ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Databricks Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
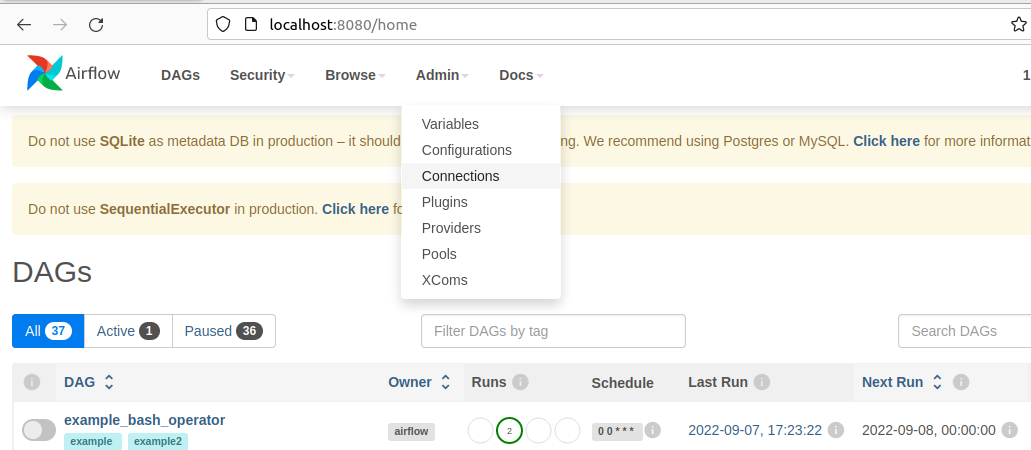
Apache Airflow を使うと、データエンジニアリングワークフローの作成、スケジューリング、および監視を行うことができます。CData JDBC Driver for Databricks と組み合わせることで、Airflow からリアルタイムDatabricks データに連携できます。 この記事では、Apache Airflow インスタンスからDatabricks データに接続してクエリを実行し、結果をCSV ファイルに保存する方法を紹介します。
最適化されたデータ処理が組み込まれたCData JDBC Driver は、リアルタイムDatabricks データを扱う上で高いパフォーマンスを提供します。 Databricks にSQL クエリを発行すると、CData ドライバーはフィルタや集計などのDatabricks 側でサポートしているSQL 操作をDatabricks に直接渡し、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。 組み込みの動的メタデータクエリを使用すると、ネイティブのデータ型を使ってDatabricks データを操作および分析できます。
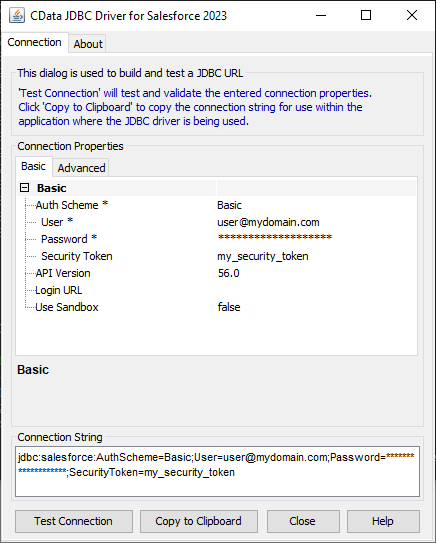
JDBC URL の作成の補助として、Databricks JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.databricks.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。
