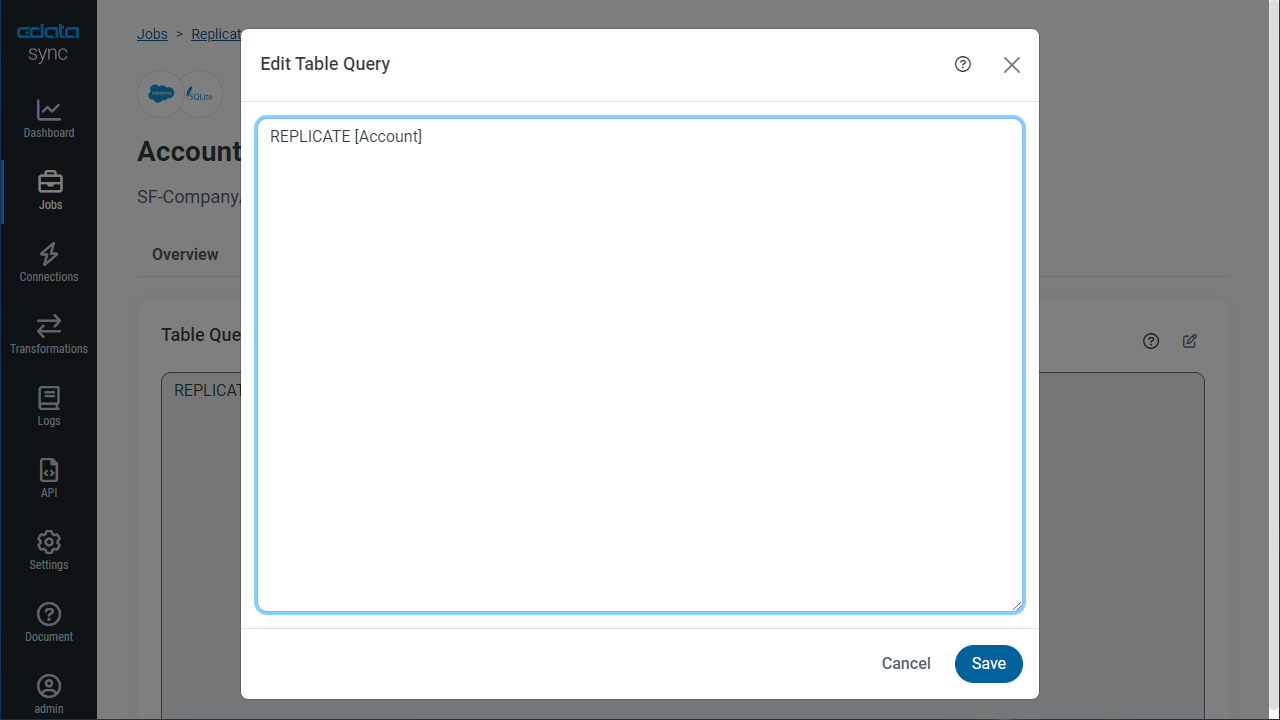
次のステートメントは、Confluence のテーブルのアップデートを差分更新でキャッシュします:
REPLICATE Pages;
特定のデータベースを更新するために、レプリケーションクエリを含むファイルを指定することもできます。レプリケーションクエリをセミコロンで区切ります。複数のConfluence アカウントを同じデータベースに同期しようとする際には、以下のオプションが便利です:
REPLICATE SELECT ステートメントで別のprefix を使う:
REPLICATE PROD_Pages SELECT * FROM Pages;
別の方法では、別のスキーマを使う:
REPLICATE PROD.Pages SELECT * FROM Pages;
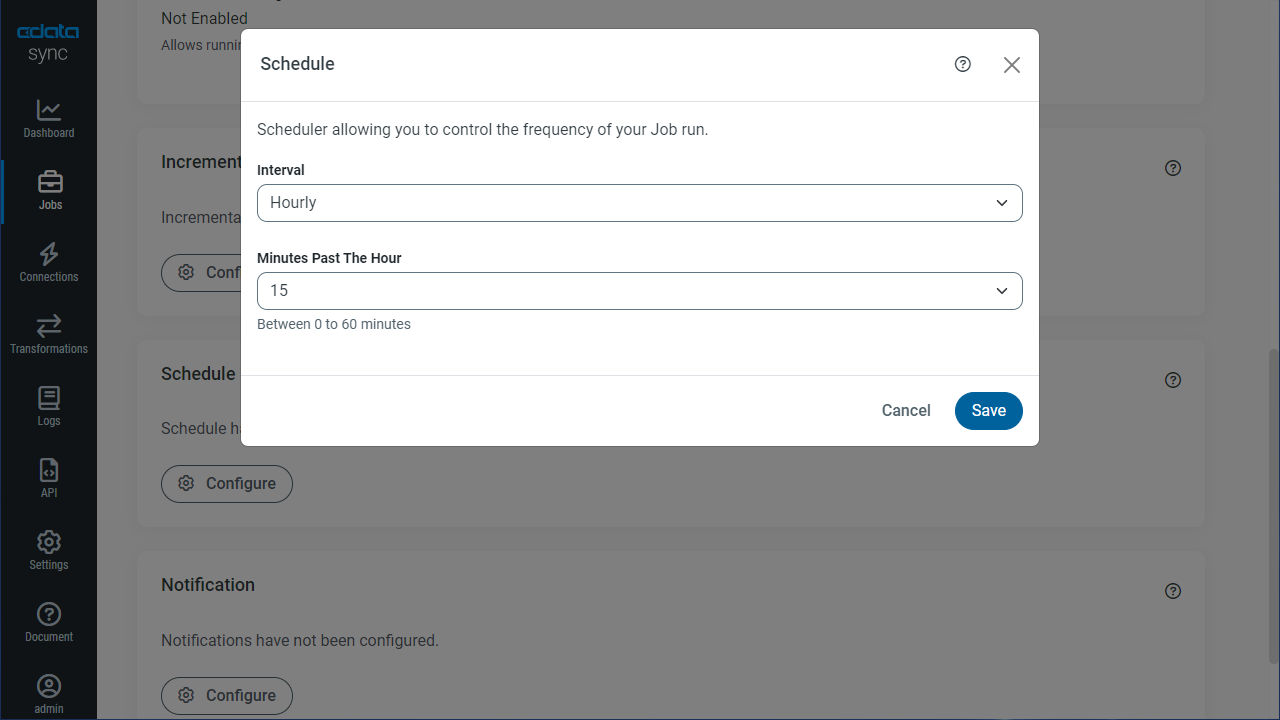
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
レプリケーションジョブを設定したら、[変更を保存]ボタンを押して保存します。Confluence のオンプレミス、クラウドなどのデータベースへのレプリケーションジョブは一つではなく複数を作成することが可能です。