ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!プロダクトスペシャリストの宮本です。
biz-Stream は、多様な表現が可能なWeb 帳票ソリューションです。
この記事では、biz-Stream からCData JDBC ドライバ経由でSpark データにリアルタイムで連携接続して帳票から利用する方法を紹介します。CData Drivers を使うことで、RDB のようにbiz-Stream 内でSpark データを扱うことができるようになります。
デフォルトの内容でインストールした場合、以下のパスに jar ファイルが配置されますので、その jar ファイルを biz-Stream の所定のパスにコピーします。
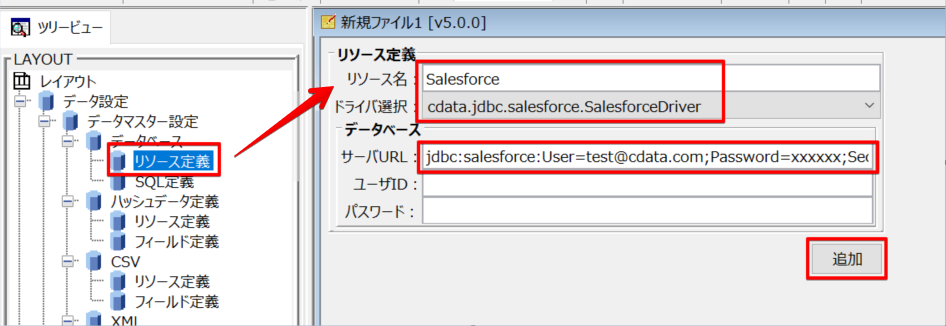
レイアウトデザイナを起動後、リソース定義にて Spark への接続設定を行います。ドライバー選択のプルダウンに CData SparkSQL JDBC Driver が表示されますので選択します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
サーバURLは以下の形式で入力します。
URL: jdbc:sparksql:Server=127.0.0.1;
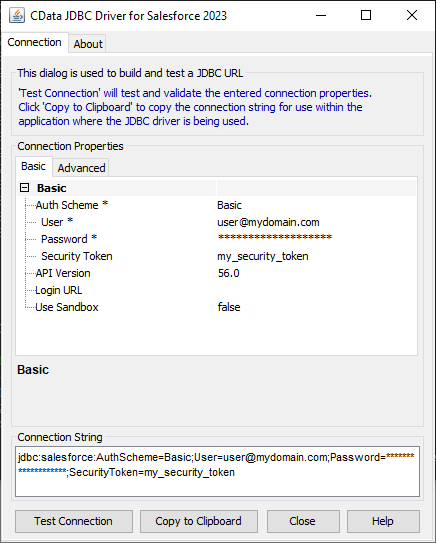
