ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →






インフルエンサーのTwitterフォロワー数の推移をデータポータルで可視化!Twitter×CDataSync×BigQuery×データポータル
こんにちは、テクニカルサポートエンジニアの宮本です!
1日1回は何かしらの SNS でインフルエンサーが発信している情報を見る機会はないでしょうか?最近はインフルエンサーを使ったインフルエンサーマーケティングというのもあるようで、マーケティング手法としても非常に注目されているかと思います。
ja.wikipedia.org
で、そんなインフルエンサーと呼ばれる方々が、実際に日々どれくらいフォロワー数が増減しているのか?という少し変わった角度の分析を、データパイプラインツールの CData Sync × BigQuery × データポータルを使ってこんな感じでやってみました。
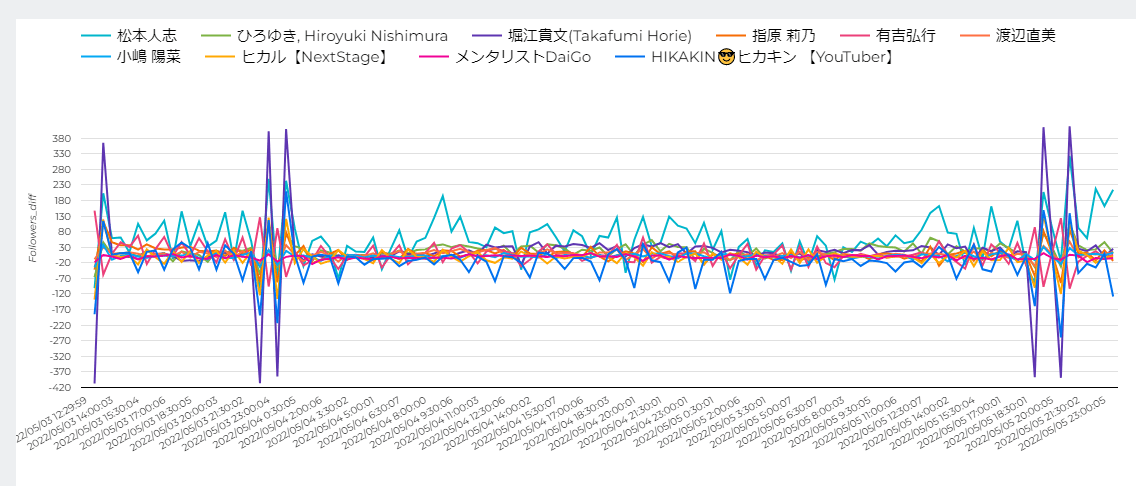
案外簡単に始められるのでやり方を本記事でご紹介いたします。
構成
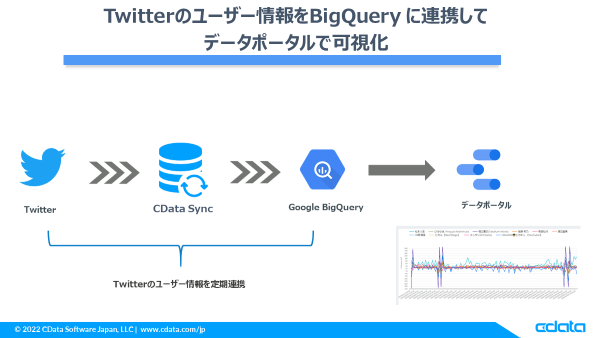 データの流れは Twitter → BigQuery になり、間にデータパイプラインツールの CData Sync を置いて定期的にデータを連携する構成としています。
データの流れは Twitter → BigQuery になり、間にデータパイプラインツールの CData Sync を置いて定期的にデータを連携する構成としています。
具体的には取得したいTwitter アカウント(今回は複数のインフルエンサー)のTwitterアカウント名を用いて、CData Sync から複数のユーザー情報を一気に取得し、そのまま BigQuery に連携します。
この時、連携ジョブ実行時の日時情報を付加して、BigQueryに時系列でデータを保持 → データポータルでフォロワー数の増減を可視化までを行います。
CData Sync とは
CData Sync は上記でも書いてあるようにセルフホスティング or AWS での提供のETL/ELT ツールになります。
同期ジョブを実行するまでのステップが少なく、エンジニアでなくても容易に SaaS データを同期先 DB にレプリケートすることができます。
それではさっそくやっていきましょう。
必要なもの
- 自身のTwitterアカウント
- データを送る先となる BigQuery のデータセット
- データポータル
- CData Sync *30日間はトライアル利用可能
