ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →





企業内検索エンジンサービスの Neuron に Salesforce のデータを取り込んで検索する方法:CData JDBC Driver
こんにちは。CData Software Japan リードエンジニアの杉本です。
今回は企業内検索エンジンサービスのNeuronとCData JDBC Driver を組み合わせ、Salesforceデータを Neuron上で検索できるようにする方法をご紹介します。
Neuron とは?
先端OSS技術(Apache Solr)を活用したエンタープライズサーチ(企業内検索エンジン)サービスです。
Apache Solrのみですと、エンタープライズサーチのメカニズムをAPIとして提供するのみですが、NeuronはApache Solrをベースにしながら、企業ユーザーがデータを探索するためのシンプルかつ使いやすいユーザーインターフェースと管理画面・運用機能を提供してくれます。
https://www.brains-tech.co.jp/neuron/
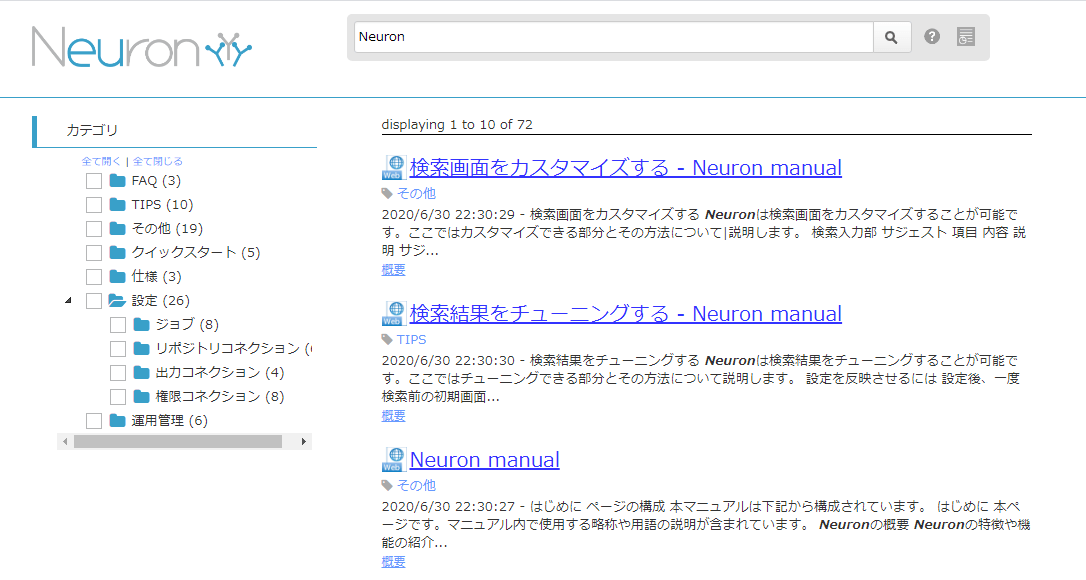