JDBC 接続文字列を作るには、Spark JDBC Driver のビルトイン接続文字列デザイナーを使う方法があります。ドライバーの.jar ファイルをダブルクリックするか、コマンドラインから.jar ファイルを実行します。
Windows:
java -jar 'C:\Program Files\CData\CData JDBC Driver for SparkSQL 20xxJ\lib\cdata.jdbc.sparksql.jar'
MacOS:
java -jar cdata.jdbc.sparksql.jar
接続プロパティに値を入力して、生成される接続文字列をクリップボードにコピーします。
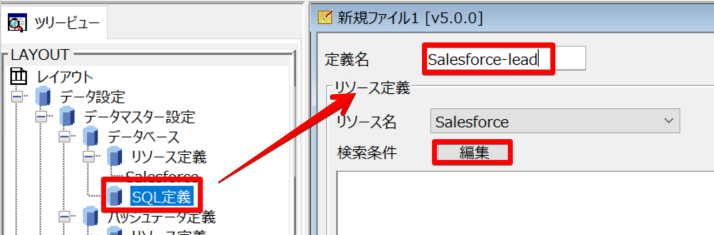
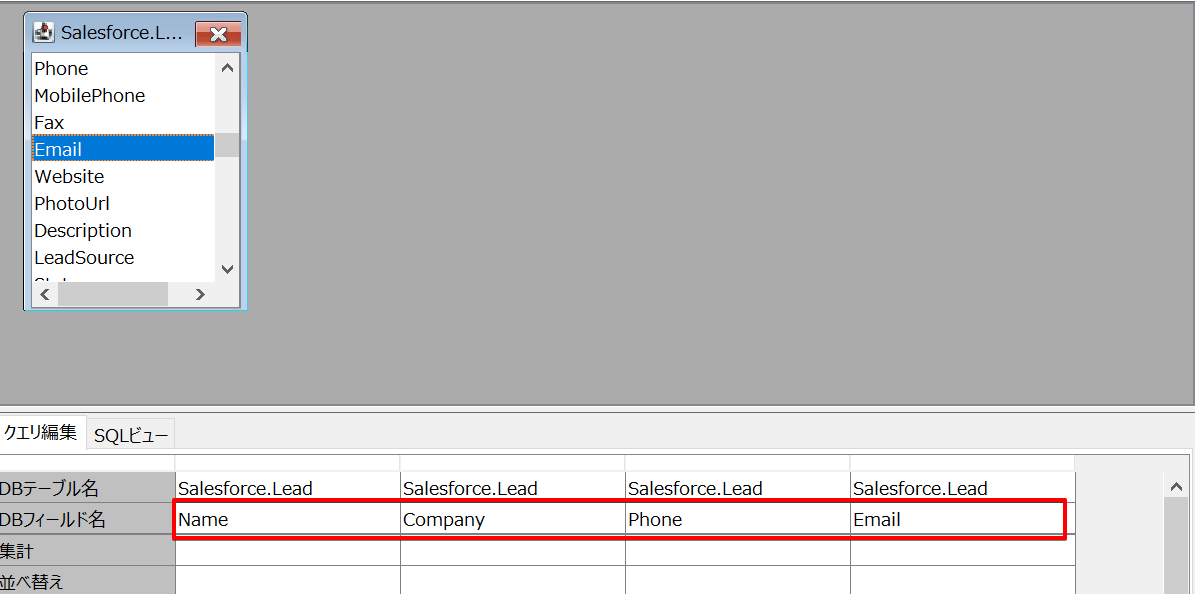
次にデータ取得条件を設定します。SQL 定義から定義名を設定し、編集ボタンをクリックします。
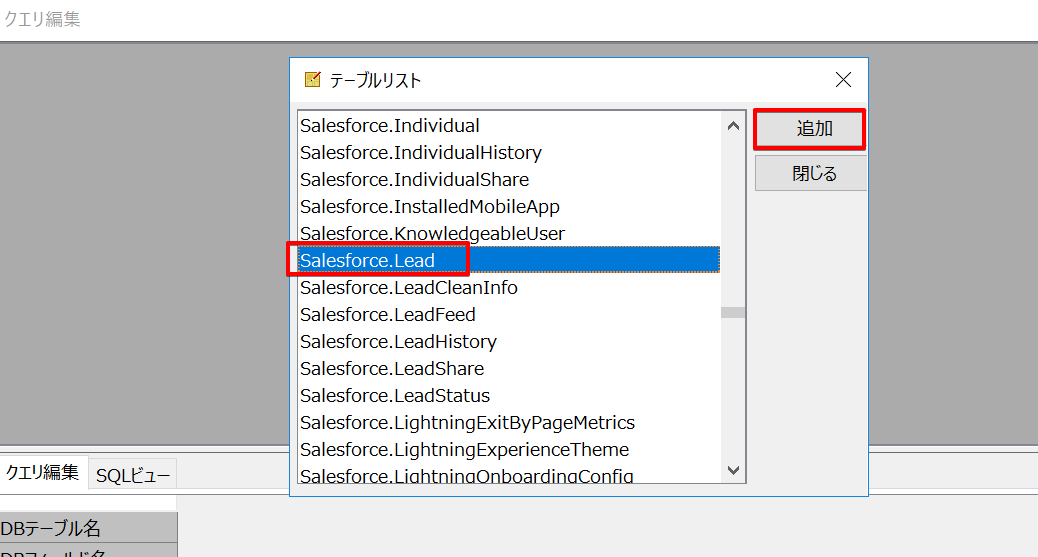
上のグレーエリアで右クリック → テーブルリストと選択しますと、Spark のオブジェクトがリストで表示されます。使用するテーブルを選択します。
ここでは取得対象の項目や条件などを設定することができます。対象項目や条件を指定できたらOKボタンをクリックし、戻った画面で追加ボタンをクリックします。
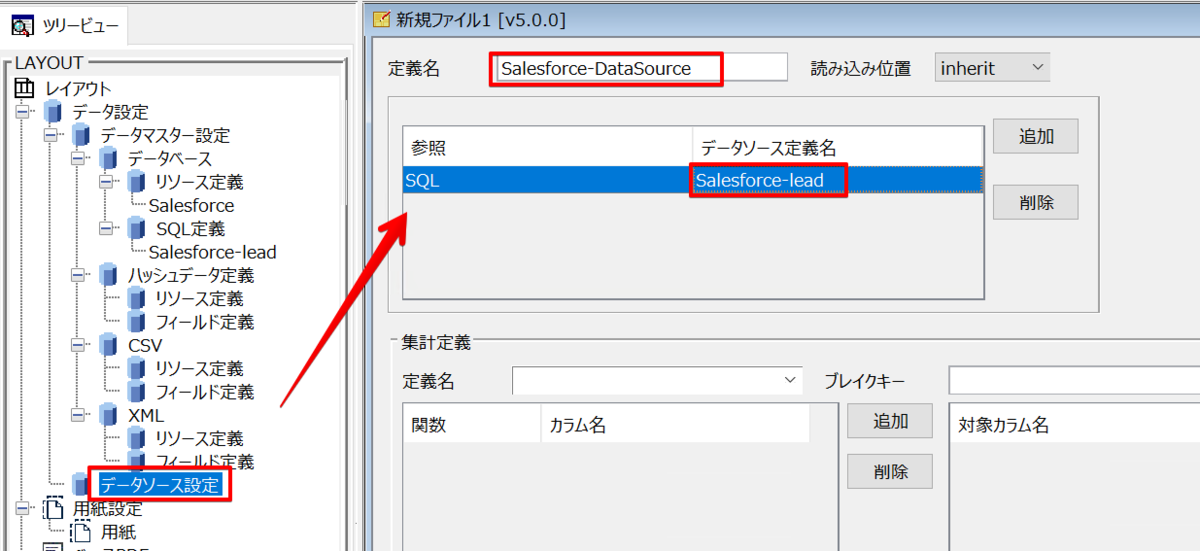
最後にデータソース設定を行います。データソース定義名に先ほど設定したものを選択し、画面下部にある追加ボタンをクリックします。これでbiz-Stream でSpark データを利用する準備ができました。