手順
CData Sync 準備
CData Sync のインストール&LINE WORKS コネクタインストール CData Sync をインストールします。インストール~アクティベート、また使い方などはこちらのハンズオン記事をご参照ください。
https://www.cdata.com/jp/blog/2022-02-10-174821
CDataSyncからTwitterへの接続設定
接続設定画面を開き、Twitter アイコンをクリックします。もし表示されていない場合は緑枠の「Add More」から Twitter コネクタをインストールしてください。

Twitter への接続設定画面を開いたら、名前の部分に任意の接続設定名を設定し、「次に接続ボタン」をクリックします。
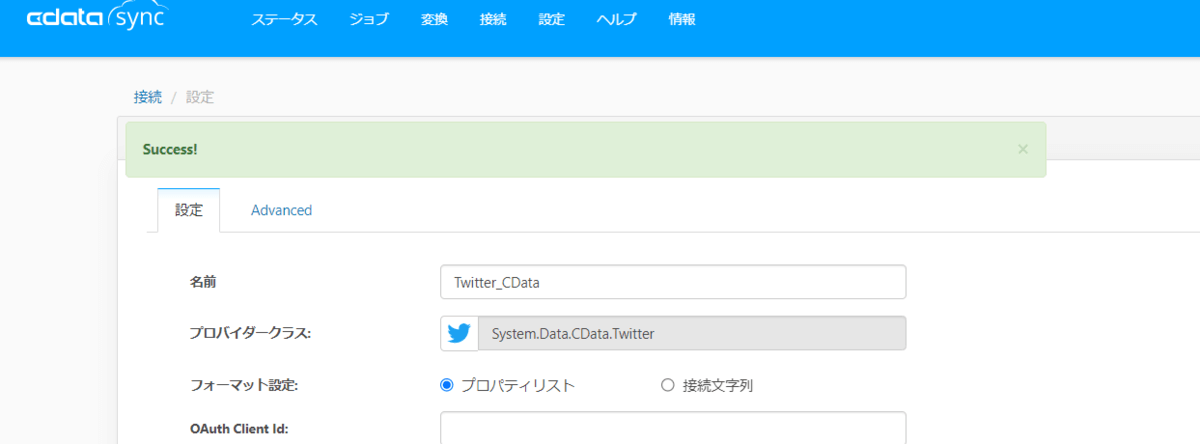
CData Sync からTwitter への接続許可を行います。
Twitter への接続ができると「Success!」のメッセージが表示されますので接続設定を保存します。
CDataSyncからBigQueryへの接続設定
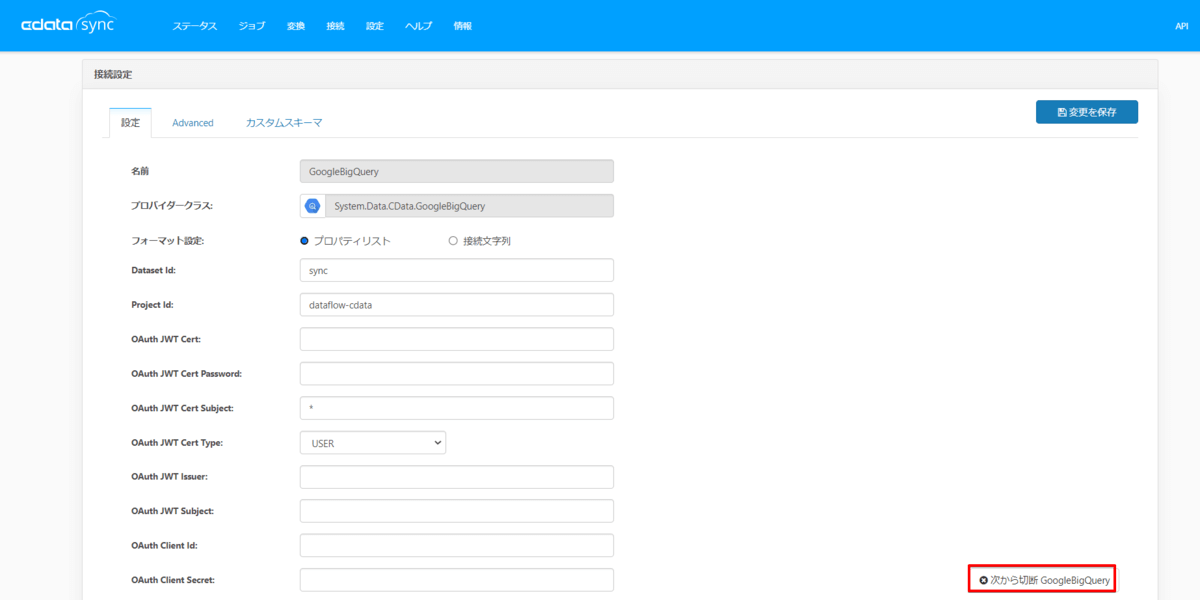
BigQuery の場合にはユーザーアカウントによるOAuth認証と、サービスアカウントでの接続方法がありますが、今回はOAuth認証で行いますので、データセットID とプロジェクトID を指定しましたら、右下にある接続ボタンをクリックして認証を完了してください。
同期ジョブ作成
今回は以下のインフルエンサーに限定してフォロワー数を定期的に取得していきたいと思います。
| No | 名前 | Twitter ユーザー名 |
|---|---|---|
| 1 | HIKAKIN | hikakin |
| 2 | ひろゆき | hirox246 |
| 3 | 堀江貴文 | takapon_jp |
| 4 | 渡辺直美 | watanabe_naomi |
| 5 | 松本人志 | matsu_bouzu |
| 6 | メンタリストDaiGo | Mentalist_DaiGo |
| 7 | 指原莉乃 | 345__chan |
| 8 | ヒカル | kinnpatuhikaru |
| 9 | 小嶋陽菜 | kojiharunyan |
| 10 | 有吉弘行 | ariyoshihiroiki |
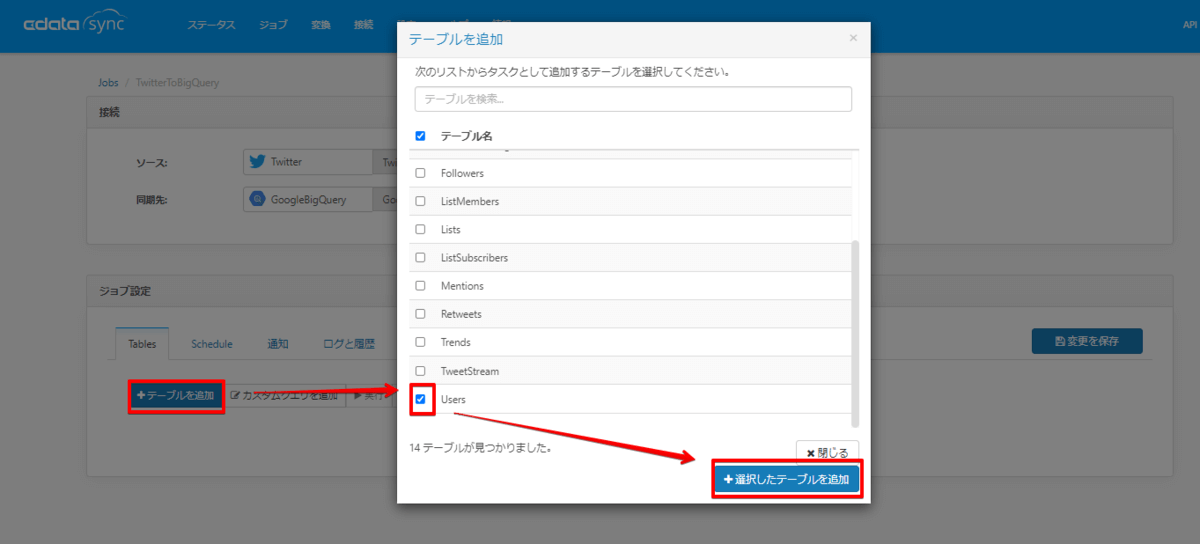
ではジョブ画面にて データソース:Twitter 、同期先:BigQuery で新規ジョブを作成します。