以下のような普段から馴染みのある検索画面を提供しているので、エンドユーザーでも気軽にエンタープライズ検索を実施できます。
設定がしやすい管理画面も提供されており、ファイルやデータのクローリング設定がUI上から簡単に行なえます。
本記事のシナリオ
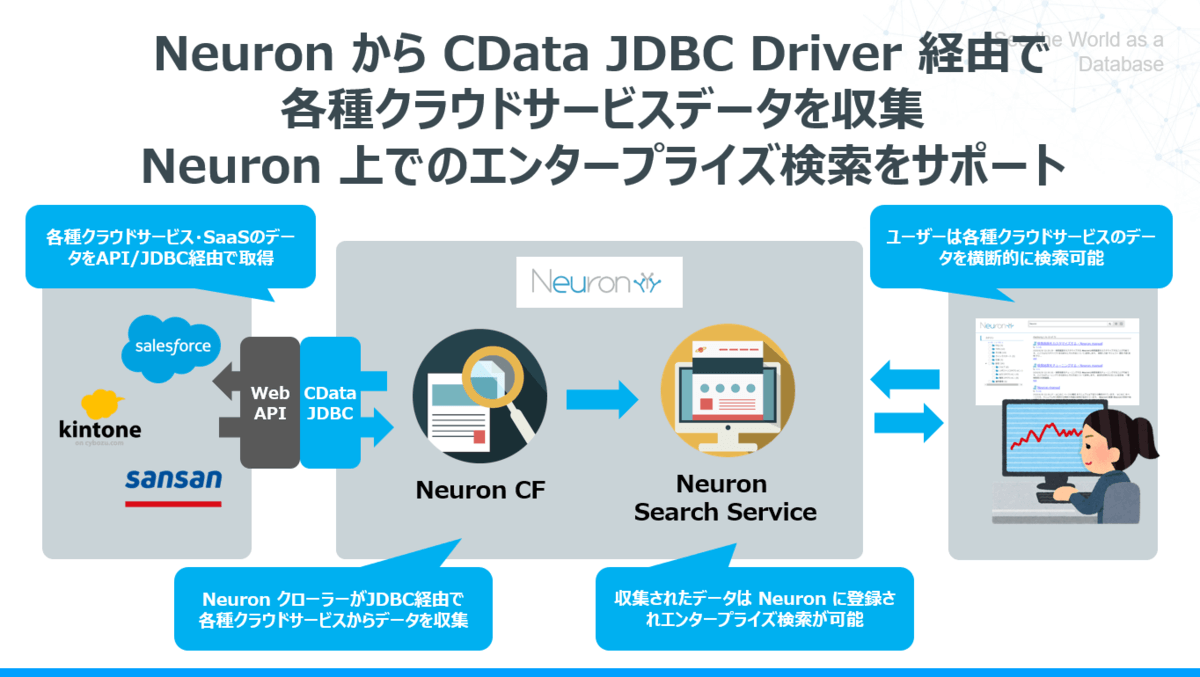
本記事では CRM・SFAクラウドサービスであるSalesforceのデータをNeuronに取り込み、エンタープライズサーチが実施できるようにするための手順を紹介します。
通常 Neuron はFileSystemやSharePoint、Notesといったファイル・ドキュメント管理サービス、もしくはWebクローラーやJDBC経由でのRDB接続で取得したデータのみを検索の対象としています。

Apache Solrの仕組みを利用して、プログラムでデータを取得して登録することもできますが、様々なAPIへの連携実装や保守・メンテナンスのコストが多くかかってしまいます。
そこで本記事ではNeuronがもともと備えているJDBCのインターフェースを利用することでこのボトルネックを解消します。