用紙設定を行います。今回は A4 設定にしました。設定後は画面下部にある追加ボタンをクリックします。
ページ設定では新規ボタンをクリックします。
ここではレイアウトデザイナが帳票テンプレートを xml で保存しますので、ファイル名を設定します。
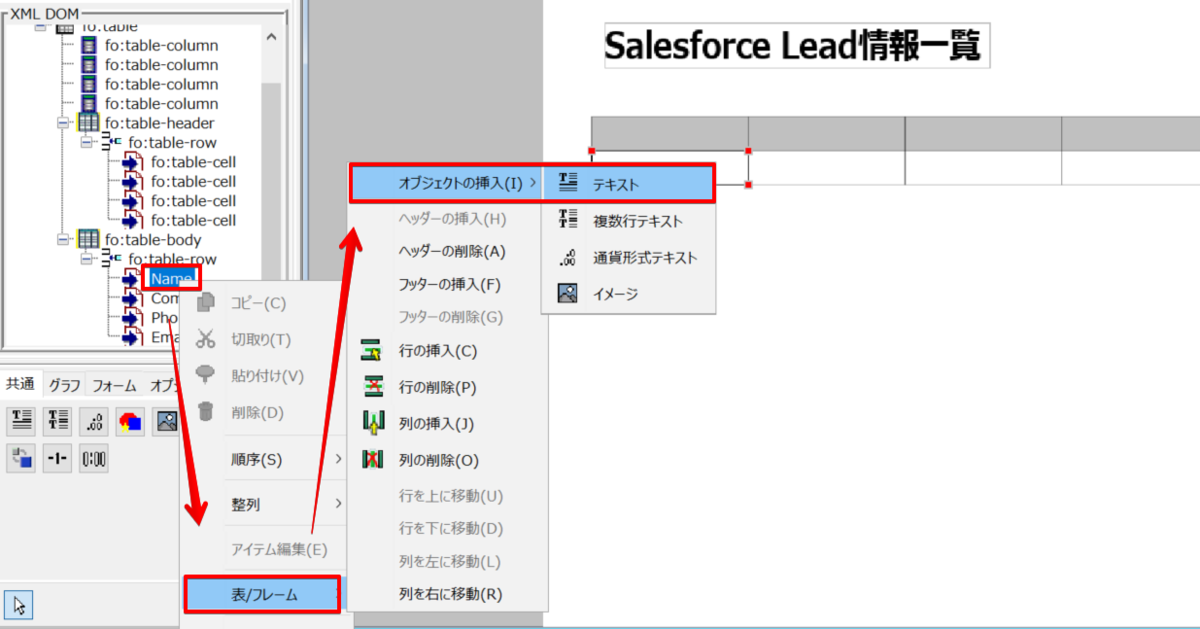
レイアウトにはさまざまなメニューがありますが、今回は表を使用します。表を設定後、Spark から取得したデータをセットするエリアを作成します。各セルにテキストボックスを挿入し、そのテキストボックス自体に Spark の項目を紐づけします。
※ヘッダーにもそれぞれテキストボックスを追加します。
レイアウト作成画面を閉じた後、ページ設定の画面に戻りますので、画面下部にある追加ボタン(一度作成している場合は適用)をクリックし、レイアウトの作成が完了となります。
レイアウトデザイナーのトップ画面のヘッダーメニューからプレビューアイコンをクリックします。先ほど作成したレイアウトで Spark のデータを表示させることができます。
このようにCData JDBC ドライバをアップロードすることで、簡単にbiz-Stream でSpark データをリアルタイムに参照する帳票をノーコードで連携して作成することができます。
ぜひ、CData JDBC Driver for SparkSQL 30日の無償評価版 をダウンロードして、お試しください。