ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →






CData Sync 新機能 - dbt Core 統合機能

dbt Core 統合機能とは
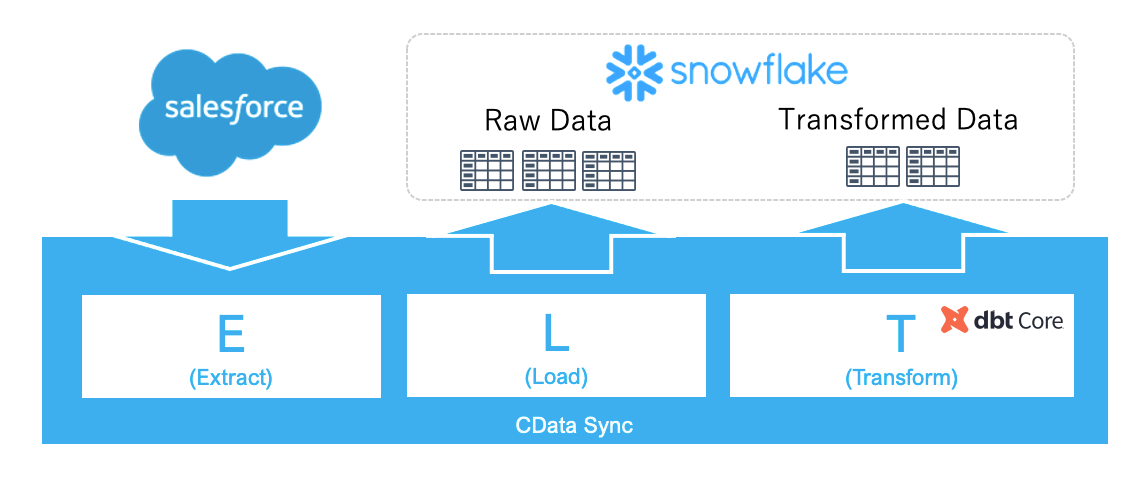
CData Sync は、ETL/ELT 方式のデータ統合基盤をノーコードで構築することができる製品です。CData Sync 製品のVersion22 より ELT処理の「T(Transform:データ変換)」機能で dbt Core プロジェクトを指定・実行できるようになりました。これによりCData Sync製品で400を超える多種多様なデータのデータ統合基盤(DataLake/DWH)への取り込みだけでなく、CData Sync からdbt プロジェクト内のテンプレート化されたSQL のコンパイルと実行が可能となり、モダンなデータモデリング環境の構築を実現することができるようになります。
dbt Cloud との連携方法はコチラ
本記事でご紹介するシナリオ
本記事では、Salesforce の商談(Opportunities)と注文(Orders)データをSnowflakeに収集して、CData Sync のdbt Core 統合機能を利用して変換した加工済みデータをSnowflake上にテーブルとして作成します。
前提
本手順では以下のソフトウェアを利用しています。
- Windows 10
- CData Sync 22.0.8286.0 ※dbt Core 統合機能はVersion.22からご利用いただけます
- dbt Core(1.2.1)、および、dbt-snowflake(1.2.0)
- Python 3.10.4 (上記dbt製品はpipでインストール)
- Salesforce Sales Cloud
- Snowflake (Azureインスタンス)
dbt のインストール
pipコマンドで、dbt Core、および、Snowflakeプラグインを以下コマンドでCData Syncのマシンにインストールします。
> pip install dbt-snowflake
インストールが完了したら以下コマンドで確認します。
> dbt --version Core: - installed: 1.2.1 - latest: 1.2.1 - Up to date! Plugins: - snowflake: 1.2.0 - Up to date!