CData Software Japan では SalesforceやKintone、JIRAなどに接続することができる各種JDBC Driverを200種類ほど提供しています。
https://www.cdata.com/jp/jdbc/#drivers

この各種JDBC Driverを用いることで、NeuronからシームレスにWeb APIアクセスが可能となり、GUIからの設定のみで各種クラウドサービス・SaaSのデータをクローリングし収集することができるようになります。
これでユーザーは Neuron という共通インターフェースを使いながら、クラウドサービス横断的にエンタープライズ検索を実施することができるようになります。
手順
それでは実際に Neuron から Salesforce に接続し、データを収集する方法を紹介したいと思います。
必要なもの
- Neuron 本体
- CData Salesforce JDBC Driver
- Salesforce アカウント(トライアルの取得方法はこちらを参照)
なお、今回はWindows Server 2016 に予めNeuronをインストールしています。
Salesforce JDBC Driver のインストール
まず、CData Salesforce JDBC Driver をインストールします。トライアルは以下のURLから入手できます。
https://www.cdata.com/jp/drivers/salesforce/jdbc/

ダウンロード後、exeファイルを実行し、セットアップを進めます。
JDBC Driver を Neuron のlibフォルダに配置
CData Salesforce JDBC Driver のインストールが完了すると、以下のフォルダにJDBC Driverの本体であるjarファイルが生成されます。
C:\Program Files\CData\CData JDBC Driver for Salesforce 2019J\lib
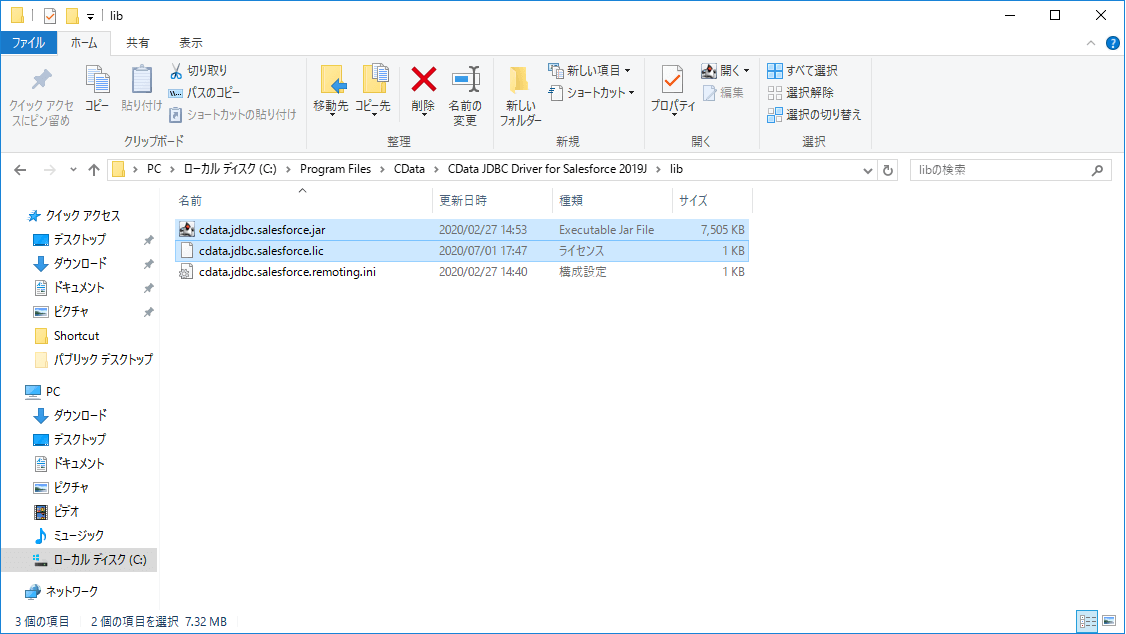
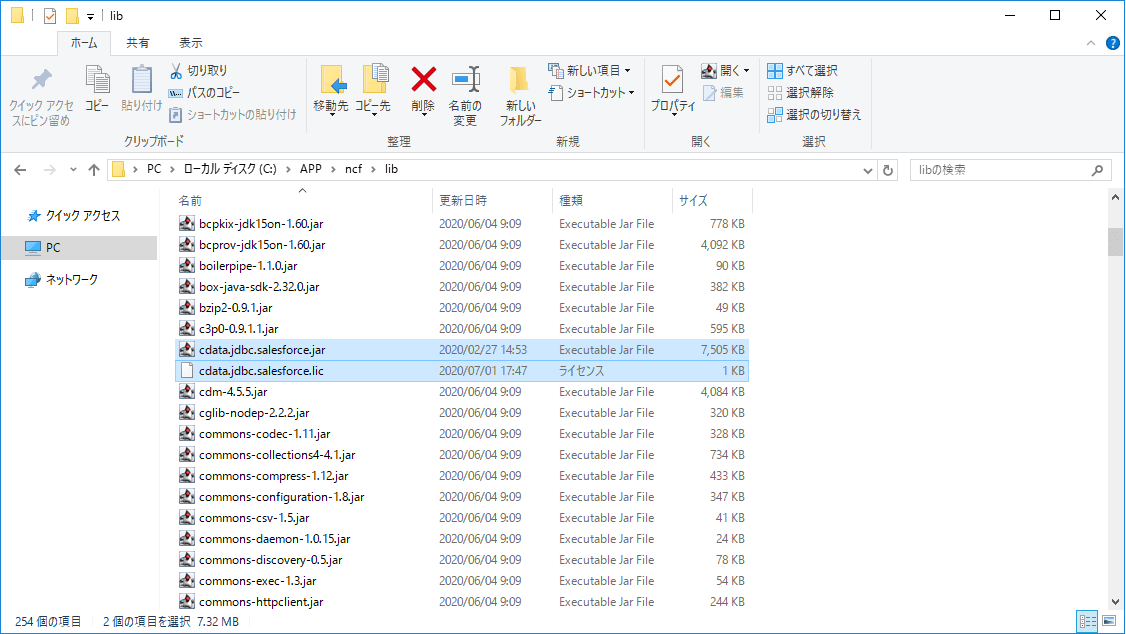
この「cdata.jdbc.salesforce.jar」ファイルとライセンスファイルである「cdata.jdbc.salesforce.lic」をNeuronの以下のフォルダに配置します。
- C:\APP\ncf\lib
リポジトリの作成
続いて、Neuron CFでクローラーの設定を進めます。
まずはJDBC Driverを読み取るためのリポジトリ情報を構成しましょう。
