ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →





CData Arc を使って、AI inside 提供のAI 統合基盤「AnyData」のデータ予測実行を自動化する

こんにちは。CData Software Japan の色川です。
ここ数年、AI の民主化という言葉を耳にする機会が増えてきています。近年、AI の活用がますます拡がり、ビジネスや科学、医療などのさまざまな分野で革新的なソリューションが生まれていますよね。
特に、予測や判断を行うAI の活用は、効率的な意思決定に役立ち、企業や組織にとって非常に有益な価値をもたらし得ることが期待されています。
この記事では、AI inside 株式会社が提供するAI 統合基盤「AnyData」で作成・運用されているAI モデルでの「データ予測実行」を、CData Arc で自動化する方法をご紹介します。
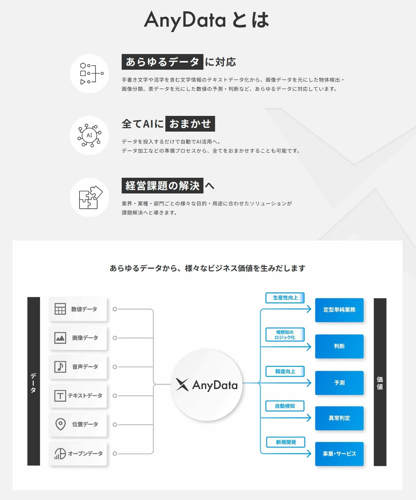
AnyData
AI inside 株式会社が提供する「AnyData」は、AI 開発・実装に求められるデータ基盤・学習基盤・運用基盤を包含した、マルチモーダルなAI 統合基盤です。