dbt プロジェクトの作成
既に他マシンで作成したdbt プロジェクトが存在しているのであれば、本手順は不要です。今回は CData Sync と同じマシンでdbt プロジェクトの作成、および、dbt run で実行してからCData Sync 製品からも実行する流れで進めてみます。
dbt プロジェクトを作成するフォルダを作成します。今回は C:¥wrk 配下に作成しました。dbt init コマンドでウィザードに従ってSnowflake に接続するdbt プロジェクトを作成します。
> cd C:¥wrk
> dbt init cdata_dbt 05:33:33 Running with dbt=1.2.1 Which database would you like to use? [1] snowflake (Don't see the one you want? https://docs.getdbt.com/docs/available-adapters) Enter a number: 1 account (https://.snowflakecomputing.com): ****.east-us-2.azure user (dev username): **** [1] password [2] keypair [3] sso Desired authentication type option (enter a number): 1 password (dev password): role (dev role): SYSADMIN warehouse (warehouse name): DEMO_WH database (default database that dbt will build objects in): JP schema (default schema that dbt will build objects in): PUBLIC threads (1 or more) [1]: 1 05:36:45 Profile cdata_dbt written to C:\Users\****\.dbt\profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection. 05:36:45 Your new dbt project "cdata_dbt" was created! For more information on how to configure the profiles.yml file, please consult the dbt documentation here: https://docs.getdbt.com/docs/configure-your-profile One more thing: Need help? Don't hesitate to reach out to us via GitHub issues or on Slack: https://community.getdbt.com/ Happy modeling!
作成したdbt プロジェクトのフォルダ内を確認してプロジェクト設定ファイルである「dbt_project.yml」が作成されていることを確認します。
C:\wrk\cdata_dbt>ls -l total 5 ----------+ 1 ***** ***** 571 Sep 10 08:44 README.md d---------+ 1 ***** ***** 0 Sep 10 08:44 analyses ----------+ 1 ***** ***** 1369 Sep 13 14:33 dbt_project.yml d---------+ 1 ***** ***** 0 Sep 10 08:44 macros d---------+ 1 ***** ***** 0 Sep 10 08:44 models d---------+ 1 ***** ***** 0 Sep 10 08:44 seeds d---------+ 1 ***** ***** 0 Sep 10 08:44 snapshots d---------+ 1 ***** ***** 0 Sep 10 08:44 tests
また、models\exampleフォルダ配下にはサンプルのsqlファイルが2つ格納されています。