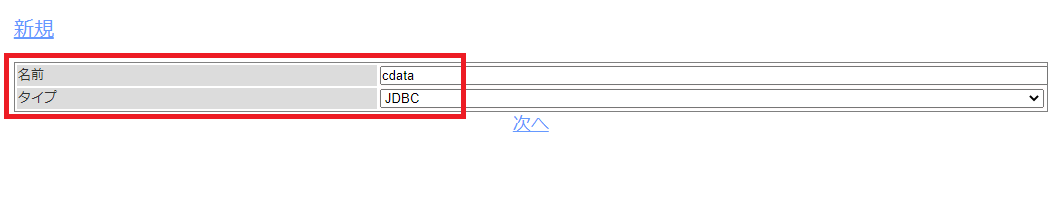
Neuron の管理画面(ローカルホストの場合は:http://localhost:7983/ncf-crawler-ui/)にアクセスし、リポジトリコレクション一覧に移動して「新規」をクリックします。
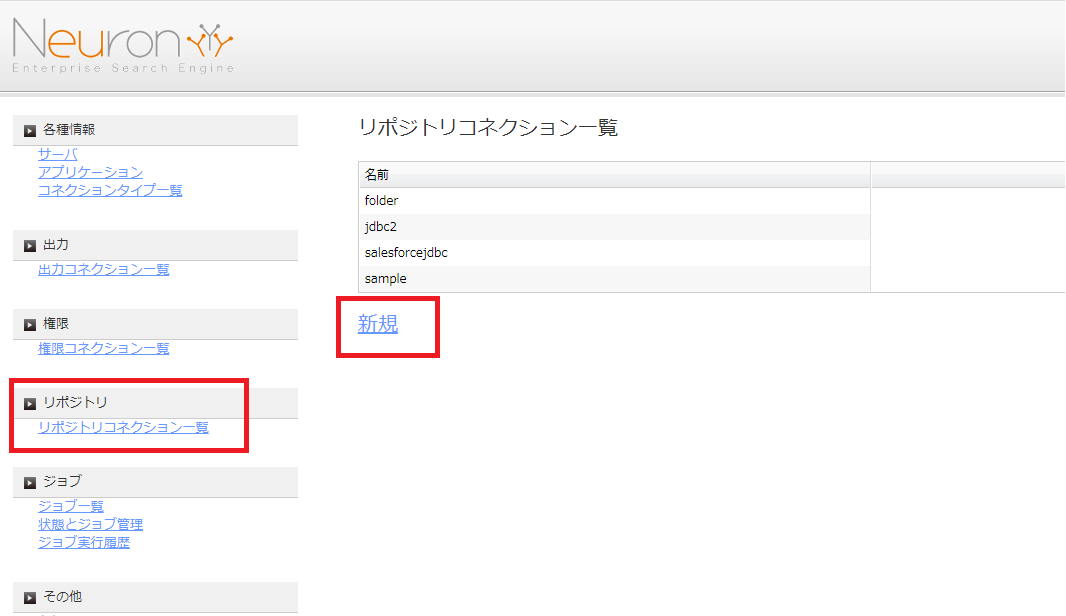
任意のリポジトリ名を入力し、タイプから「JDBC」を選択して、次へ移動します。
続いて、ドライバのクラス名とSalesforce へ接続するための接続文字列を設定します。接続文字列にはSalesforce へのログインユーザーID・PWと共にSalesforce から取得できるセキュリティトークンを指定します。(詳しい設定値はこちらを参照してください)
- ドライバクラス名:cdata.jdbc.salesforce.SalesforceDriver
- 接続文字列:jdbc:salesforce:User=XXX@XXXX.com;Password=XXXX;Security Token=XXXX;
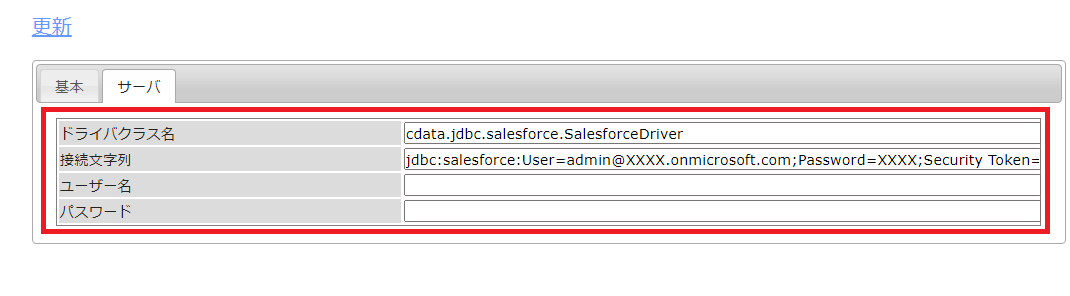
