ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →





CData Sync で日本郵政提供の郵便番号データをDB に取り込む

今回は、日本郵便株式会社で公開されている郵便番号と住所を対応させる郵便番号データを、CData Sync を使ってデータベースへ取り込む方法を紹介します。
1. 郵便番号データとは
日本郵政株式会社で公開されている全国の郵便番号と住所の一覧データです。
郵便番号データダウンロード - 日本郵便 (japanpost.jp)
2. KEN_ALL.ZIP とは
KEN_ALL.ZIP は、以前から公開されていた郵便番号データです。
CSV 形式ではあるものの、38文字を超えると複数行に分割されるなど、データ形式が複雑なため、そのままでは読み込むことができませんでした。
読み仮名データの促音・拗音を小書きで表記するもの - zip圧縮形式 日本郵便 (japanpost.jp)
3. utf_all.csvとは
utf_all.csv は、2023年6月より提供が開始された新しい形式の郵便番号データです。
以前のKEN_ALL.ZIP との主な違いは以下のようになっており、特に複数行に分割されていたレコードが1行になったことで、簡単に読み込めるようになりました。
- 38文字を超えると分割されていたレコードを1つに統合
- 読み仮名が半角カナから全角カナへ変更(※)
- 文字コードがShift-JIS から国際規格であるUTF-8 へと変更(※)
- 町域名に含まれていた補足説明の一部をフラグに整理
※ 政府CIO ポータル標準ガイドライン群の「文字環境導入実践ガイドブック」に準拠
4. CData Sync でutf_all.csv をSQL Server に取り込む
今回は、utf_all.csv をSQL Server に取り込んでみます。
郵便番号データは毎月更新されていますが、CData Sync のスケジュール機能を使用することで、自動的に最新の郵便番号データをSQL Server に同期することができるようになります。
4.1 コネクションの作成
1) utf_all.csv はCSV 形式で提供されているので、CSV コネクターを追加します。
CSV コネクターは、ローカルにあるファイルだけでなく、HTTP(HTTPS) やAmazon S3 、Box といった、様々な場所にあるCSV データにアクセスすることができます。
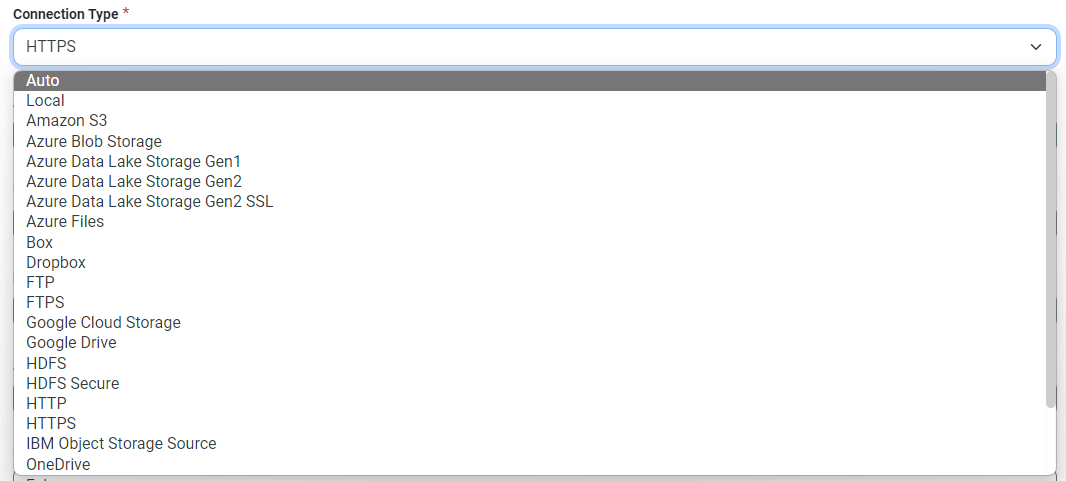
2) 接続先とオプションを設定します。