Note:Databricks インスタンスで必要な値は、クラスターに移動して目的のクラスターを選択し、Advanced Options の下にあるJDBC/ODBC タブを選択することで見つけることができます。
クラスタ環境またはクラウドでJDBC ドライバーをホストするには、ライセンス(フルまたはトライアル)およびランタイムキー(RTK)が必要です。本ライセンス(またはトライアル)の取得については、こちらからお問い合わせください。
以下は、JDBC 接続で要求される必須プロパティです。
| プロパティ | 値 |
|---|---|
| Database Connection URL |
jdbc:databricks:RTK=5246...;Server=127.0.0.1;Port=443;TransportMode=HTTP;HTTPPath=MyHTTPPath;UseSSL=True;User=MyUser;Password=MyPassword;
|
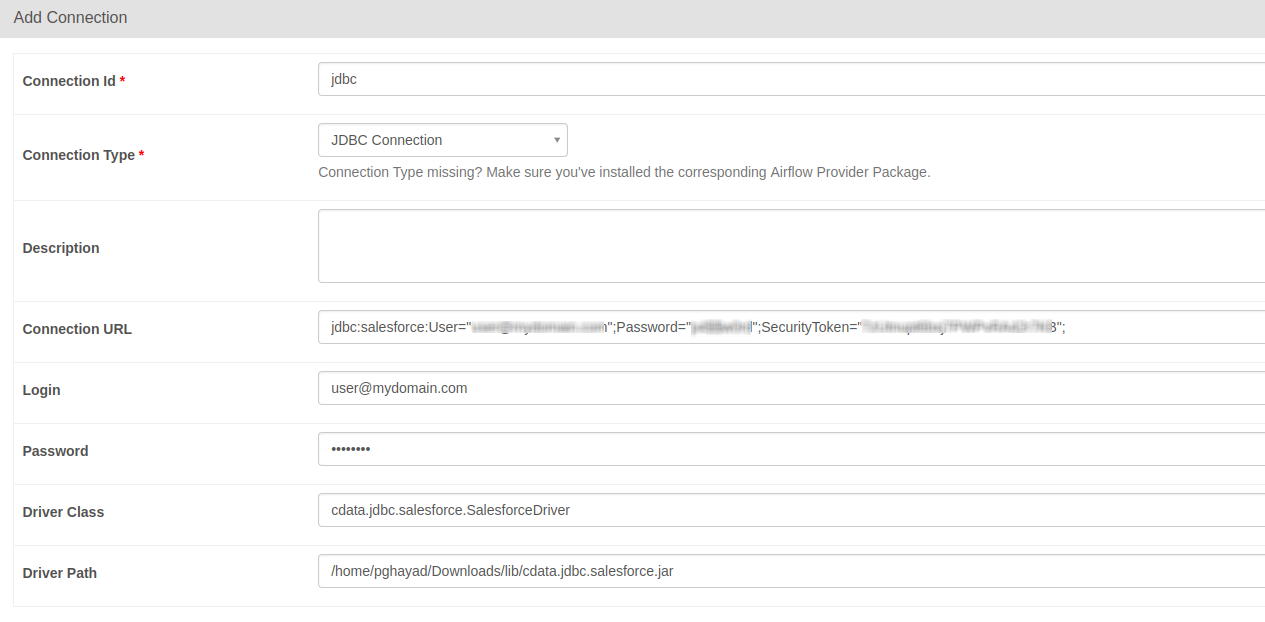
| Database Driver Class Name | cdata.jdbc.databricks.DatabricksDriver |
jdbc:databricks:RTK=5246...;Server=127.0.0.1;Port=443;TransportMode=HTTP;HTTPPath=MyHTTPPath;UseSSL=True;User=MyUser;Password=MyPassword;
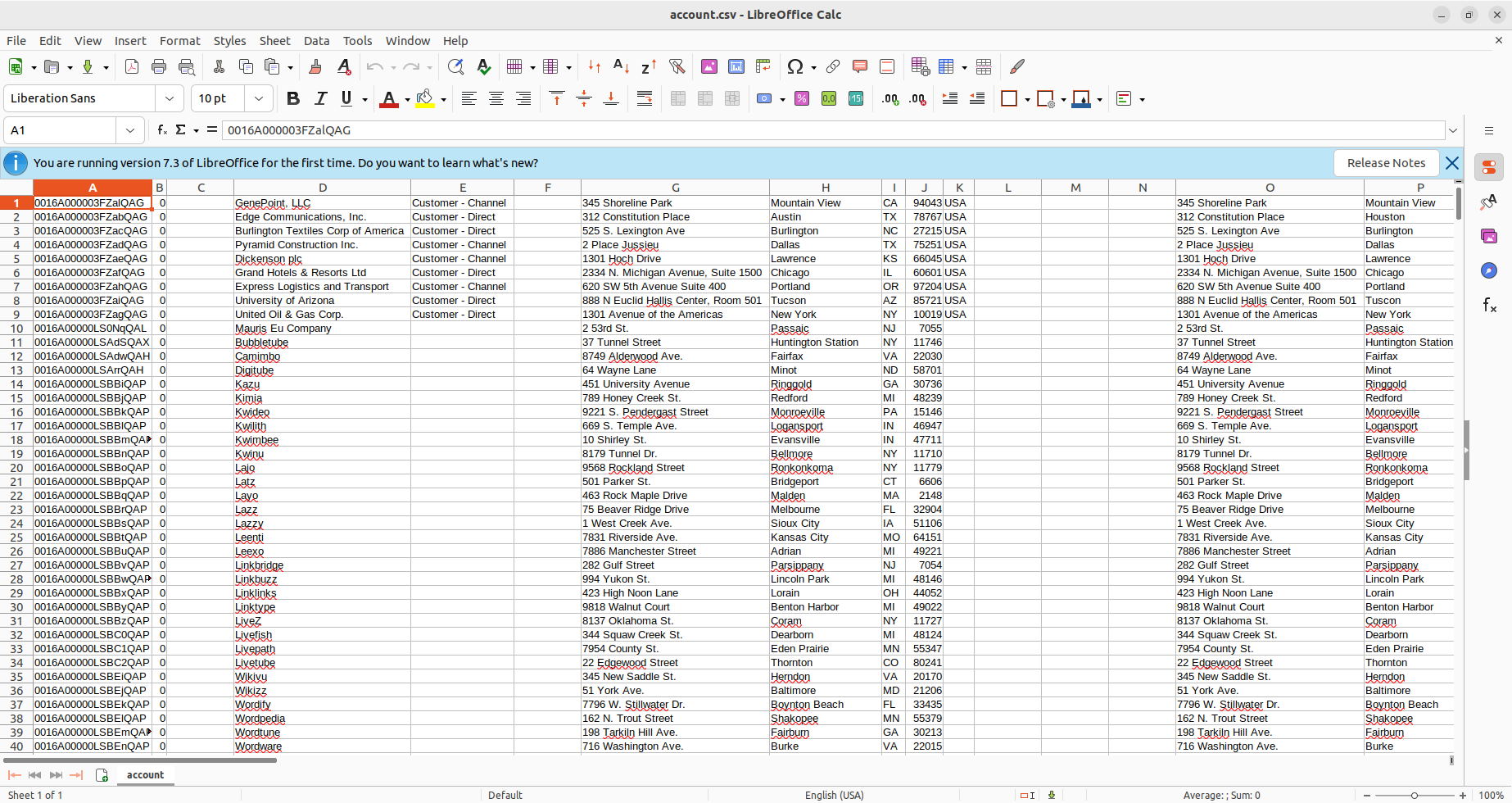
Airflow におけるDAG は、ワークフローのプロセスを格納するエンティティであり、DAG にトリガーを設定することでワークフローを実行することができます。 今回のワークフローでは、シンプルにDatabricks データに対してSQL クエリを実行し、結果をCSV ファイルに格納します。
import time
from datetime import datetime
from airflow.decorators import dag, task
from airflow.providers.jdbc.hooks.jdbc import JdbcHook
import pandas as pd
# Dag の宣言
@dag(dag_id="databricks_hook", schedule_interval="0 10 * * *", start_date=datetime(2022,2,15), catchup=False, tags=['load_csv'])
# Dag となる関数を定義(取得するテーブルは必要に応じて変更してください)
def extract_and_load():
# Define tasks
@task()
def jdbc_extract():
try:
hook = JdbcHook(jdbc_conn_id="jdbc")
sql = """ select * from Account """
df = hook.get_pandas_df(sql)
df.to_csv("/{some_file_path}/{name_of_csv}.csv",header=False, index=False, quoting=1)
# print(df.head())
print(df)
tbl_dict = df.to_dict('dict')
return tbl_dict
except Exception as e:
print("Data extract error: " + str(e))
jdbc_extract()
sf_extract_and_load = extract_and_load()