次に「テーブルを追加」をクリックし、Users テーブルを選択すると、
自動的にUsersテーブルの連携クエリができました。
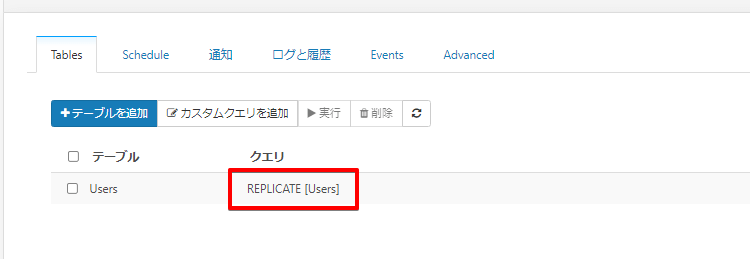
しかし、UsersテーブルはユーザーIDやユーザー名を指定することで初めてユーザー情報を取得できるようになりますので、対象インフルエンサーを指定したクエリを作成していきたいと思います。
CData JDBC Driver for Twitter - Users
ユーザーIDの取得よりはユーザー名の方がすぐに確認できるので、今回は少し上の表に載せたユーザー名をINで指定してフォロワー数を取得したいと思います。
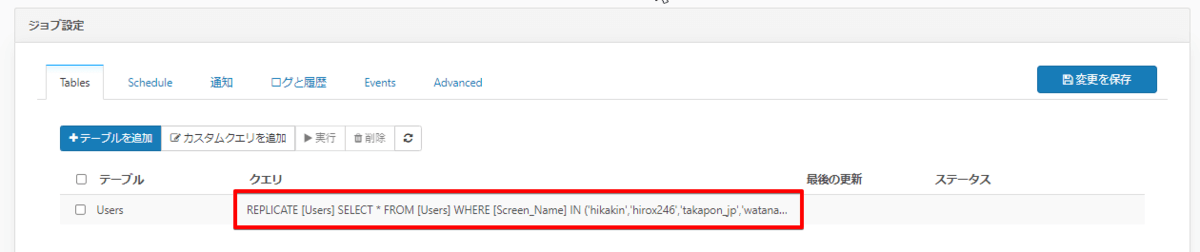
SELECT * FROM [Users] WHERE [Screen_Name] IN ('hikakin','hirox246','takapon_jp','watanabe_naomi','matsu_bouzu','Mentalist_DaiGo','345__chan','kinnpatuhikaru','kojiharunyan','ariyoshihiroiki')
次に上記クエリを自動生成された「REPLICATE~」の末尾にくっつけます。(REPLICATE [XXXX] の部分は同期先DBに作成するテーブル名なので、Users以外の別名を指定することも可能)
REPLICATE [Users] SELECT * FROM [Users] WHERE [Screen_Name] IN ('hikakin','hirox246','takapon_jp','watanabe_naomi','matsu_bouzu','Mentalist_DaiGo','345__chan','kinnpatuhikaru','kojiharunyan','ariyoshihiroiki')
ジョブ実行
それでは作成したジョブを実行していきましょう。
左側にあるチェックを入れて実行ボタンをクリックします。
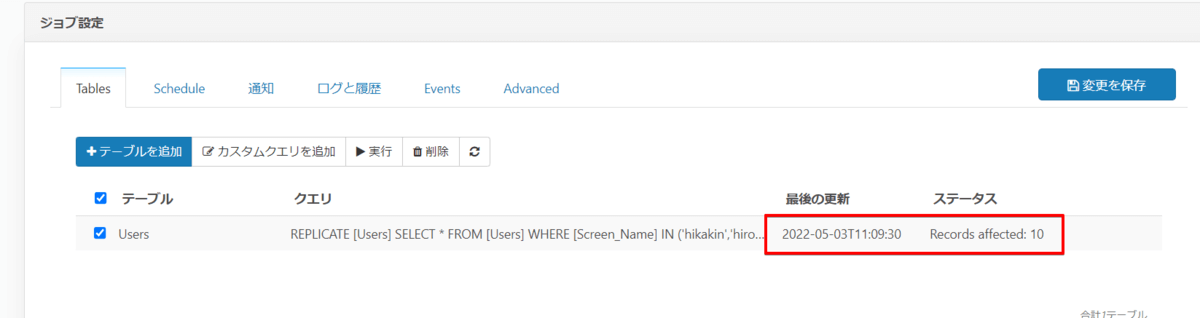
ジョブ実行が完了すると実行日時と連携件数が表示されます。今回は10名のインフルエンサーのフォロワー数などのユーザー情報を連携しましたので、10レコードの連携のみとなります。
ジョブ実行が完了したので連携先の BigQuery を確認してみます。対象のデータセットを開くとUsers というテーブル名が作成されており、中を開くと各インフルエンサーの情報が格納されているのが確認できました。
なお、赤枠部分がフォロワー数になります。