あとは「更新」をクリックすると、リポジトリコレクションが作成されます。
ジョブの構成
続いて実際にどのようにデータクローリングするのか? の定義であるジョブを構成します。
ジョブ一覧画面に移動して「新規」をクリックします。
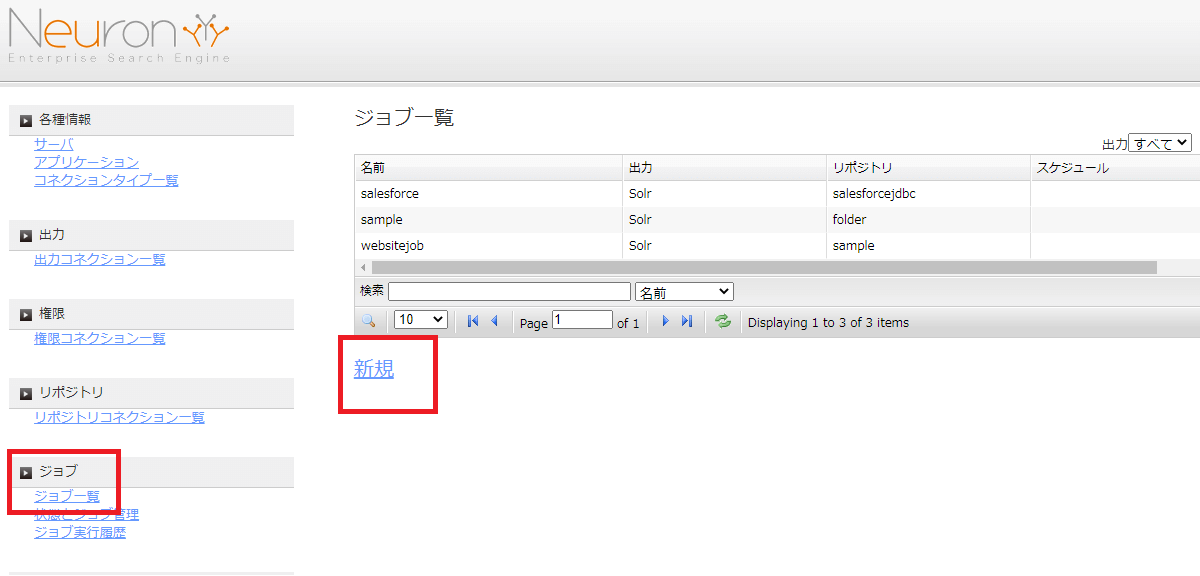
任意のジョブ名称を入力し、出力先としてSolr、リポジトリに先程作成したリポジトリコレクションを指定します。
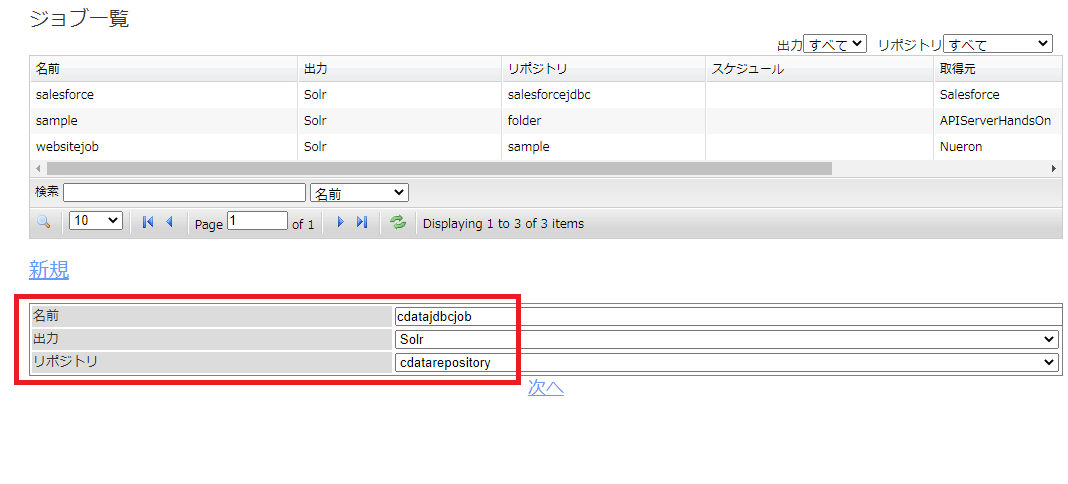
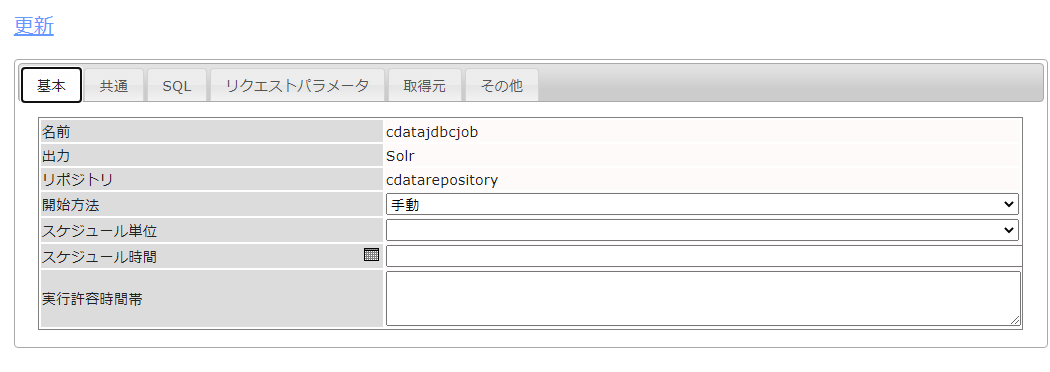
ジョブは定期的に実行するように構成することが可能です。今回は確認のため手動実行ジョブとしていますが、もし定期的にデータを取得する場合は、以下の基本タブでそれぞれ任意の構成を行ってください。
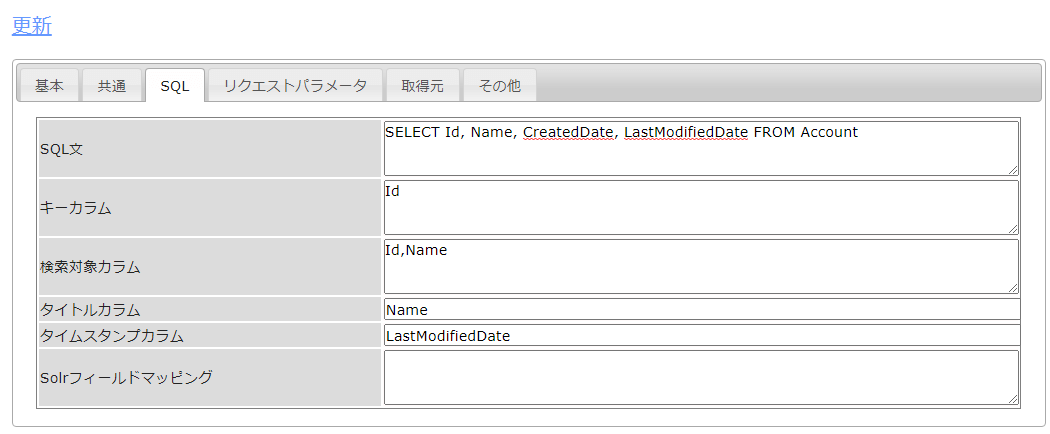
SQLタブでは、取得する先のテーブルをSQLや各種フィールドを指定します。今回は以下のようにAccountデータを取得するSQL文を構成しました。タイトルカラムや検索対象カラムは任意のカラムを指定してください。
