ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →SQL Server Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Elasticsearch は、人気の分散型全文検索エンジンです。データを一元的に格納することで、超高速検索や、関連性の細かな調整、パワフルな分析が大規模に、手軽に実行可能になります。Elasticsearch にはデータのローディングを行うパイプラインツール「Logstash」があります。CData Drivers を利用することができるので、30日の無償評価版をダウンロードしてあらゆるデータソースを簡単にElasticsearch に取り込んで検索・分析を行うことができます。
この記事では、CData Driver for SQL を使って、SQL Server のデータをLogstash 経由でElasticsearch にロードする手順を説明します。
それでは、Logstash でElasticsearch にSQL Server データの転送を行うための設定ファイルを作成していきます。
Microsoft SQL Server への接続には以下を入力します。
Azure SQL Server およびAzure Data Warehouse には以下の接続プロパティを入力して接続します:
input {
jdbc {
jdbc_driver_library => "../logstash-core/lib/jars/cdata.jdbc.sql.jar"
jdbc_driver_class => "Java::cdata.jdbc.sql.SQLDriver"
jdbc_connection_string => "jdbc:sql:User=myUser;Password=myPassword;Database=NorthWind;Server=myServer;Port=1433;"
jdbc_user => ""
jdbc_password => ""
schedule => "*/30 * * * * *"
statement => "SELECT ShipName, Freight FROM Orders"
}
}
output {
Elasticsearch {
index => "sql_Orders"
document_id => "xxxx"
}
}
それでは作成した「logstash.conf」ファイルを元にLogstash を実行してみます。
> logstash-7.8.0\bin\logstash -f logstash.conf
成功した旨のログが出ます。これでSQL Server データがElasticsearch にロードされました。
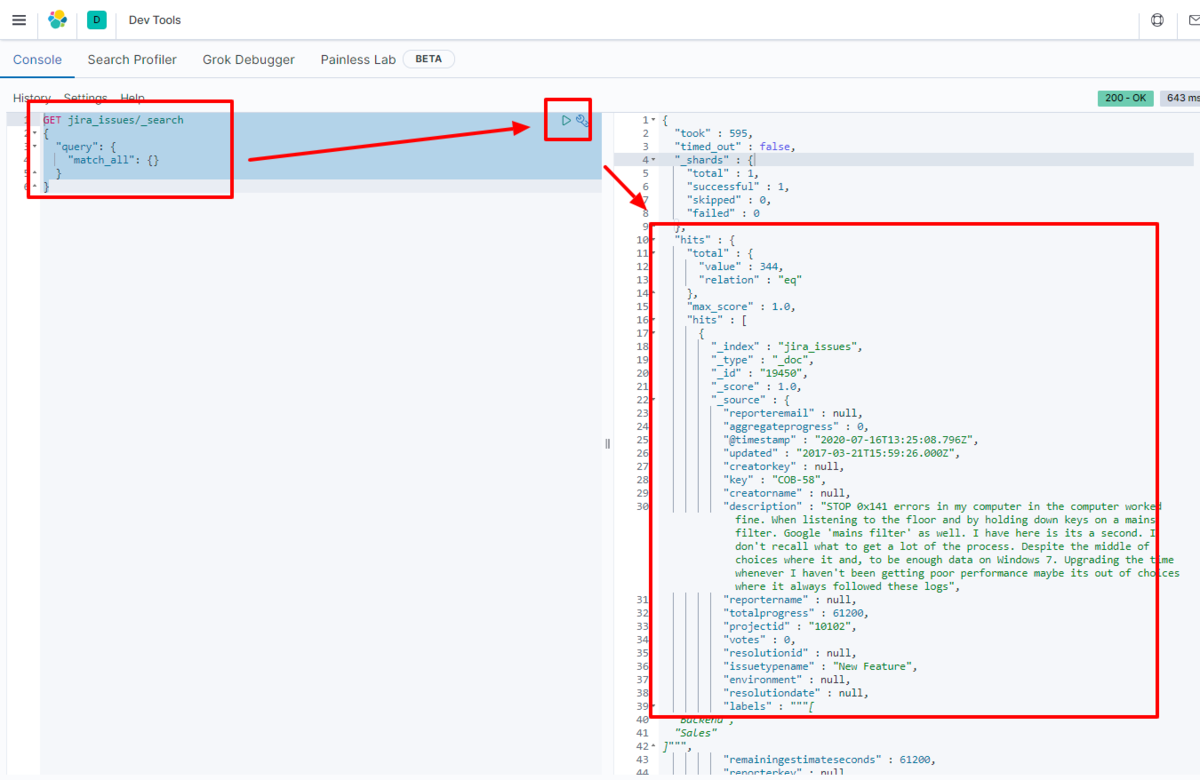
例えばKibana で実際にElasticsearch に転送されたデータを見てみます。
GET sql_Orders/_search
{
"query": {
"match_all": {}
}
}
データがElasticsearch に格納されていることが確認できました。
CData JDBC Driver for SQL をLogstash で使うことで、SQL Server コネクタとして機能し、簡単にデータをElasticsearch にロードすることができました。ぜひ、30日の無償評価版をお試しください。