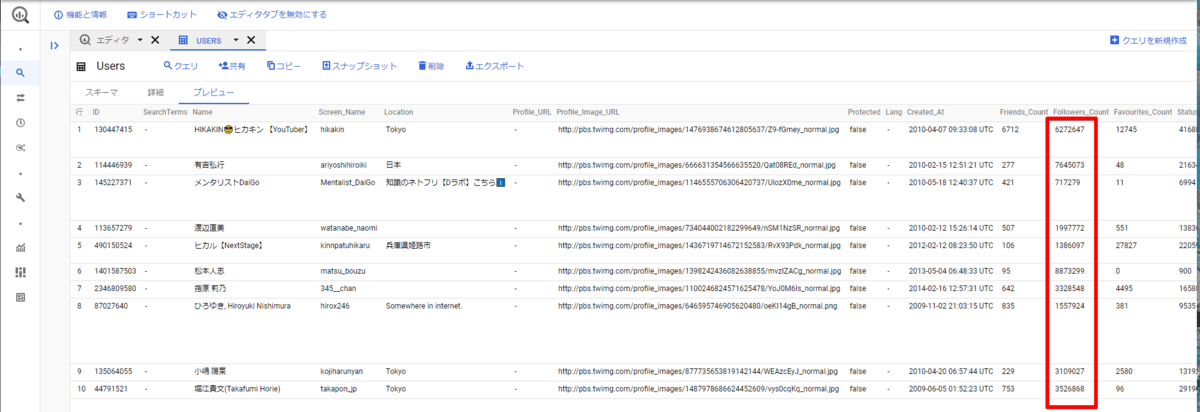
これで指定した Twitter ユーザー情報をBigQuery に連携できました。
時系列でデータを保持する方法
上記ジョブを定期実行することでフォロワー数などのユーザー情報を蓄積することができますが、可視化するうえではジョブ実行日時などでグルーピングしたいかと思います。その場合はジョブ実行日時を保持するカラムを追加して、時系列でデータを保持することも可能です。
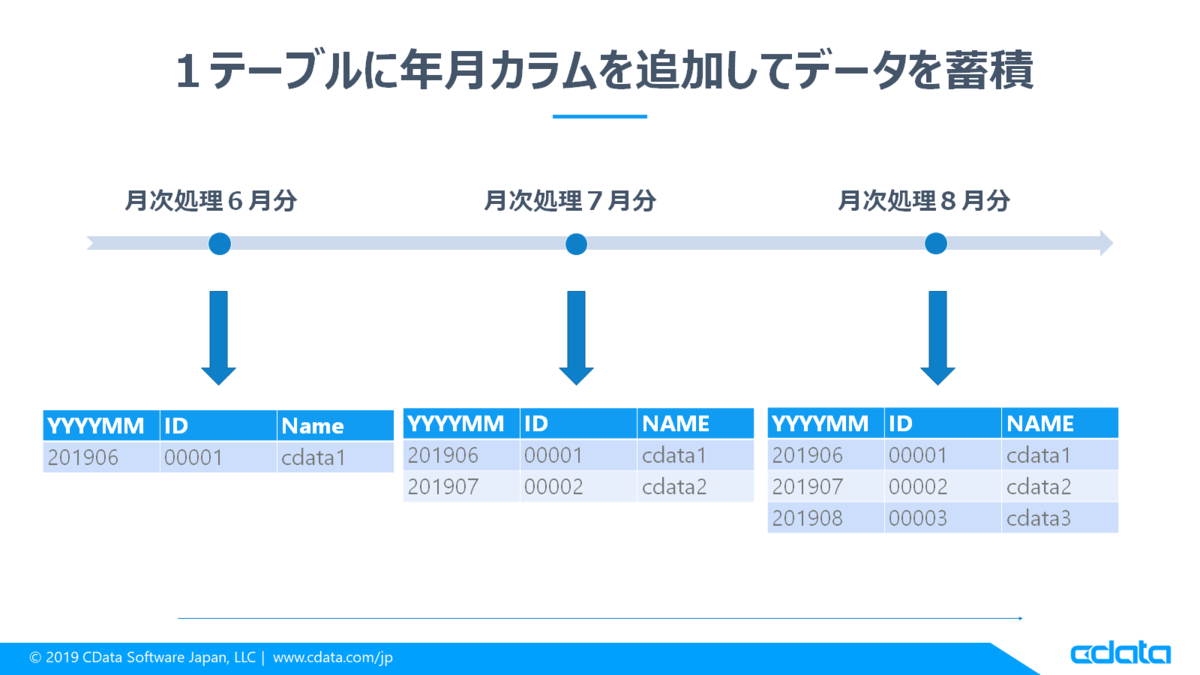
実行日時保持用のカラムを追加する方法は、CDataSyncの環境変数を使用します。
環境変数の設定
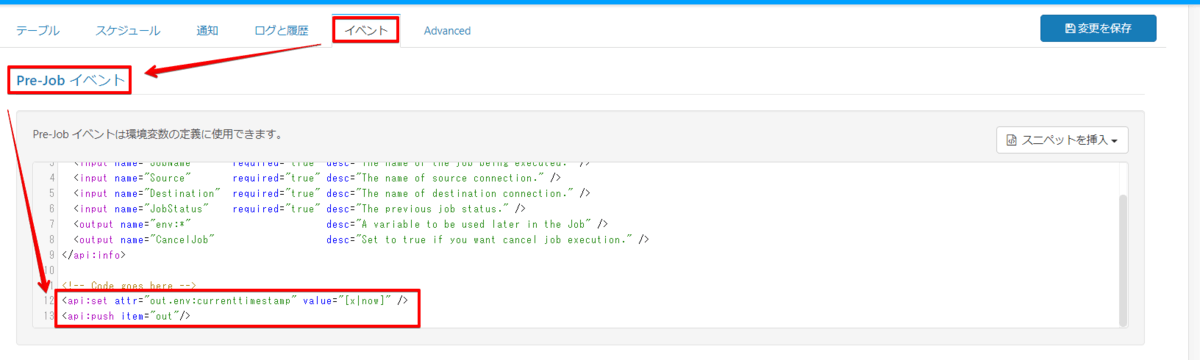
「Events」の「Pre-Job イベント」に下記コードを追加します。
<api:set attr="out.env:currenttimestamp" value="[x|now]" /> <api:push item="out"/>
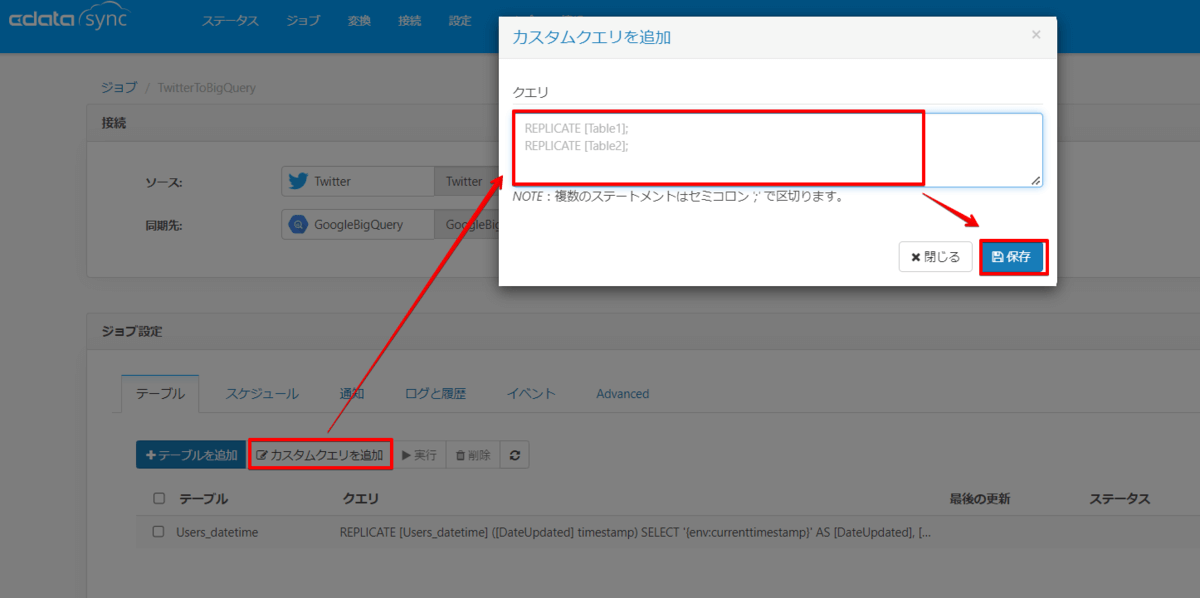
連携クエリの設定
「カスタムクエリを追加」ボタンを押して下記クエリを登録します。
クエリの解説は後ほど行います。
REPLICATE [Users_datetime] ([DateExecuted] timestamp) SELECT '{env:currenttimestamp}' AS [DateExecuted], [ID], [Name], [Description], [Followers_Count], [Contributors_Enabled], [Created_At], '{env:currenttimestamp}' AS [DateUpdated], [Default_Profile], [Default_Profile_Image], [Favourites_Count], [Follow_Request_Sent], [Following], [Friends_Count], [Geo_Enabled], [Is_Translator], [Lang], [Listed_Count], [Location], [Notifications], [Profile_Background_Color], [Profile_Background_Image_Url], [Profile_Background_Image_Url_Https], [Profile_Background_Tile], [Profile_Image