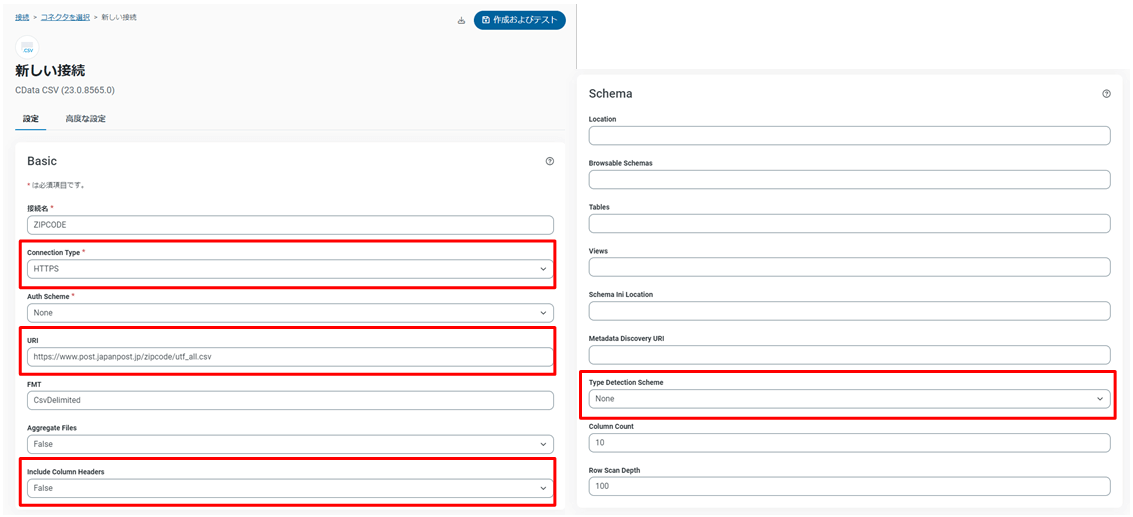
| 項目 | 設定値 |
| Connection Type | HTTPS |
| URI | ダウンロード先のURL https://www.post.japanpost.jp/zipcode/utf_all.csv |
| Include Column Headers (ヘッダー列の有無) |
False 今回使用するCSVファイルにはヘッダー列がないのでFalse を指定します。 |
| Type Detection Scheme (スキーマの型判定) |
None 手動で作成したスキーマ定義ファイル(*.rsd) を使用するので判定は「なし」に設定します。 |
4.2 スキーマ定義ファイルの作成
utf_all.csv はヘッダー項目がないためそのまま読み込むとカラム名がCol0, Col1 のようになります。
そこで、下記に記載されているファイル形式を参考にスキーマ定義ファイルを作成します。
郵便番号データの説明 - 日本郵便 (japanpost.jp)
~rsdファイル~
<api:script xmlns:api="http://apiscript.com/ns?v1" xmlns:xs="http://www.cdata.com/ns/rsbscript/2" xmlns:other="http://apiscript.com/ns?v1">
<api:info title="ZIPCODE" other:catalog="CData" other:schema="CSV" description="null" other:uri="C:\CDataJ\LocalTest\Sync\utf_all.csv" other:version="20">
<attr name="全国地方公共団体コード" xs:type="string" columnsize="6" description="全国地方公共団体コード(JIS X0401、X0402)" isnullable="true" other:internalname="Col0" />
<attr name="郵便番号5桁" xs:type="string" columnsize="5" description="(旧)郵便番号(5桁)" isnullable="true" other:internalname="Col1" />
<attr name="郵便番号7桁" xs:type="string" columnsize="7" description="郵便番号(7桁)" isnullable="true" other:internalname="Col2" />