C:\wrk\cdata_dbt\models\example>ls -l total 3 ----------+ 1 ***** ***** 475 Sep 10 08:44 my_first_dbt_model.sql ----------+ 1 ***** ***** 115 Sep 10 08:44 my_second_dbt_model.sql ----------+ 1 ***** ***** 437 Sep 10 08:44 schema.yml
それでは、dbt runコマンドで上記サンプルのSQLファイルを実行してみます。dbtプロジェクトフォルダに移動してdbt run コマンドを実行します。Completed successfully が表示されれば成功です。
C:\wrk\cdata_dbt>dbt run 05:56:26 Running with dbt=1.2.1 05:56:26 Unable to do partial parsing because profile has changed 05:56:27 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 267 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics 05:56:27 05:56:31 Concurrency: 1 threads (target='dev') 05:56:31 05:56:31 1 of 2 START table model PUBLIC.my_first_dbt_model ............................. [RUN] 05:56:35 1 of 2 OK created table model PUBLIC.my_first_dbt_model ........................ [SUCCESS 1 in 3.66s] 05:56:35 2 of 2 START view model PUBLIC.my_second_dbt_model ............................. [RUN] 05:56:37 2 of 2 OK created view model PUBLIC.my_second_dbt_model ........................ [SUCCESS 1 in 1.89s] 05:56:37 05:56:37 Finished running 1 table model, 1 view model in 0 hours 0 minutes and 9.64 seconds (9.64s). 05:56:37 05:56:37 Completed successfully 05:56:37 05:56:37 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
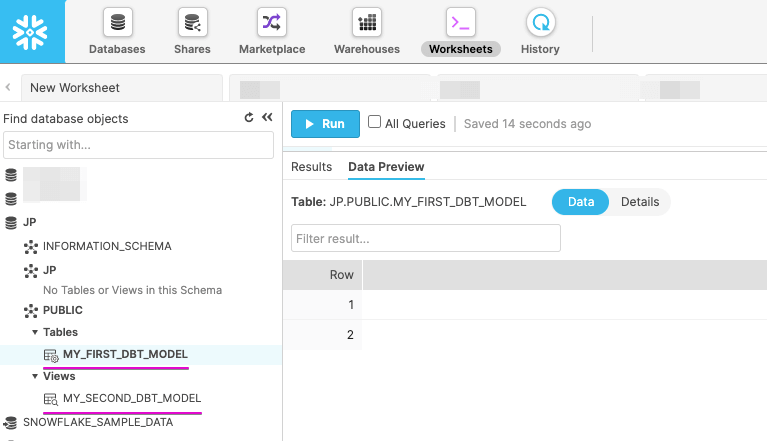
Snowflake のWorkSheets から作成されたテーブル(MY_FIRST_DBT_MODEL)、および、ビュー(MY_SECOND_DBT_MODEL)参照してみましょう。
CData Syncからの実行
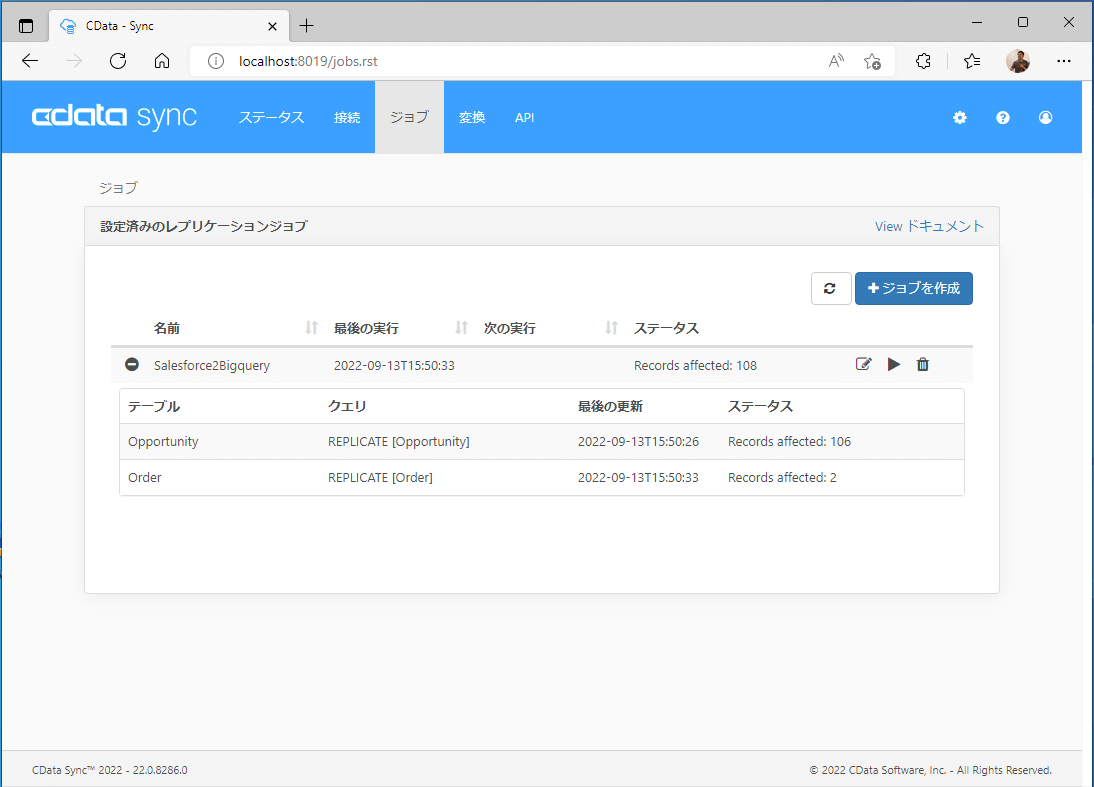
本手順では、CData Sync製品のインストール、および、Salesforce からSnowflake のジョブ作成については割愛いたします。詳細はこちらの記事をご参照ください。今回はSalesforce の商談(Opportunities)と注文(Orders)をSnowflake にレプリケートするジョブを作成しています。
Snowflake へのSalesforce データの自動反復レプリケーション
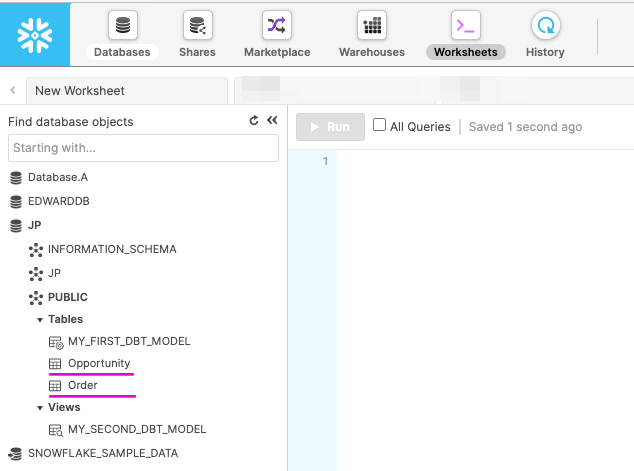
ジョブを実行してSnowflakeのWorksheetsで2つのテーブルが作成されていることを確認します。
今回のシナリオでは、商談(Opportunities)と注文(Orders)データの集計をUNION ALLで結合したデータを加工後データとして別テーブルに作成します。まず、Worksheetsのエディタで以下のSQLを実行してSQL自体が意図した結果を返すかを確認してください。