これまでデータサイエンティストと呼ばれる専門家たちがプログラミングや高度な統計学的知識を駆使して行っていたAI 構築ステップ(AI のモデル構築と予測)を自動化・効率化・簡易化し、ビジネス部門の実務者でも簡単にAI モデルを構築することができるUI を提供しています。専門知識がなくても、高精度のAI モデルを、短時間で構築することが可能なサービスです。
これまでデータサイエンティストと呼ばれる専門家たちがプログラミングや高度な統計学的知識を駆使して行っていたAI 構築ステップ(AI のモデル構築と予測)を自動化・効率化・簡易化し、ビジネス部門の実務者でも簡単にAI モデルを構築することができるUI を提供しています。専門知識がなくても、高精度のAI モデルを、短時間で構築することが可能なサービスです。
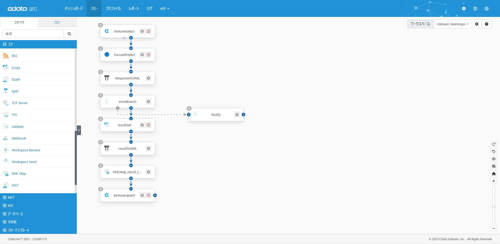
CData Arc

この記事のシナリオ
「旧LearningCenter Forecast(AnyData)」は、AI 統合基盤であるAnyData で提供されているノーコードでAI のモデル作成・運用を可能にするクラウドアプリケーションです。