<attr name="都道府県名カナ" xs:type="string" columnsize="20" description="全角カタカナ" isnullable="true" other:internalname="Col3" />
<attr name="市区町村名カナ" xs:type="string" columnsize="40" description="全角カタカナ" isnullable="true" other:internalname="Col4" />
<attr name="町域名カナ" xs:type="string" columnsize="1000" description="全角カタカナ" isnullable="true" other:internalname="Col5" />
<attr name="都道府県名" xs:type="string" columnsize="4" description="漢字" isnullable="true" other:internalname="Col6" />
<attr name="市区町村名" xs:type="string" columnsize="20" description="漢字" isnullable="true" other:internalname="Col7" />
<attr name="町域名" xs:type="string" columnsize="500" description="漢字" isnullable="true" other:internalname="Col8" />
<attr name="一町域が二以上の郵便番号で表される場合の表示" xs:type="int" description="「1」は該当、「0」は該当せず" isnullable="true" other:internalname="Col9" />
<attr name="小字毎に番地が起番されている町域の表示" xs:type="int" description="「1」は該当、「0」は該当せず" isnullable="true" other:internalname="Col10" />
<attr name="丁目を有する町域の場合の表示" xs:type="int" description="「1」は該当、「0」は該当せず" isnullable="true" other:internalname="Col11" />