_URL], [Profile_Image_Url_Https], [Profile_Link_Color], [Profile_Sidebar_Border_Color], [Profile_Sidebar_Fill_Color], [Profile_Text_Color], [Profile_URL], [Profile_Use_Background_Image], [Protected], [Screen_Name], [SearchTerms], [Show_All_Inline_Media], [Statuses_Count], [Time_Zone], [Url], [UTC_Offset], [Verified] FROM [Users] WHERE [Screen_Name] IN ('hikakin', 'hirox246', 'takapon_jp', 'watanabe_naomi', 'matsu_bouzu', 'Mentalist_DaiGo', '345__chan', 'kinnpatuhikaru', 'kojiharunyan', 'ariyoshihiroiki')
保存ボタン押下後
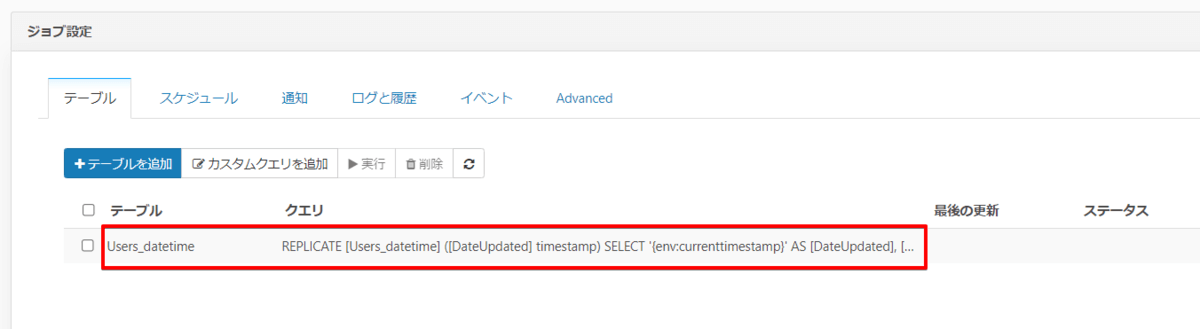
これでジョブ実行日時を保持したクエリができましたので、先ほどと同じようにジョブを実行することで、実行日時を保持した内容で BigQuery に連携できました。
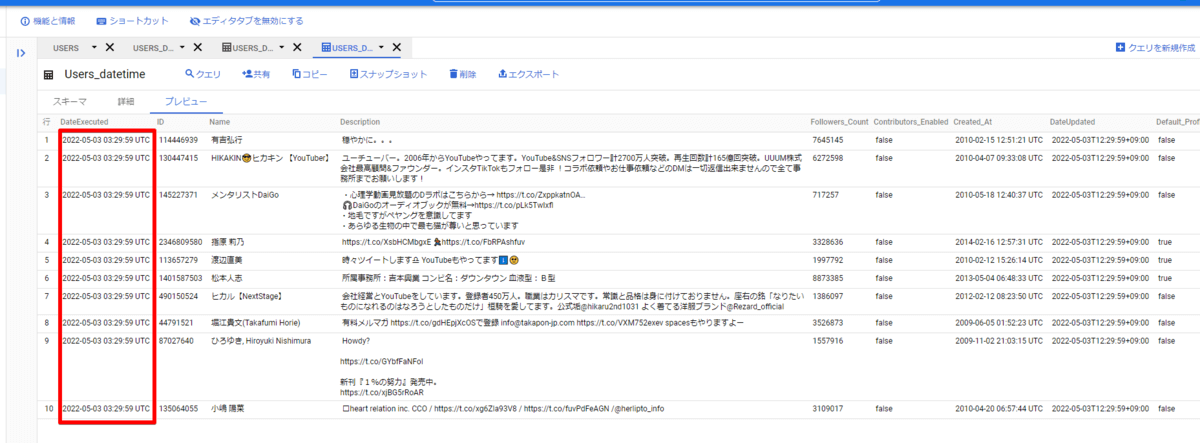
あとはスケジューリング実行することで時系列でデータがBigQueryに蓄積されるようになります。
時系列でデータを保持するときのポイント
今回作成したクエリについてですが、2つほどポイントがあります。
1つ目:CDataSyncの環境変数をSELECT句に追加
SELECT '{env:currenttimestamp}' AS [DateExecuted], [ID], [Name], ~
上記のような指定方法で環境変数を追加することができますので、日時以外のデータも追加することが可能です。
2つ目:データ型を指定
REPLICATE [Users_datetime] ([DateExecuted] timestamp) ~
デフォルトではSTRINGで定義されますが、REPLICATE句のところで (項目名 データ型) の形式で指定すると、STRING以外の型で同期先に項目を追加することが可能です。
データポータルでフォロワー数可視化
では最後に各インフルエンサーのフォロワー数をデータポータルで可視化していきましょう!