この記事では「旧LearningCenter Forecast(AnyData)で構築したAI モデルに対して、クラウドサービスから予測データを収集し、AI での予測を実行して、予測結果をクラウドサービスに連携する」シナリオを作成します。この記事では、データソースにkintone を利用しました。

このシナリオで作成するフローで「予測データの準備」と「予測の実行」「予測結果の活用(連携)」といった「AnyData」で作成・運用されているAI モデルに対する「予測・判断の流れを自動化」することができます。
事前準備
事前準備として、必要な製品のインストールや、連携元・連携先の構成を確認していきましょう。
CData 製品のダウンロードとインストール
この記事のシナリオでは、こちらの製品を利用します。30 日間のトライアルライセンスが提供されていますので、ぜひお手元で試してみてください。
CData Arc のインストールはこちらを参考にしてください。
AnyData
AnyData ではプリセットされたサンプルプロジェクトなども用意されていますが、この記事ではAnyData の効率化・簡易化されたUI/UX を体験するために、新しくプロジェクトを作成するところから始めてみました。この記事では、プリセットされている新規出店売り上げ予測の学習データを一部抜粋・変更して、下記のような構成で学習データとして用意しました。売上に影響を及ぼしそうな店舗出店予定地の近隣に関する情報(レンタル駐車場やコンビニ店舗の数など)を学習に利用する変数(説明変数)として、出店後の売上を予想する、といったシナリオです。
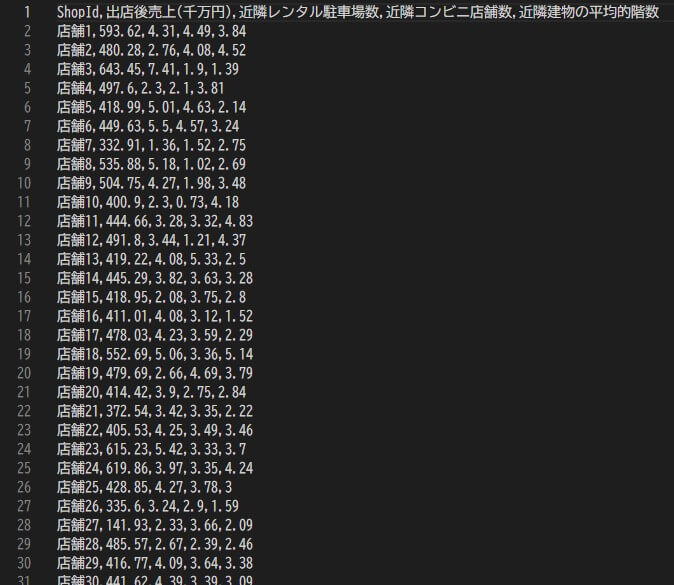
この記事では、予測実行・予測結果の連携といった連携部分にフォーカスしています。 記事上での画像表示や読み易さを優先しており、AI モデル自体は サンプルプロジェクトで用意されているデータの一部を利用して簡易的に作成しています。 この記事で作成するモデルのように、説明変数が少ないと、予測精度の低下や過学習、解釈性の低下なども懸念されますが、 AI 予測実行の前後プロセスであるAPI 連携の部分にフォーカスした記事としてごらんください。
それでは、新しいプロジェクトの作成から、構築したモデルのデプロイまで順に進めていきます。