SELECT 'Opportunity' AS "Source", SUM("ExpectedRevenue") FROM "JP"."PUBLIC"."Opportunity"
UNION ALL
SELECT 'Order' AS "Source", SUM("TotalAmount") FROM "JP"."PUBLIC"."Order"
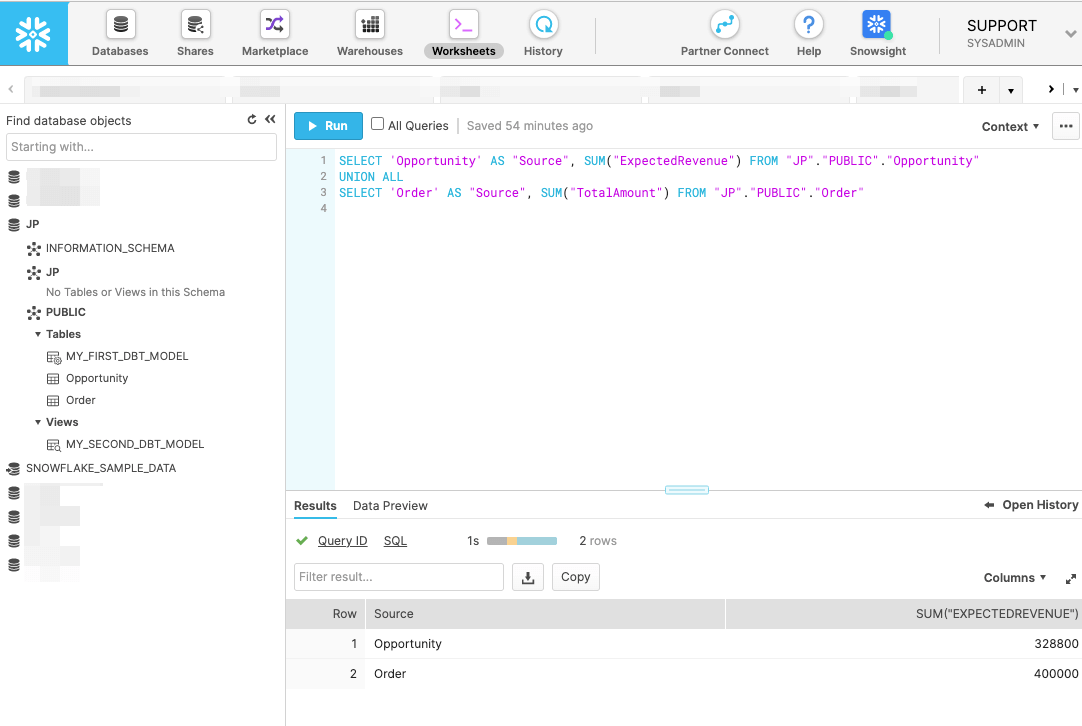
次に、上記SQL 文を組み込んだ SalesSummay.sql ファイルを作成します。
/*
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(materialized='table') }}
with source_data as (
SELECT 'Opportunity' AS "Source", SUM("ExpectedRevenue") FROM "JP"."PUBLIC"."Opportunity"
UNION ALL
SELECT 'Order' AS "Source", SUM("TotalAmount") FROM "JP"."PUBLIC"."Order"
)
select *
from source_data
/*
Uncomment the line below to remove records with null `id` values
*/
-- where id is not null
作成したらdbt プロジェクトのmodels フォルダ配下に格納します。
>cd C:\wrk\cdata_dbt\models >ls -l total 4 ----------+ 1 ***** ***** 604 Sep 9 20:44 SalesSummay.sql d---------+ 1 ***** ***** 0 Sep 10 08:44 example
次に、CData Sync の変換タブを開き、「+変換を作成」ボタンをクリックします。
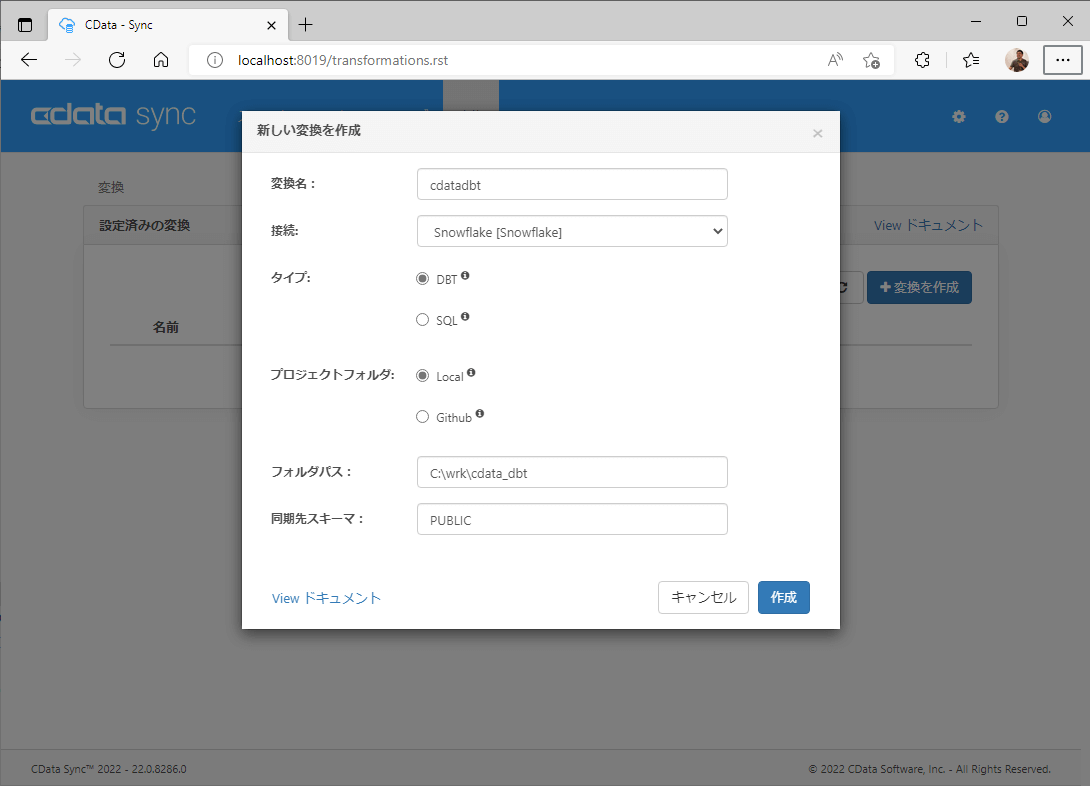
新しい変換を作成画面で以下の項目をセットして「作成」します。
- 変換名 : 任意(例:cdatadbt)