BigQuery でビューを作成
現状ではジョブを実行したタイミングのデータを保持しているので、ジョブ実行ごとでフォロワー数は連携しています。しかし、インフルエンサーの場合はフォロワー数が多すぎるために日々どれくらいフォロワー数が増減したかがグラフでは確認しづらいです。加えて複数人で比べているので余計にx軸の範囲が広くなり、もはや線は直線でしか表現されません。
※無加工でフォロワー数の推移を可視化した場合
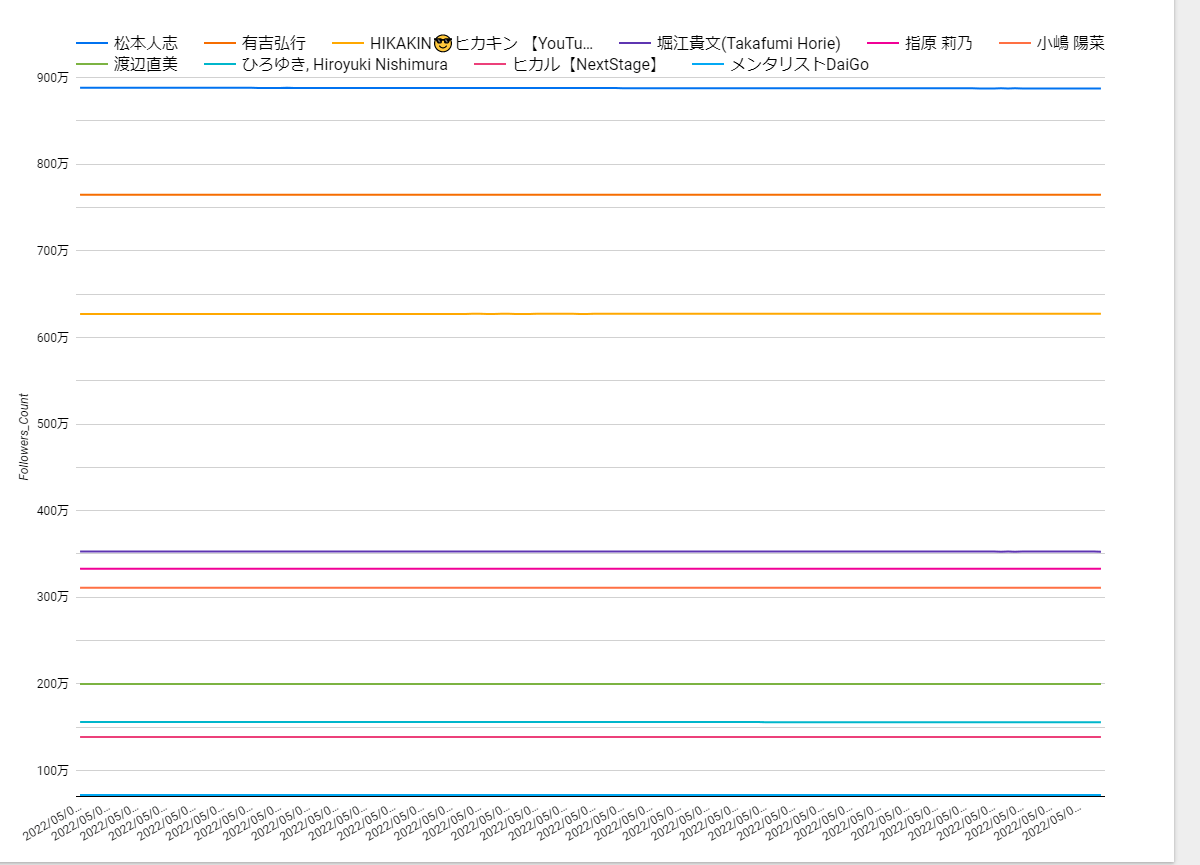
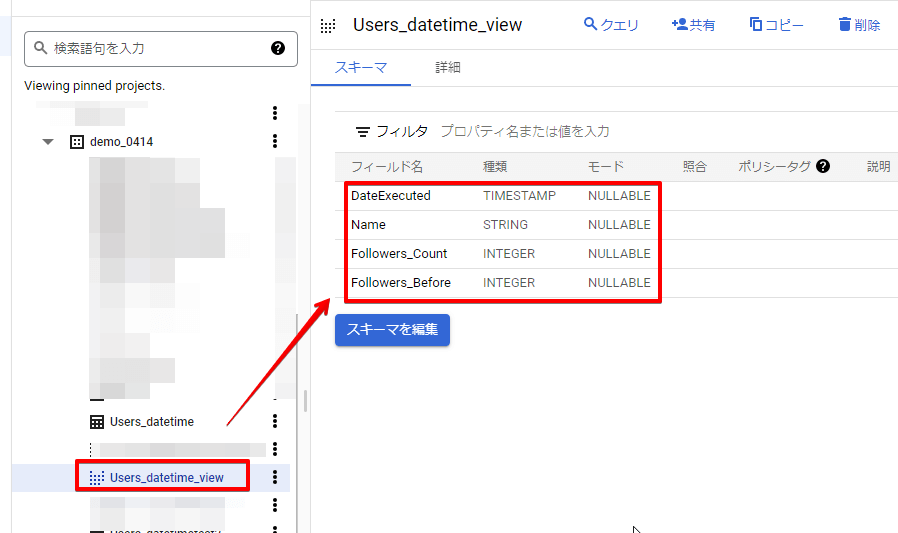
なので、ジョブ実行ごとに前回のフォロワー数を保持したカラムを定義したビューを作成します。
BigQuery でビュー作成時のクエリはLAG関数を使った以下内容としました。
SELECT DateExecuted,Name,Followers_Count, LAG (Followers_Count, 1) OVER (PARTITION BY Name ORDER BY DateExecuted) AS Followers_Before FROM `dataflow-cdata.demo_0414.Users_datetime` order by DateUpdated, Id
LAG 関数を用いてTwitterアカウントごとに前回のフォロワー数を保持するようにします。
ではクエリを実行してビューとして保存します。
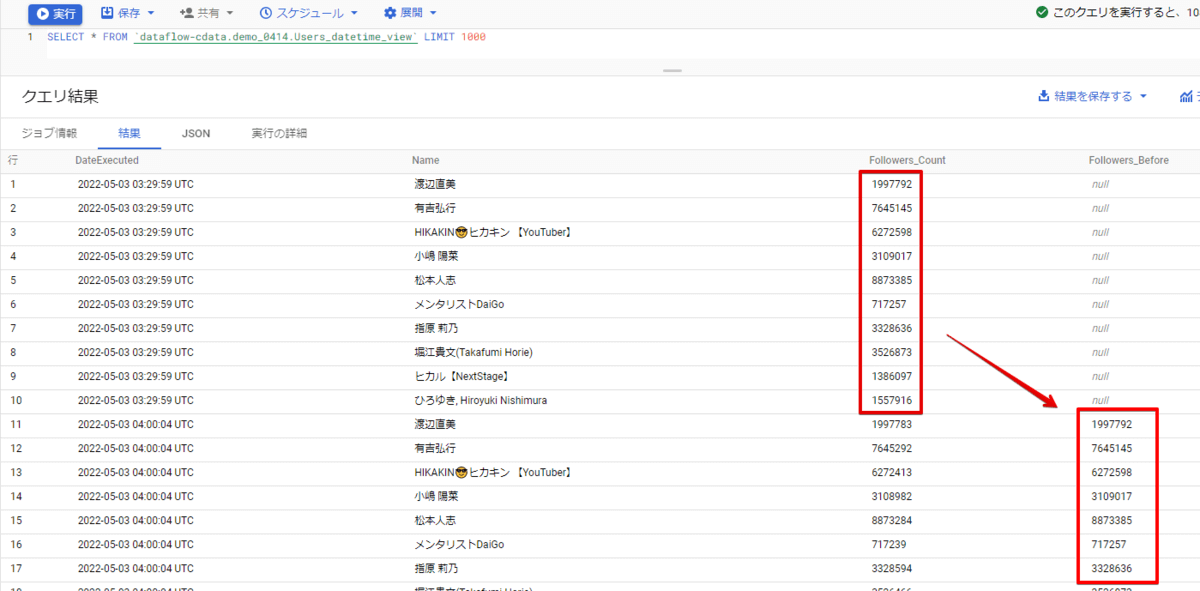