学習データを選択して、新しいプロジェクトを作成します。
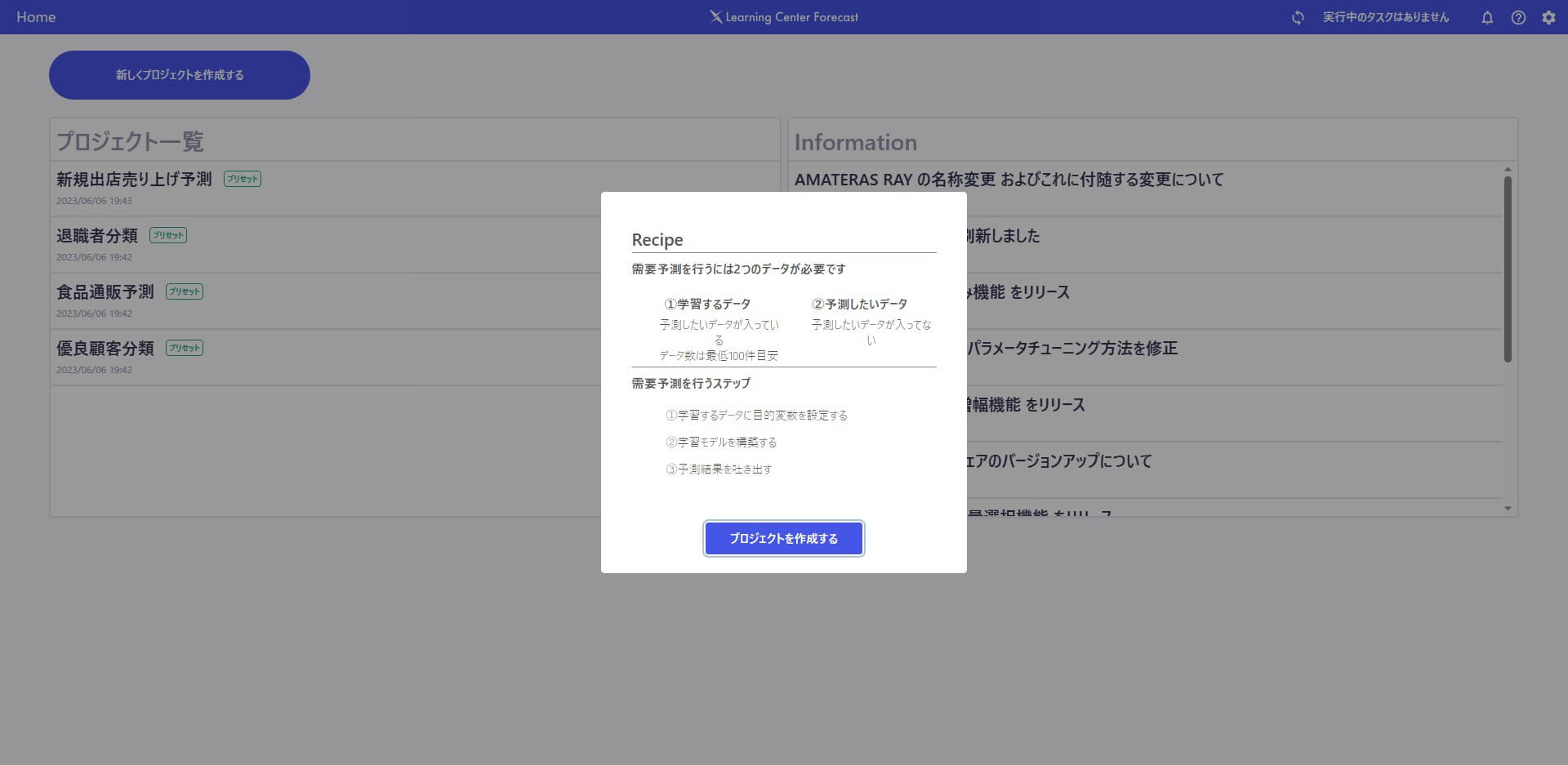
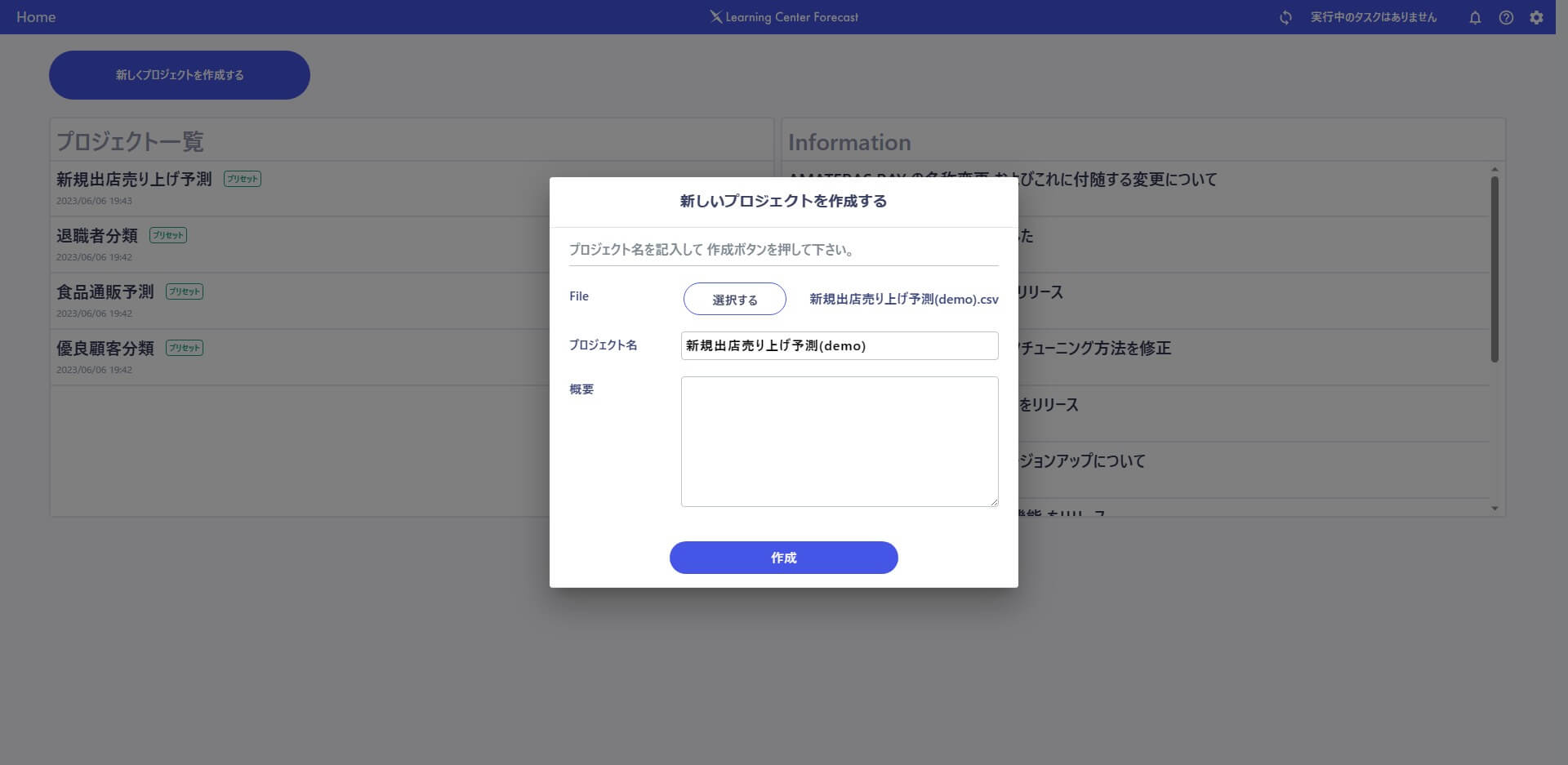
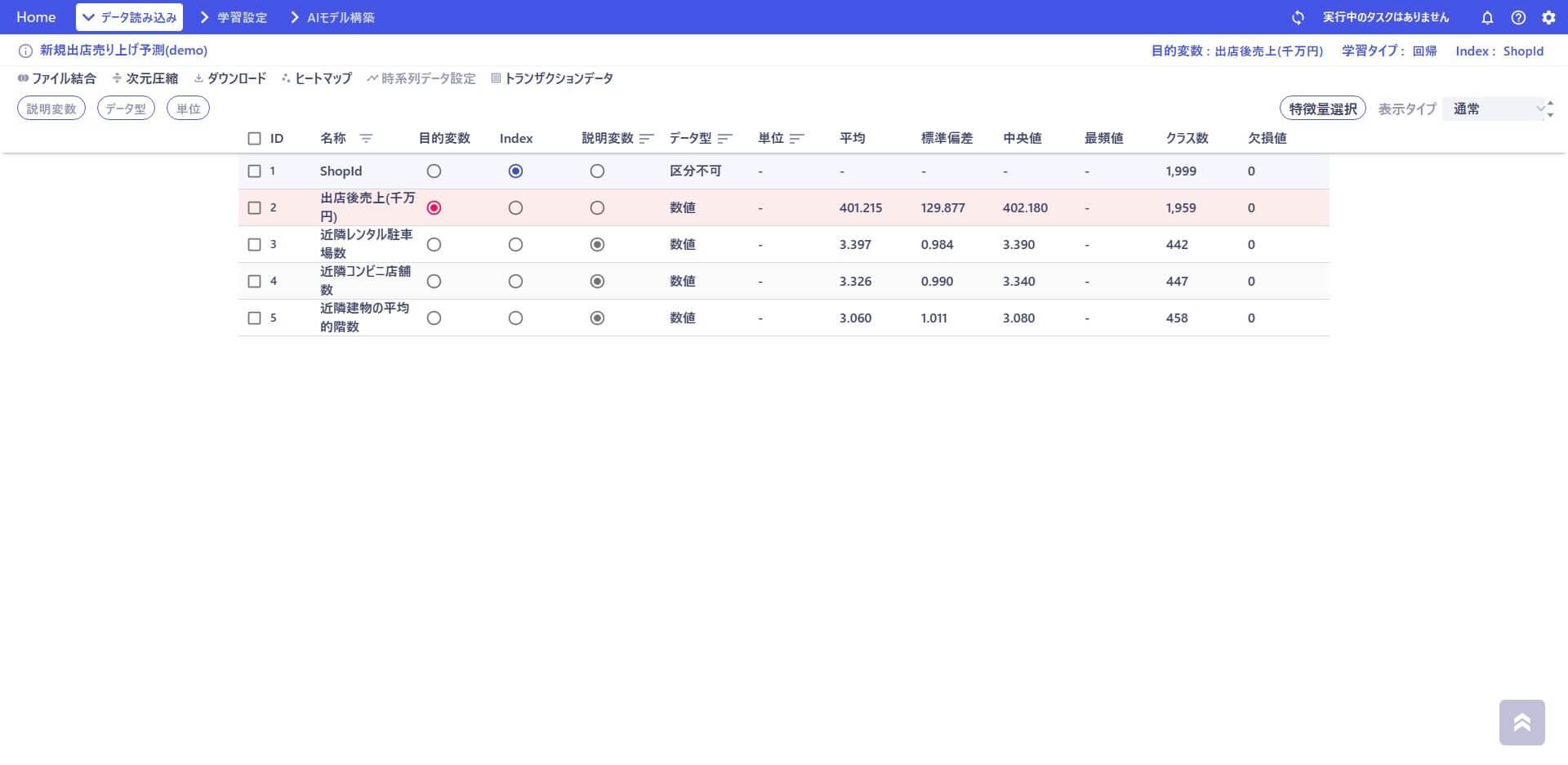
読み込まれたデータ構造に対して、Index や目的変数(AI に予測させたい対象)を指定(選択)します。この記事で作成するモデルでは、ShopId がIndex。出店後売上が目的変数です。
学習選定は「簡単モード」を選択しました。AnyData では簡単・通常・しっかりなどの学習モードが用意されており、より良くデータにフィットさせるため様々なパラメータを調整することもできます。
予測させたい対象と学習に使用する特徴量が決まったので、早速AI モデルの構築(AI による学習)をはじめていきます。AnyData では10 を超えるアルゴリズムを使って、最適なモデルを構築することができます。その操作は驚くほど簡単です。この記事では利用可能なすべてのアルゴリズムを使って学習を開始しました。学習中の進捗状況はナビゲーションバーで確認する事ができます。記事のケースでは「Ridge」アルゴリズムがベストスコアのようです。