- SQL文:SELECT Id, Name, CreatedDate, LastModifiedDate FROM Account
- キーカラム:Id
- 検索対象カラム:Id,Name
- タイトルカラム:Name
- タイムスタンプカラム:LastModifiedDate
(各プロパティの詳細な仕様はNeuronのリファレンスを参照してみてください。)
リクエストパラメータは、検索結果で表示されるリンクを定義することができます。
今回Neuronの検索結果からSalesforce の画面にスムーズに移動できるように、各レコードのリンクを構成するように設定しました。[Id]部分にそれぞれのレコードIDが入力されることで、リンクとして機能するようになります。

取得元では、ラベルとしてSalesforce を指定しました。

あとは「更新」をクリックすることでジョブが作成されます。
これでクローラーの設定は完了です。
ジョブの手動実行
それでは実際にジョブを実行してみましょう。
「状態とジョブ管理」画面に移動し、作成したジョブの「Start」をクリックします。
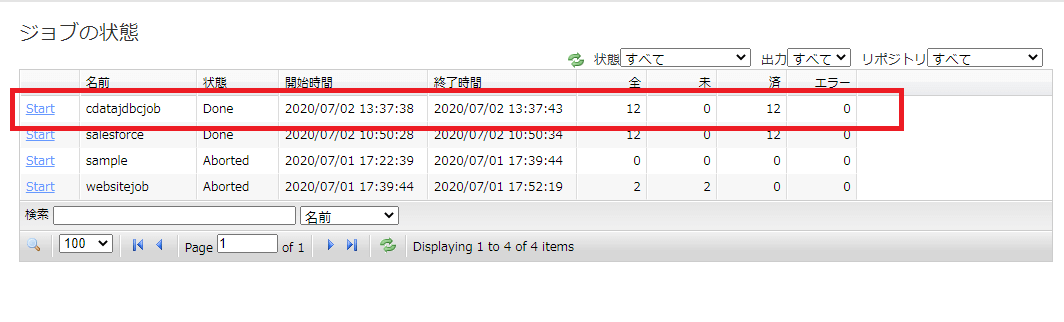
一定時間経過すると、ジョブが完了します。正常にジョブが完了すると、以下のように状態が「Done」で表示されます。今回は12件レコードが登録されました。