これで前回ジョブ実行したときのフォロワー数を保持することができました。
データソースにBigQueryの連携先テーブルを追加
データポータルを開き、作成からデータソースをクリックします。
BigQuery を選択し、先ほど作成したビューを選択します。
次に下記項目を新たに追加します。
ジョブ実行日時をJSTに変換した項目フォロワー数の差分を計算する項目
UTCの日時データをJSTに変換
フィールドを追加ボタンをクリックします。
計算式に以下を設定して保存します。
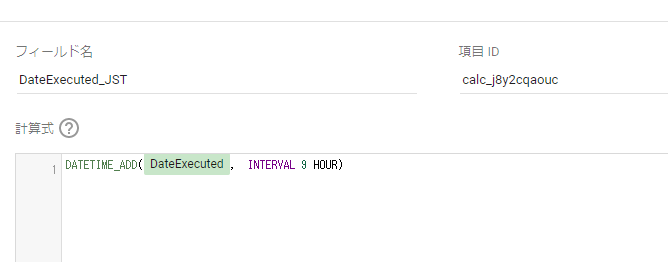
DATETIME_ADD(DateExecuted, INTERVAL 9 HOUR)
フォロワー数の差分算出
こちらも同様にフィールド追加を行います。計算式は以下のとおりです。
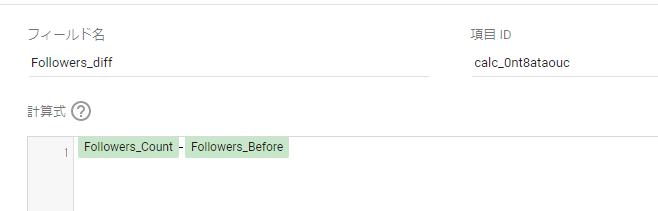
Followers_Count-Followers_Before
これでデータポータル側の準備が終わりました!
では最後にグラフにしてみてみます。
フォロワー数の増減を可視化してみる
日付をGWの5/3~5/5 の範囲を対象に折れ線グラフと表で確認していきます。
ディメンションにDateExecuted_JST(ジョブ実行日時)、Name(Twitterアカウント名)、指標には Followers_diff(フォロワー数の前回との差) を指定してみると、このように各インフルエンサーのフォロワー数増減を確認することができました。
