ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
JDBI は、Fluent スタイルとSQL オブジェクトスタイルという2つの異なるスタイルAPI を公開する、Java 用のSQL コンビニエンスライブラリです。CData JDBC Driver for SparkSQL は、Java アプリケーションとリアルタイムSpark データ のデータ連携を実現します。これらの技術を組み合わせることによって、Spark データ へのシンプルなコードアクセスが可能になります。ここでは、基本的なDAO(Data Access Object )とそれに付随するSpark データ の読み書きのためのコードの作成について説明します。
以下のインターフェースは、実装されるSQL ステートメントごとに単一のメソッドを作成するためのSQL オブジェクトの正しい動作を宣言します。
public interface MyCustomersDAO {
//insert new data into Spark
@SqlUpdate("INSERT INTO Customers (Country, Balance) values (:country, :balance)")
void insert(@Bind("country") String country, @Bind("balance") String balance);
//request specific data from Spark (String type is used for simplicity)
@SqlQuery("SELECT Balance FROM Customers WHERE Country = :country")
String findBalanceByCountry(@Bind("country") String country);
/*
* close with no args is used to close the connection
*/
void close();
}
必要な接続プロパティを収集し、Spark に接続するための適切なJDBC URL を作成します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
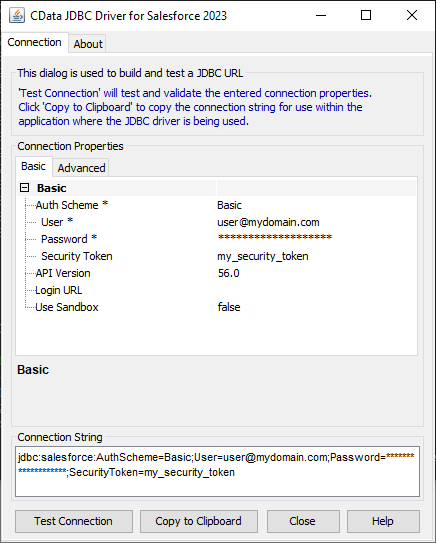
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
Spark の接続文字列は、通常次のようになります。
jdbc:sparksql:Server=127.0.0.1;
構成済みのJDBC URL を使用して、DAO インターフェースのインスタンスを取得します。以下に示す特定のメソッドはインスタンスにバインドされたハンドルを開くため、ハンドルとバインドされたJDBC 接続を開放するには、インスタンスを明示的に閉じる必要があります。
DBI dbi = new DBI("jdbc:sparksql:Server=127.0.0.1;");
MyCustomersDAO dao = dbi.open(MyCustomersDAO.class);
//do stuff with the DAO
dao.close();
Spark への接続を開いた状態で以前定義したメソッドを呼び出すだけで、Spark のCustomers エンティティからデータを取得できます。
//disply the result of our 'find' method
String balance = dao.findBalanceByCountry("US");
System.out.println(balance);
以前定義した方法を使用すれば、Spark にデータを書き込むことも簡単になります。
//add a new entry to the Customers entity
dao.insert(newCountry, newBalance);
JDBI ライブラリはJDBC 接続を処理できるため、CData JDBC Driver for SparkSQL と統合することで、SQL Object API for SparkSQL を簡単に作成できます。今すぐ無料トライアルをダウンロードし、Java アプリケーションでリアルタイムSpark を操作しましょう。