Neuron 上で検索の実施
実際にNeuron 上で検索ができるか確認してみます。
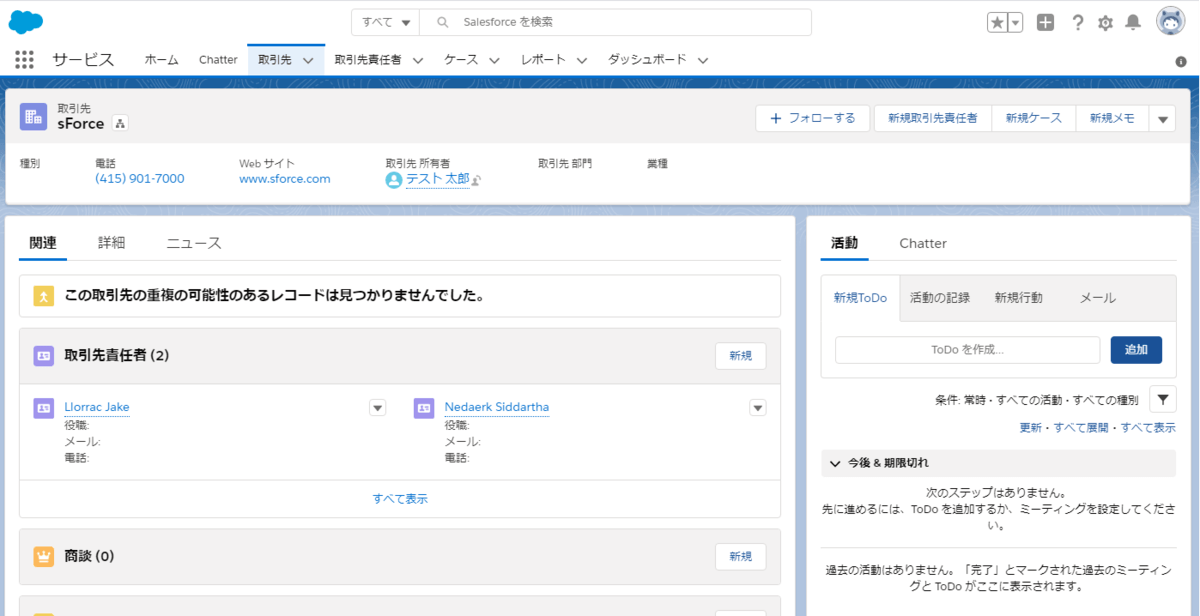
部分一致で検索をかけてみると、以下のようにデータを取得できました。またリンクをクリックすることで
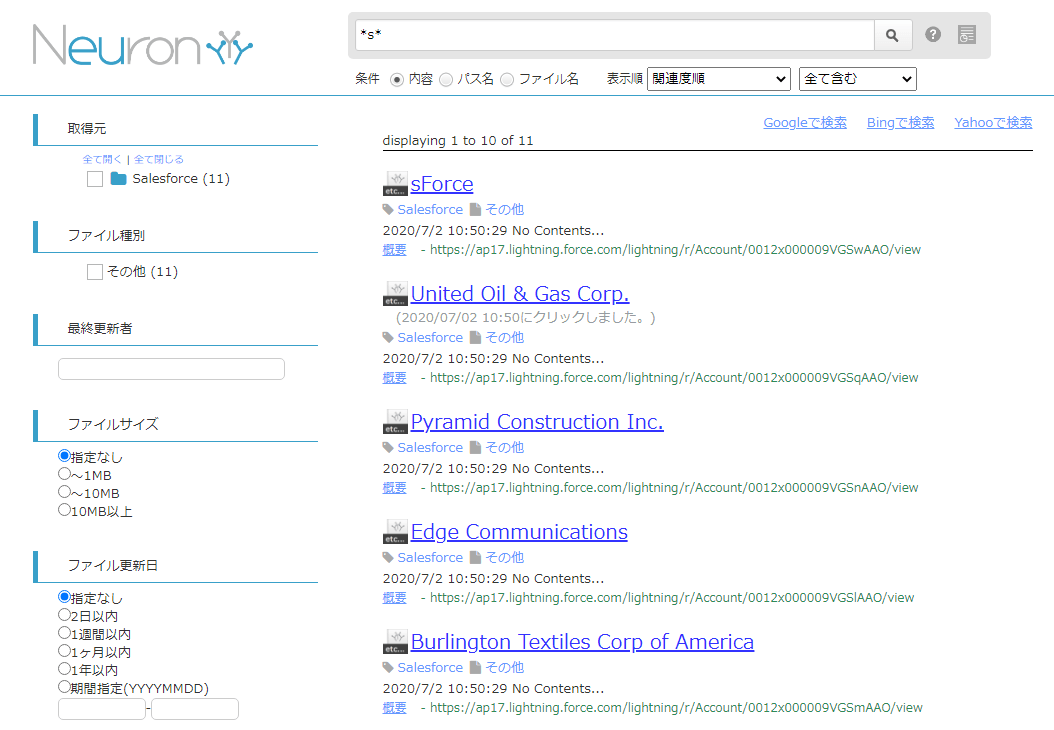
Salesforce 上の画面にも移動できました。
おわりに
とても手軽に Neuron で Salesforce のデータを扱えることがイメージできたのではないかと思います。
CData では Salesforce 以外にも数多くの JDBC Driver を提供しています。
kintone や Sansan といった日本のクラウドサービスや JIRA、Gmail などKBやナレッジが非定形で蓄積されているようなデータソースにも対応しているので、エンタープライズ検索の対象とすることでより業務効率化やコラボレーションの強化に活かせるのではないかと思います。
https://www.cdata.com/jp/jdbc/

すべて30日間のトライアルがあるので、是非一度試してみてください。