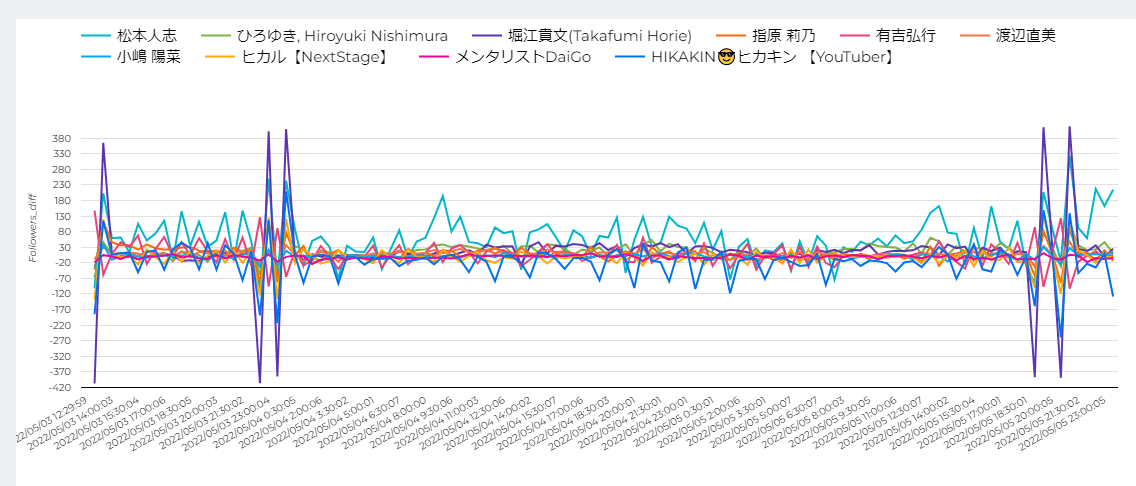
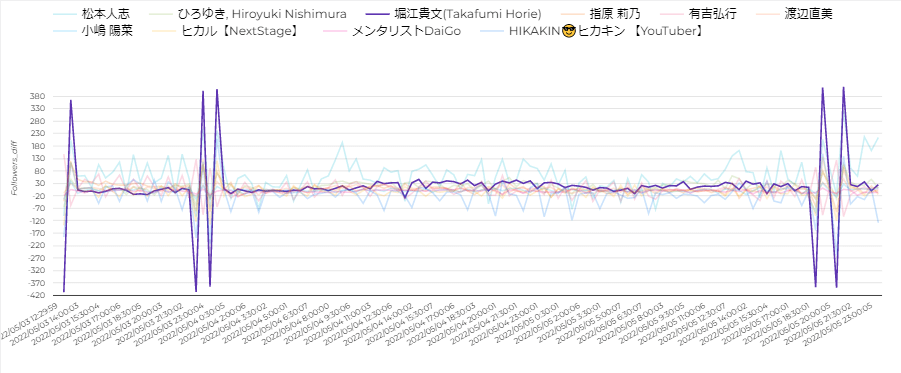
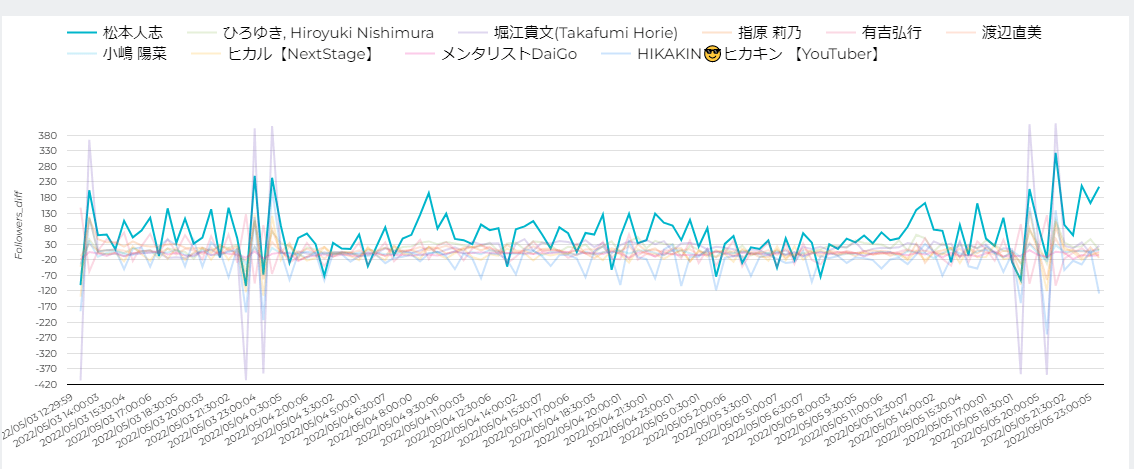
中でも気になったのはホリエモンの紫の線で、短時間でフォロワー数が400くらいの数で上下している時間帯がありました。
では実際にこの期間で誰がどれくらいフォロワー数が増減したかを表でみてみると、まっちゃんが3日間で7300ものフォロワーが増え、逆にヒカキンがかなり減っているのがわかりました。
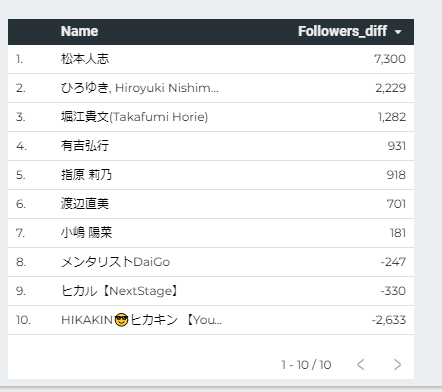
まっちゃんにフォーカスしてみると確かにずっと増え続けています。
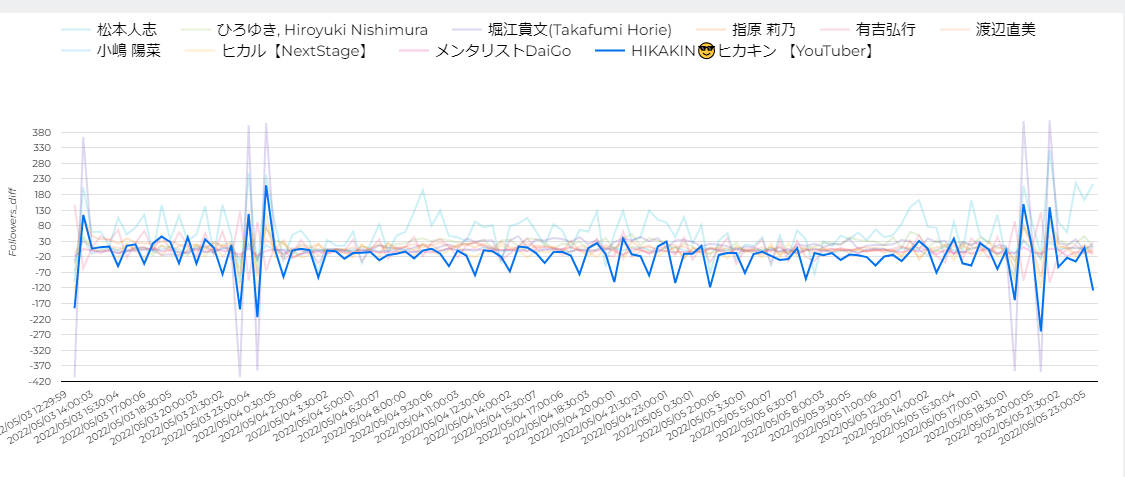
ヒカキンは何度か一気に200くらいフォロワー数を増やしているものの、ほぼ減り続けているような状況でした。
おわりに
いかがでしたでしょうか。今回は気になるインフルエンサーたちのフォロワー数が3日間でどれくらい増えているのかを可視化してみました。構成として同期先DBにBigQuery、BIツールにデータポータルを使いましたが、どちらも別なものに置き換えても同様の可視化ができるかと思います。
なおCData Sync は機能制限なしで 30 日間の無償トライアルが利用可能です。ぜひCDataSync × お使いのDB & BIツールでお試しください!