<attr name="一つの郵便番号で二以上の町域を表す場合の表示" xs:type="int" description="「1」は該当、「0」は該当せず" isnullable="true" other:internalname="Col12" />
<attr name="更新の表示" xs:type="int" description="「0」は変更なし、「1」は変更あり、「2」廃止(廃止データのみ使用)" isnullable="true" other:internalname="Col13" />
<attr name="変更理由" xs:type="int" description="「0」は変更なし、「1」市政・区政・町政・分区・政令指定都市施行、「2」住居表示の実施、「3」区画整理、「4」郵便区調整等、「5」訂正、「6」廃止(廃止データのみ使用)" isnullable="true" other:internalname="Col14" />
</api:info>
<api:set attr="uri" value="[_connection.URI]" />
<api:script method="GET">
<api:call op="csvproviderGet">
<api:push/>
</api:call>
</api:script>
</api:script>
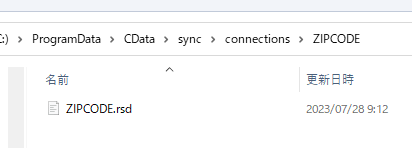
下記のようにconnections フォルダー内にあるコネクション名のフォルダーにrsdファイルをコピーします。
フォルダーは接続設定のLocation プロパティで指定することもできます。
4.3 実行
ジョブを実行するとutf_all.csv のデータがSQL Server へ同期されます。
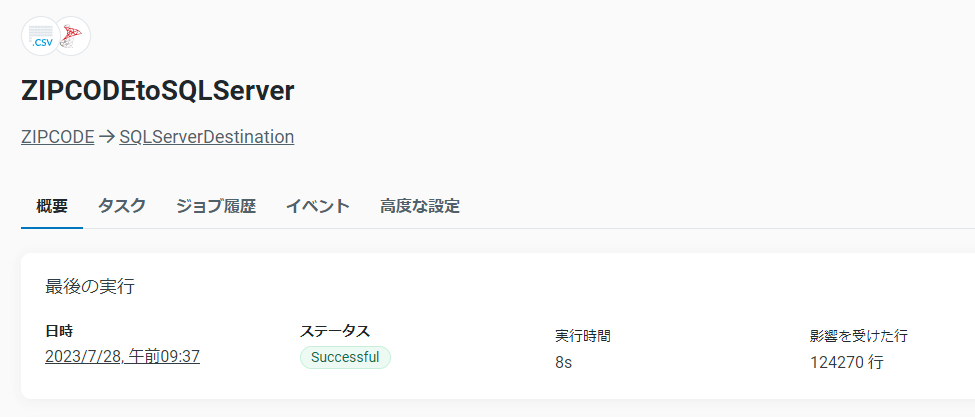
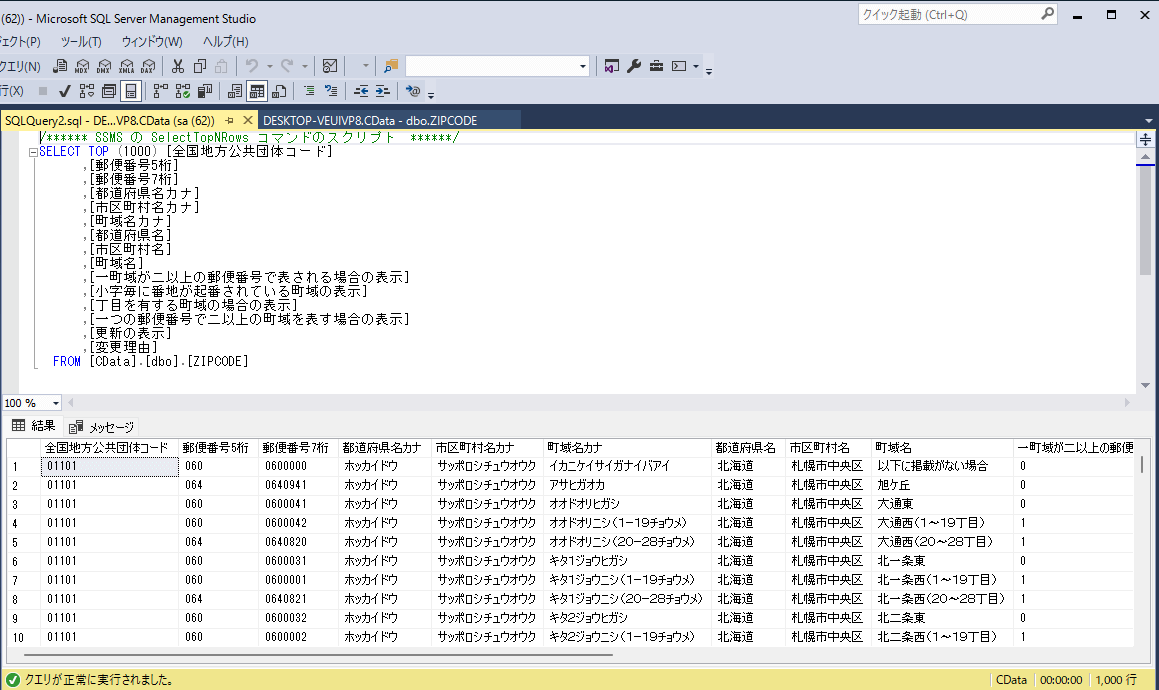
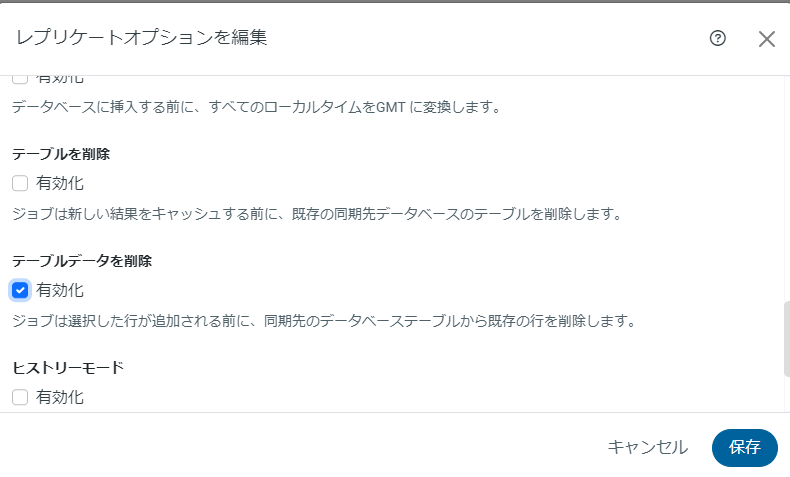
注意点として、郵便番号データにはキー項目がないためジョブオプションの「テーブルデータを削除」を有効にして、差分更新ではなく洗い替えで更新を行う必要があります。
5. まとめ
新しい郵便番号データが提供されるようになったことで、CData Sync を使って簡単に最新の郵便番号データをデータベースなどに同期することができるようになりました。
データのフォーマットも、依然と比べてかなり整理されて使いやすくなっていますので、ぜひこの仕組みを活用してみてください。