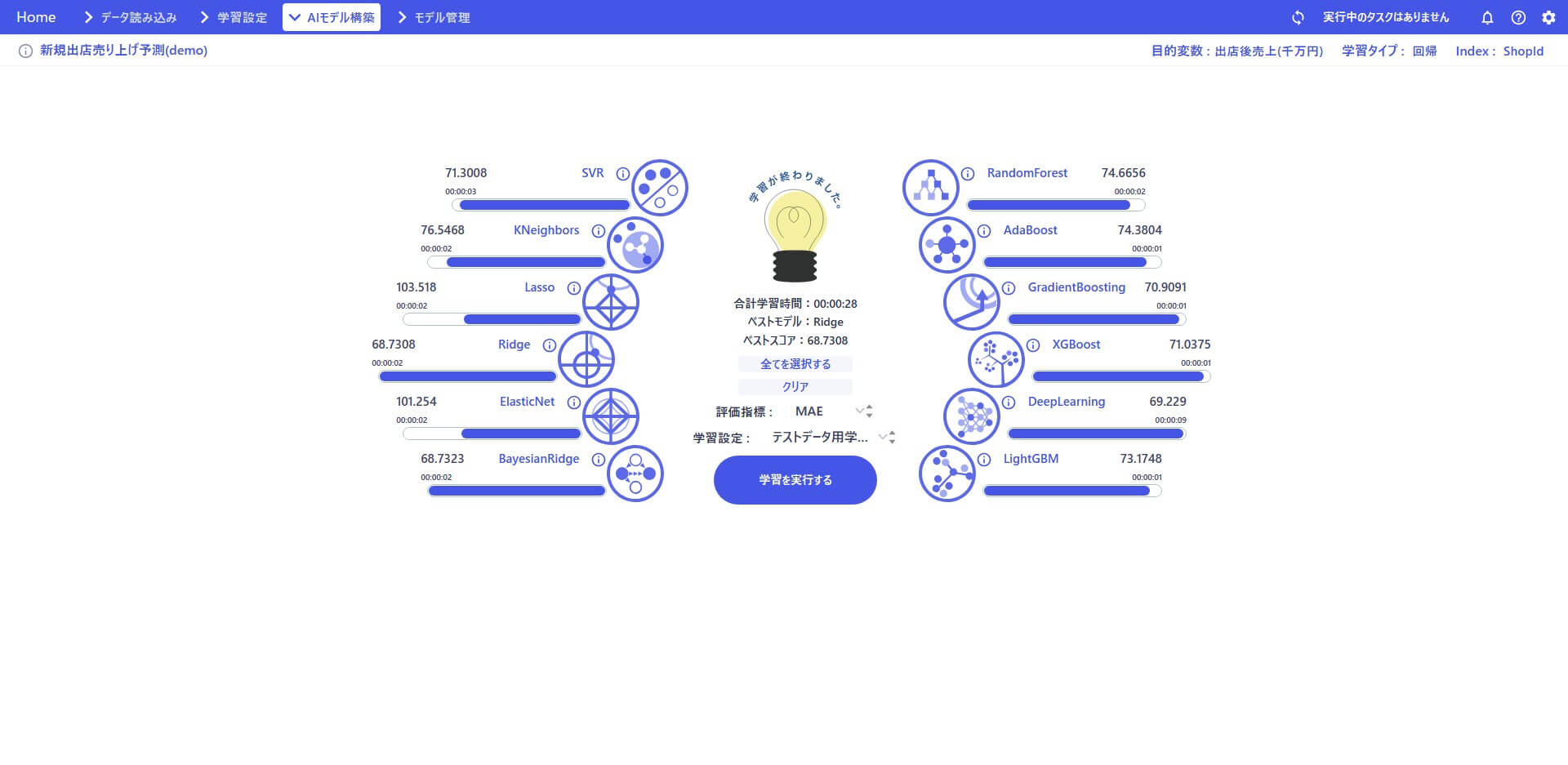
性能計測のための検証を行います。
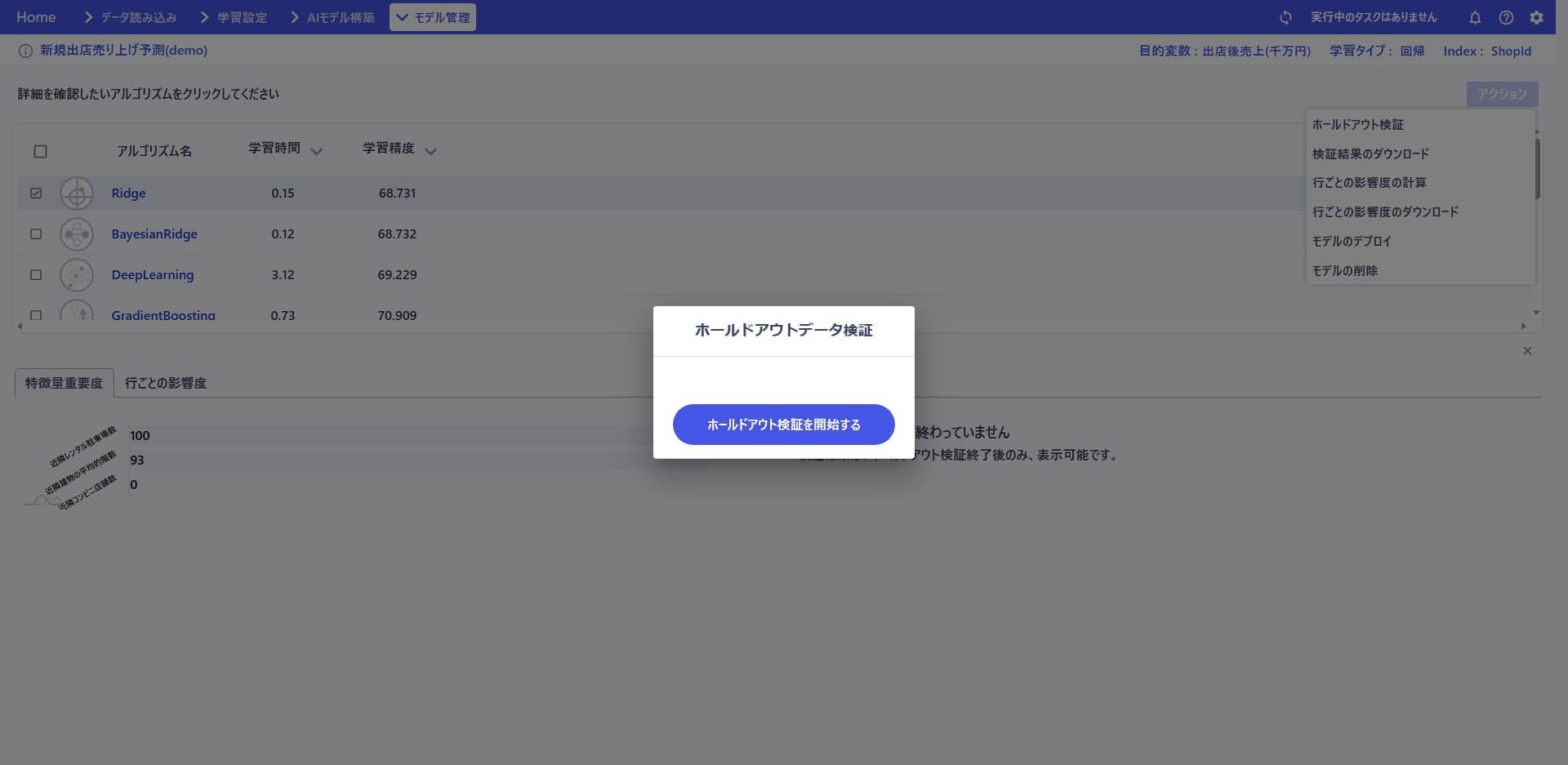
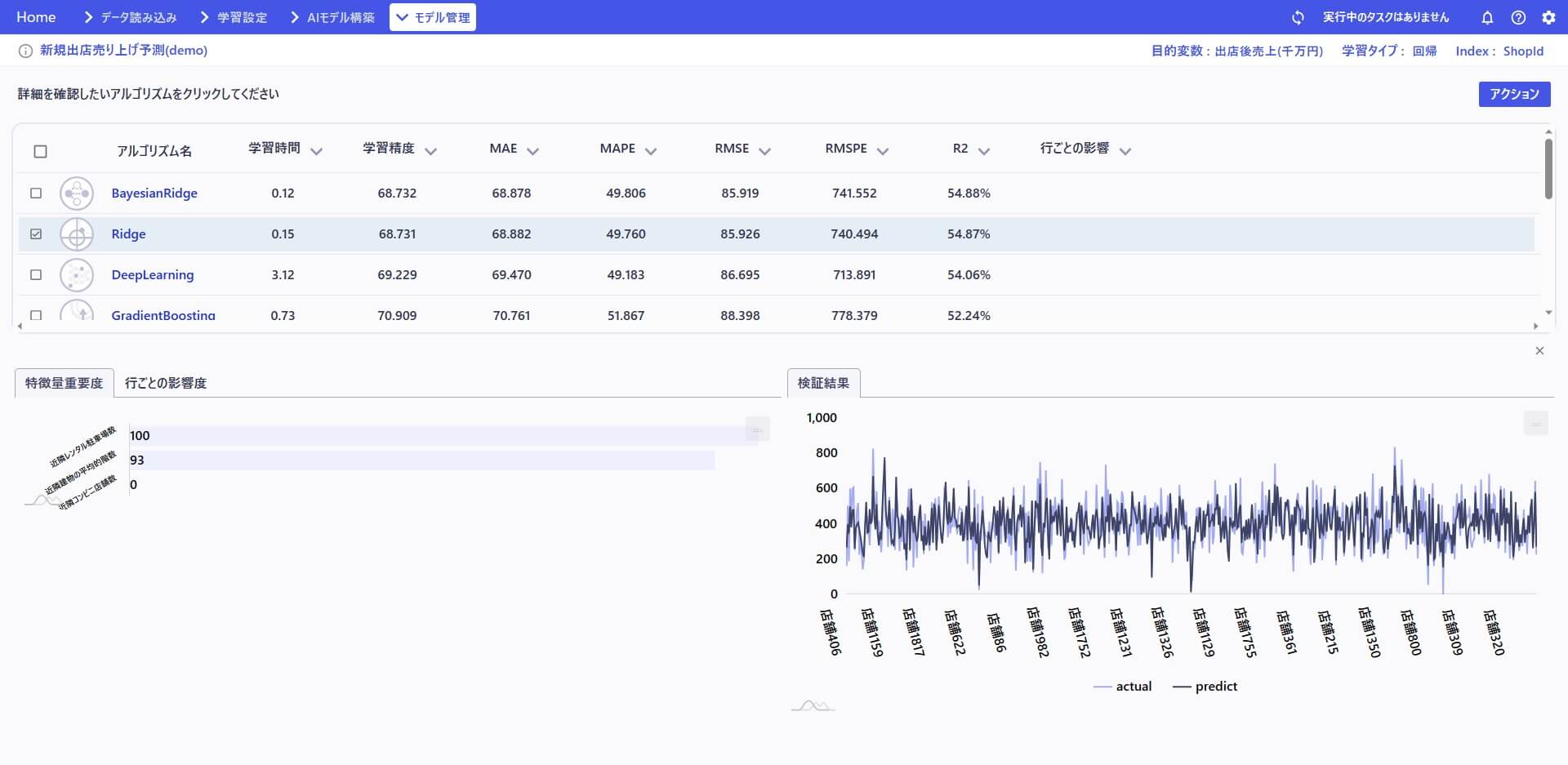
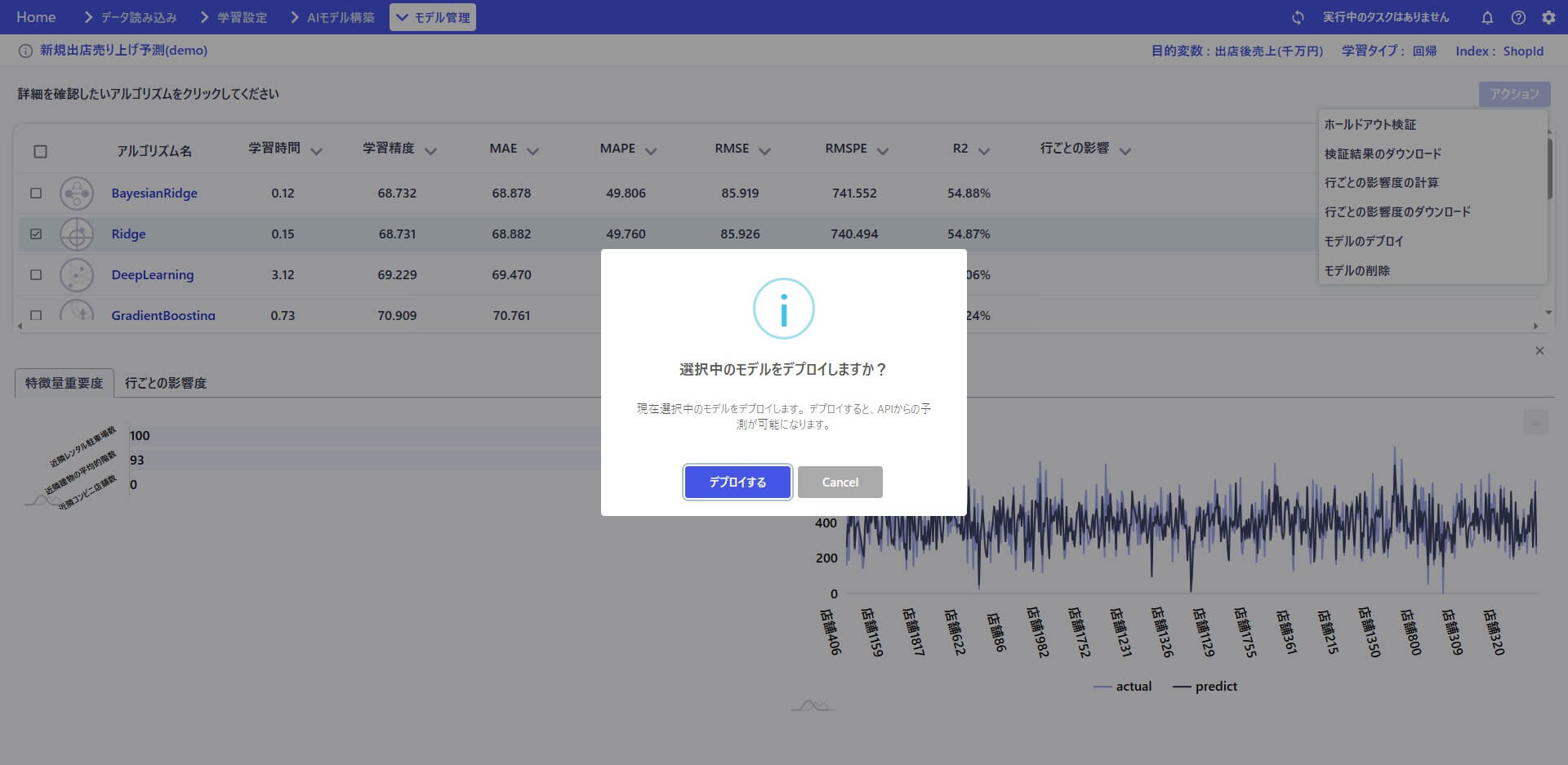
検証したモデルをデプロイします。デプロイしたことで、構築したモデルが外部から利用可能な環境に移り、モデルによる予測が実行可能になりました。
これでデータ予測が実行できるようになりました。
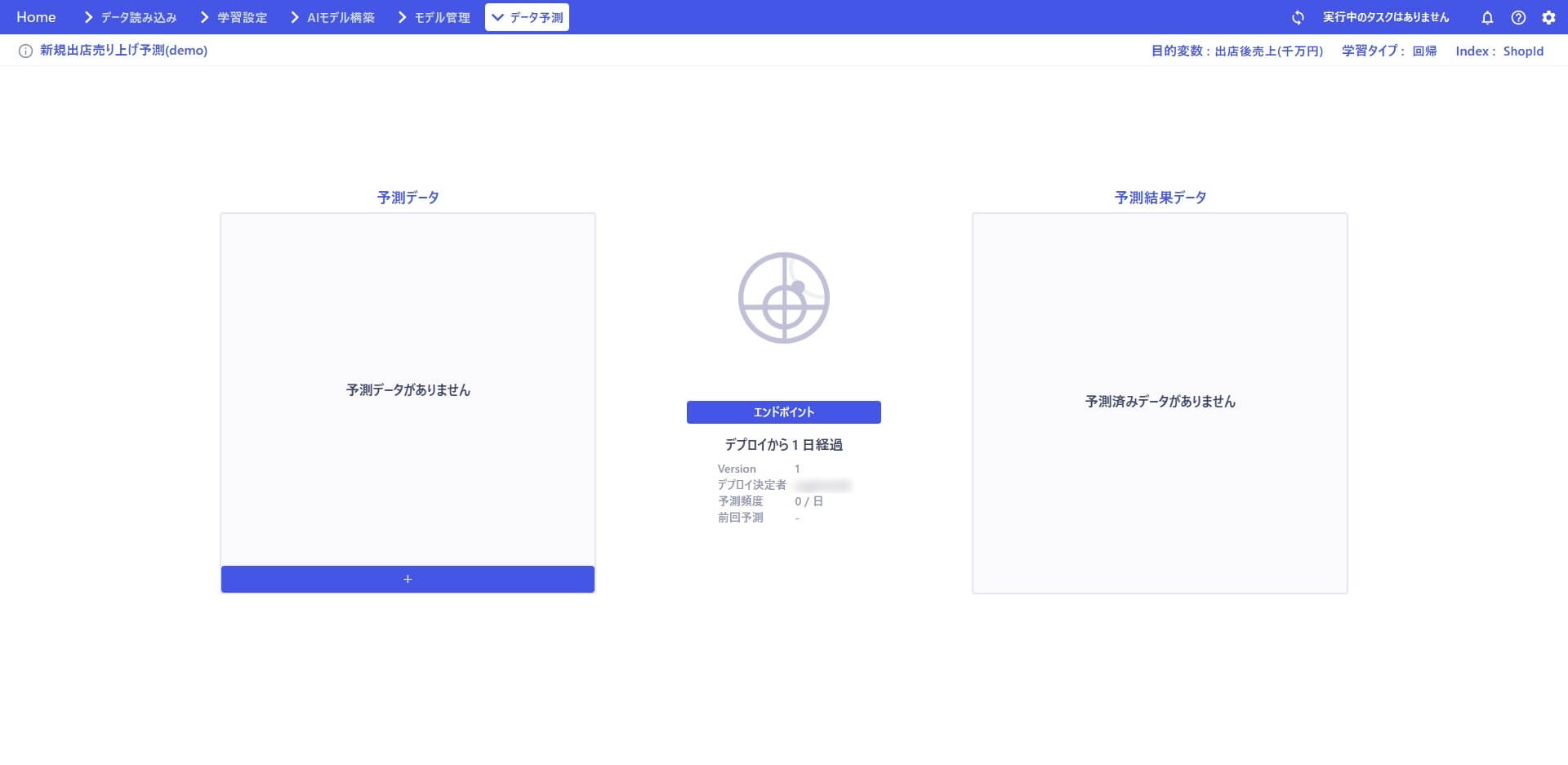
そのままGUI 上で予測したいデータをアップロードすることで予測実行することもできますが、この記事ではAPI での予測実行に必要なエンドポイントの情報を取得します。
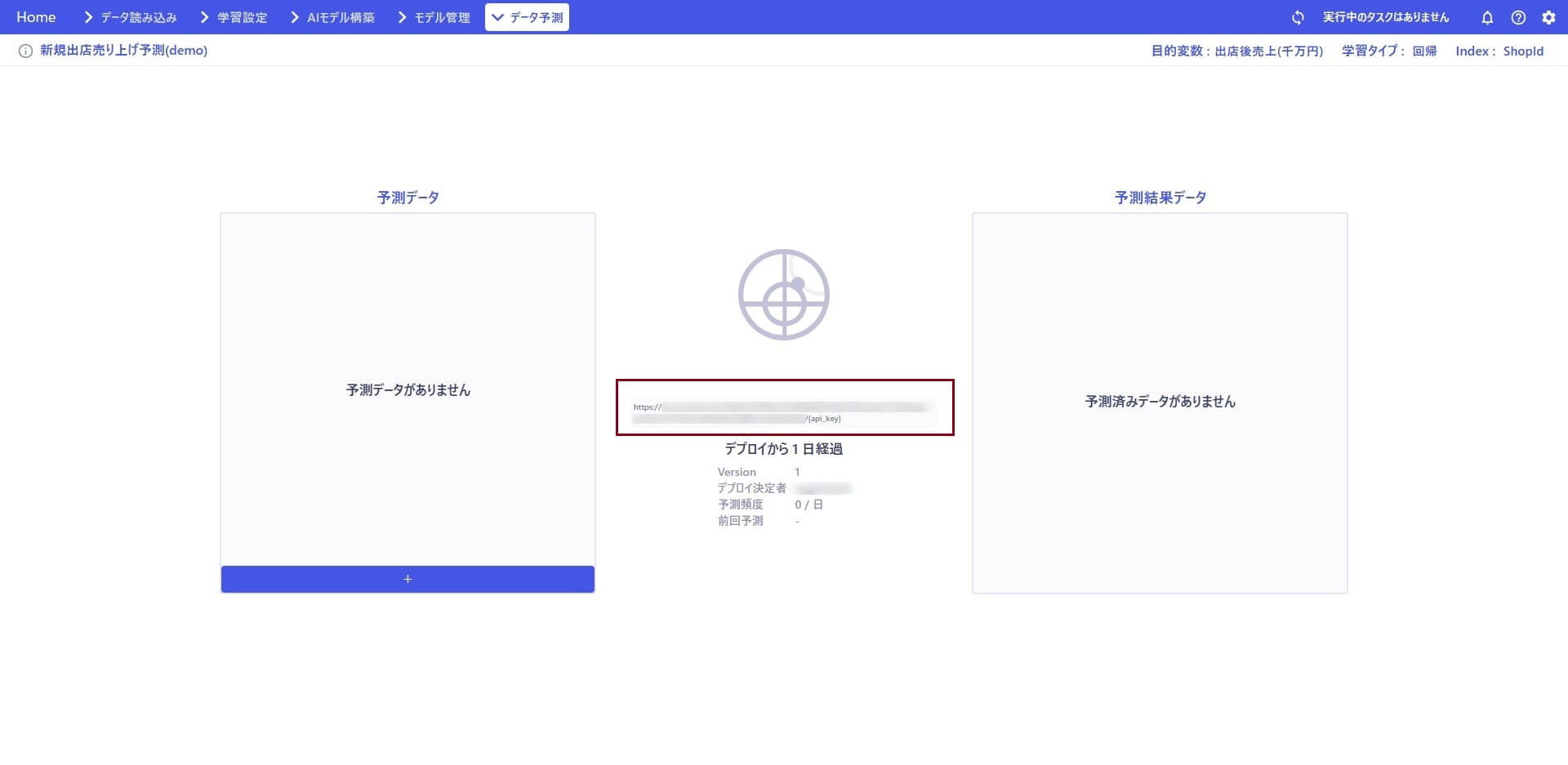
エンドポイントの情報を控えておいてください。これでAnyData 側の準備ができました。