- 接続 : Snowflakeのコネクション(例:Snowflake[Snowflake])
- タイプ:DBT
- プロジェクトフォルダ:Local
- フォルダパス:dbt プロジェクトのパス(例:C:\wrk\cdata_dbt)
- 同期先スキーマ:Snowflakeのスキーマ(例:PUBLIC)
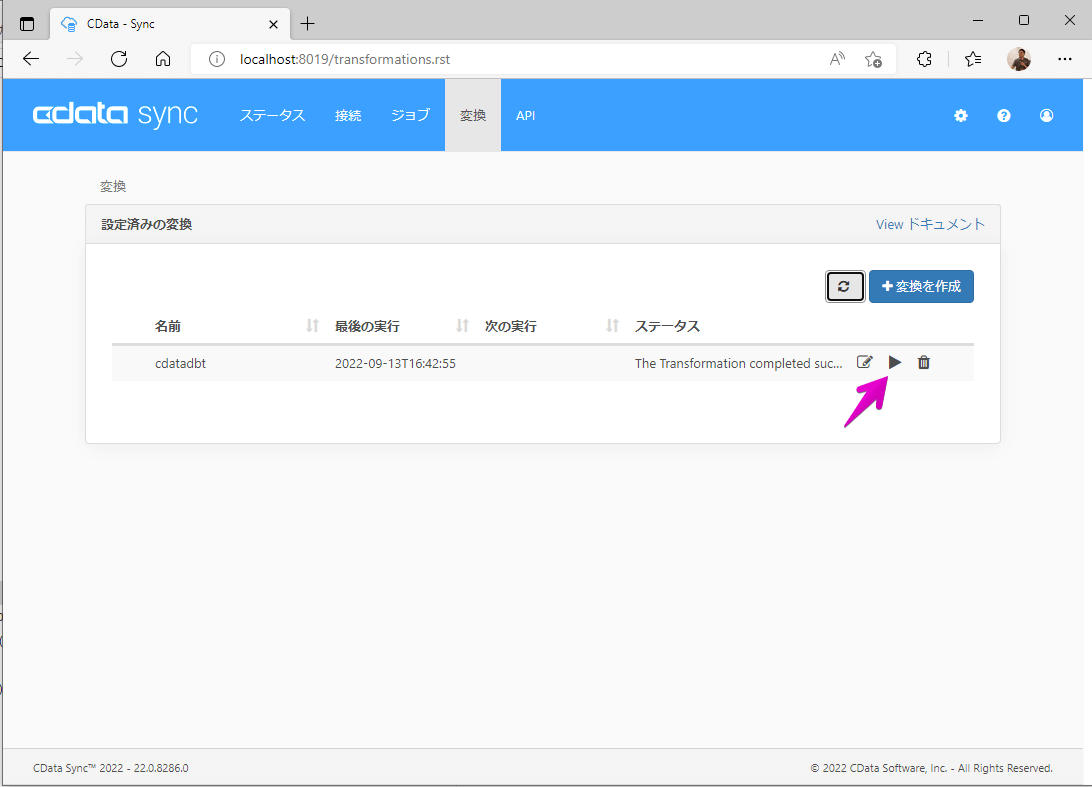
変換の一覧画面に戻り、作成した変換を▶︎ボタンで手動実行します。しばらくして「The Transformation completed successfully.」と表示されればCData Sync からのdbt プロジェクト実行は成功です。
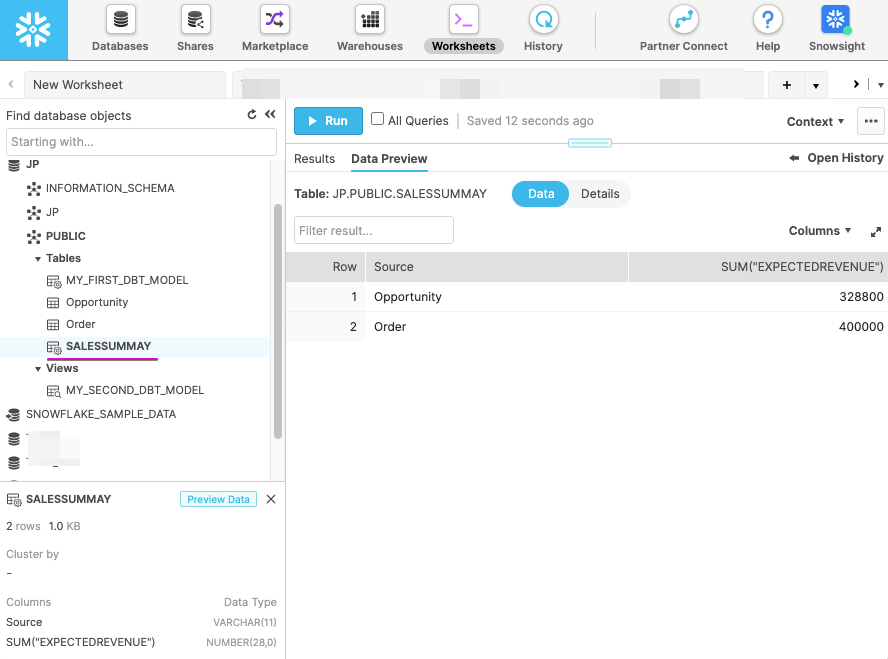
Snowflake のWorksheets からSALESSUMMAY テーブルが作成されていることを確認します。DataPreview で商談と注文の合計金額が格納されていることもか確認できます。
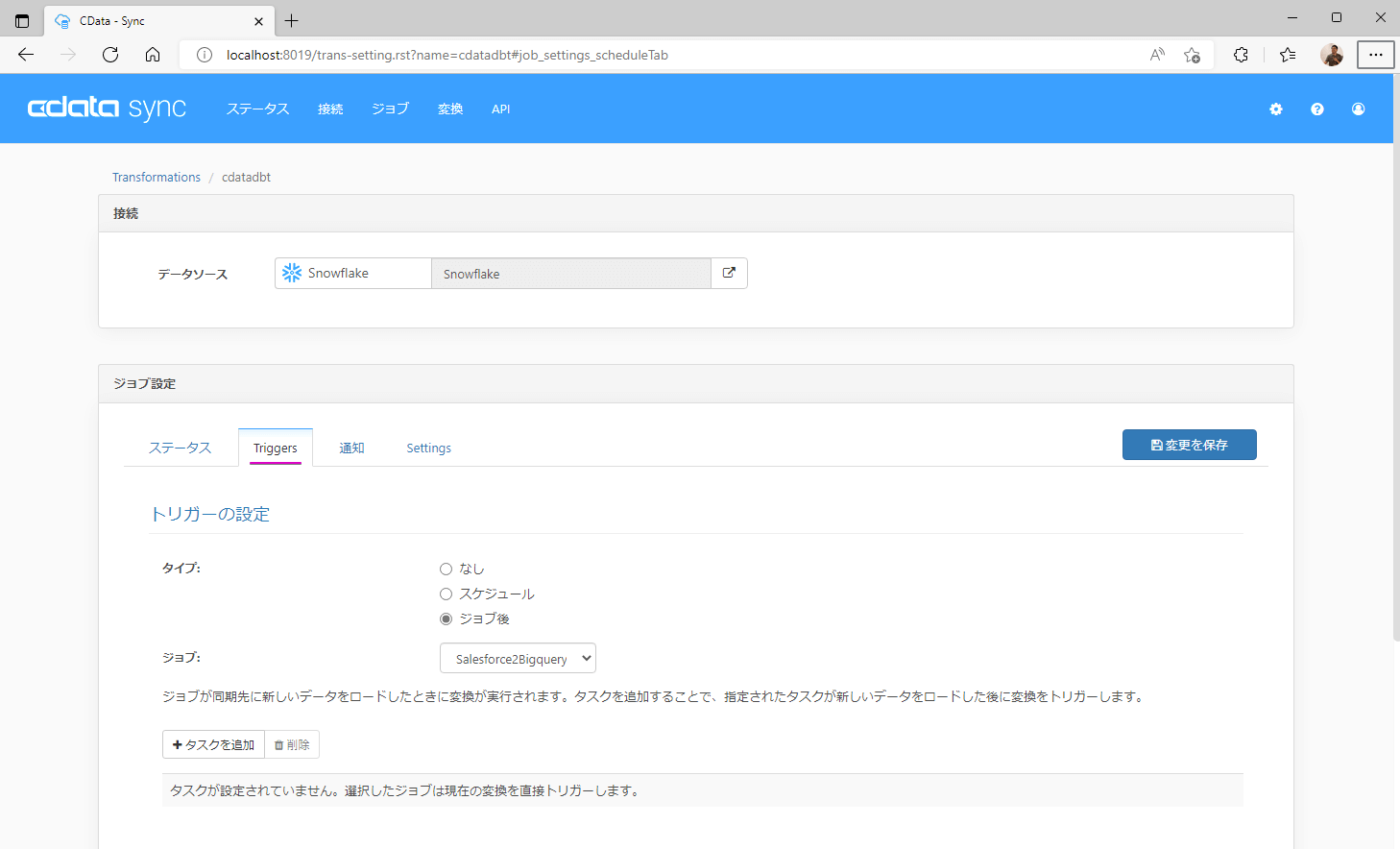
上記は手動で変換ジョブを実行してみましたが、変換のジョブ設定のTrigger タブより変換処理をジョブ(Salesforce データのSnowflake へのロード)の終了後に実行する設定も可能です。本設定によりEL(Extract & Load)後にT(Transform)処理も続けて実行することができます。
まとめ
本記事では、CData Sync でSalesforce のデータをSnowflake にロードした後にdbt プロジェクトを実行する例をご紹介しました。本機能を活用することで、CData Sync製品で400を超える多種多様なデータのデータ統合基盤(DataLake/DWH)への取り込みだけでなく、CData Sync からdbt プロジェクト内のテンプレート化されたSQL のコンパイルと実行が可能となり、モダンなデータモデリング環境の構築を実現することができるようになります。CData Sync 製品は以下のWebページより30日間の無償評価版も提供しておりますので是非お試しください。