kintone
kintone 側には、以下のようなアプリとデータを用意しました。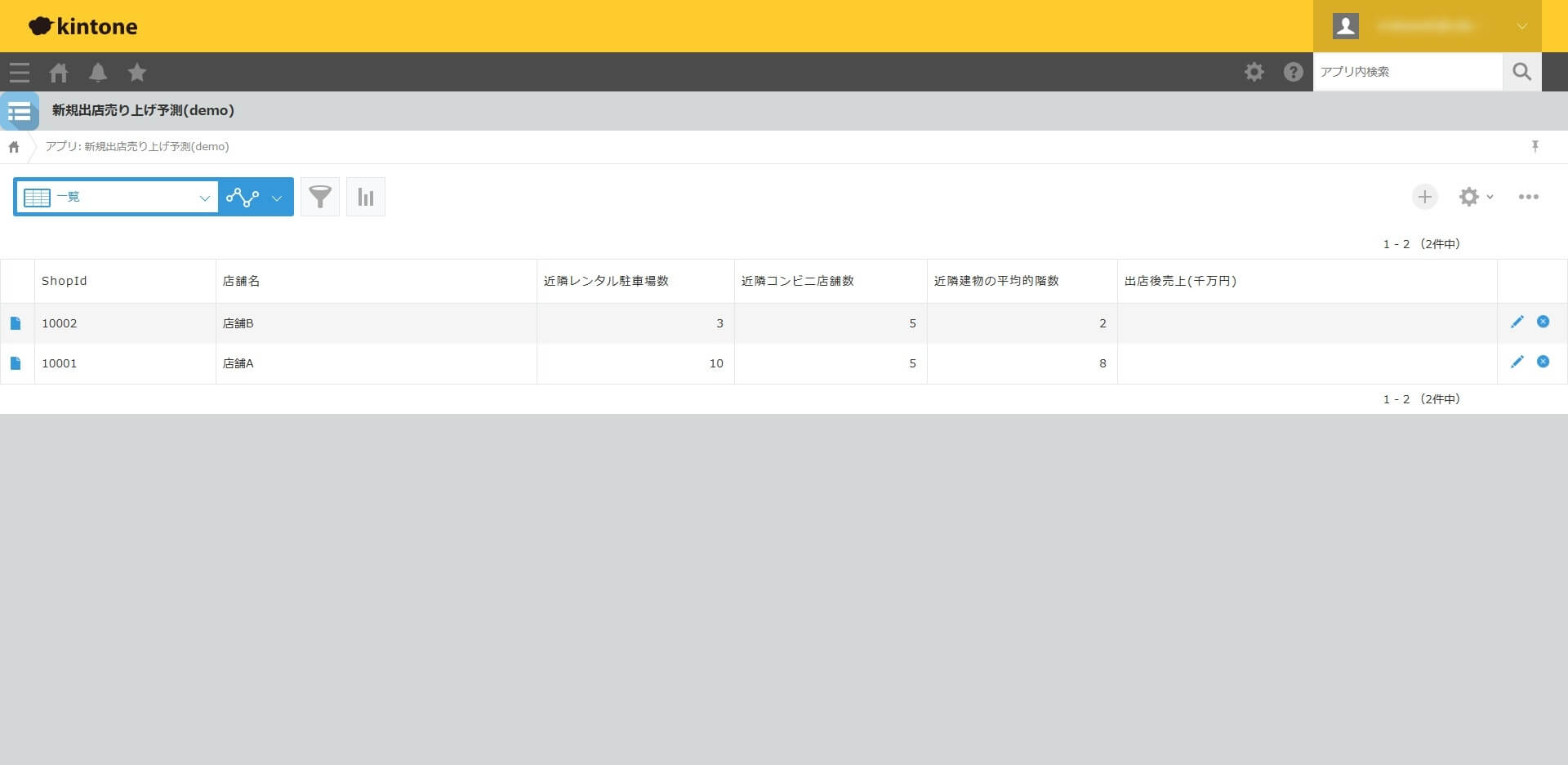
この記事では、ShopId から近隣建物の平均的回数までのデータをAnyData に予測データとして連携して、予測実行した結果である「出店後売上」のデータを、kintone の「出店後売上」カラムに連携します。
CData Arc スタートアップガイドとナレッジベース
CData Arc を使いはじめるときは、こちらも参考にしてください。
CData Arc に関するナレッジは、こちらにまとめています。あわせて参考にしてください。
それでは実際にそれぞれの連携フローを作成していきます。
連携フローの作成
このシナリオで作成する連携フローは以下のような流れになっています。
| コネクタ | 内容 | |
| 1 | CData | kintone からSelect(CSV 出力) |
| 2 | REST | AnyData の予測実行API を実行 |
| 3 | JSON | 予測実行API のレスポンスをXML に変換 |
| 4 | Branch | 予測実行API のレスポンスから成功/失敗を判断 |
| 5 | Script | 予測実行API が成功の場合にレスポンスから予測結果部分のJSON を抽出 |
| 6 | Notify | 予測実行API が失敗の場合にメール通知 |
| 7 | JSON | 抽出した予測結果部分をXML に変換 |
| 8 | XMLMap | 7 のデータを9 にマッピング |
| 9 | CData | kintone へUpsert |
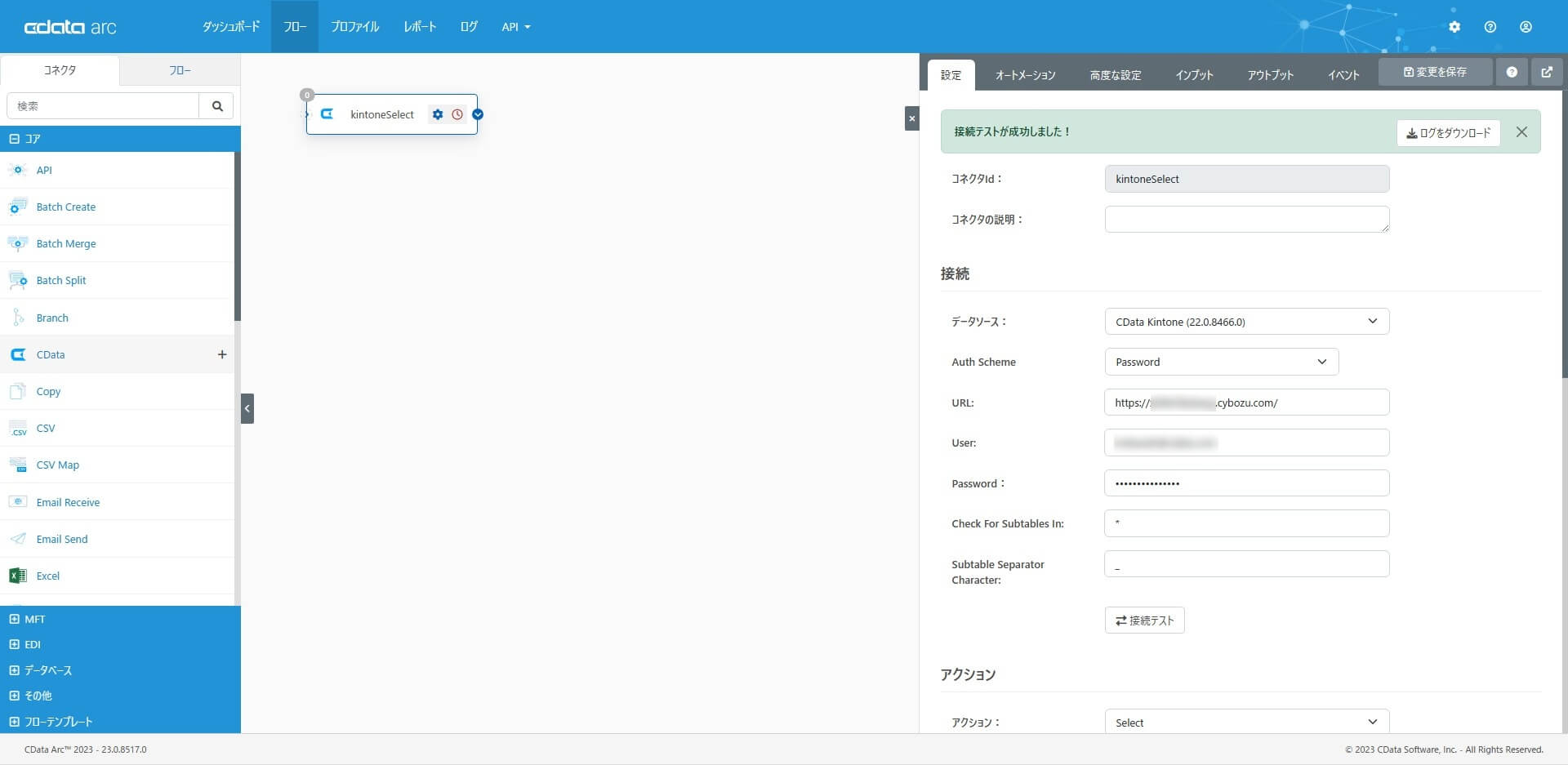
1. CData コネクタ
CData コネクタを配置し「kintone からSelect(CSV 出力)」するための設定をします。コアカテゴリから「CData コネクタ」を選択・配置して、kintone への接続を構成します。
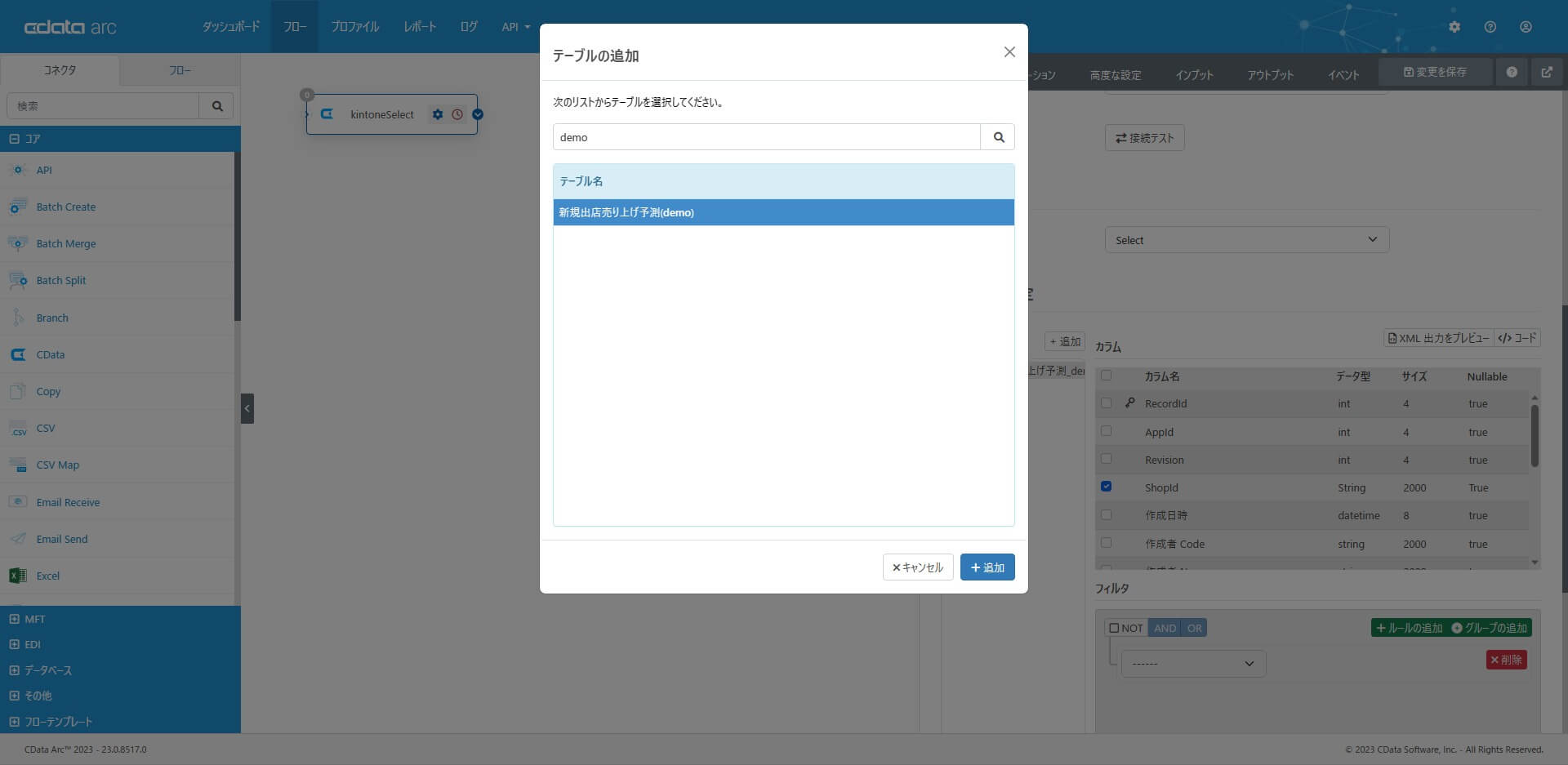
アクションとして「Select」を選択して、テーブルの追加で対象テーブル(アプリ)を選択します。
カラム設定で、取得対象のカラム(列)を選択します。
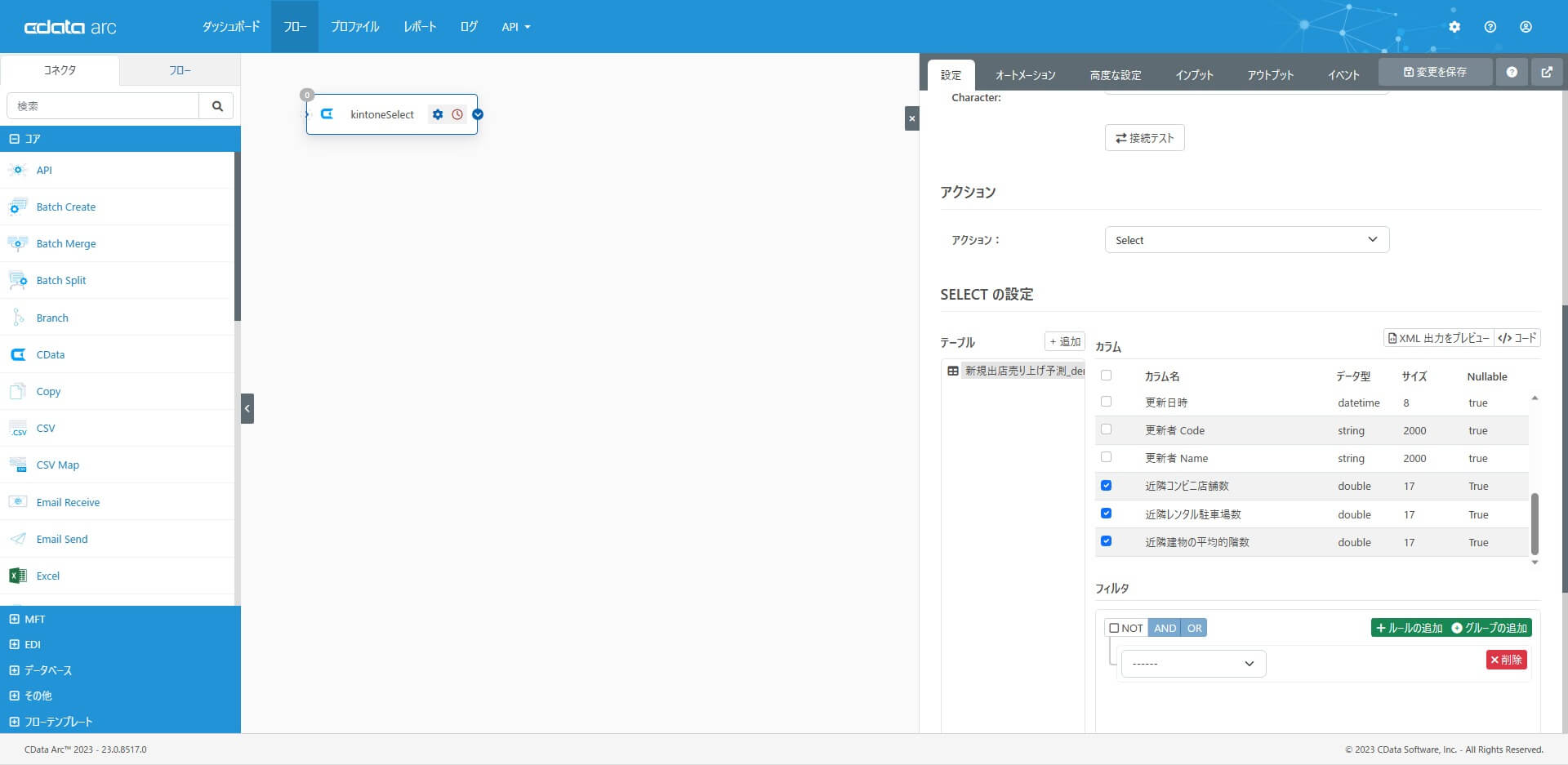
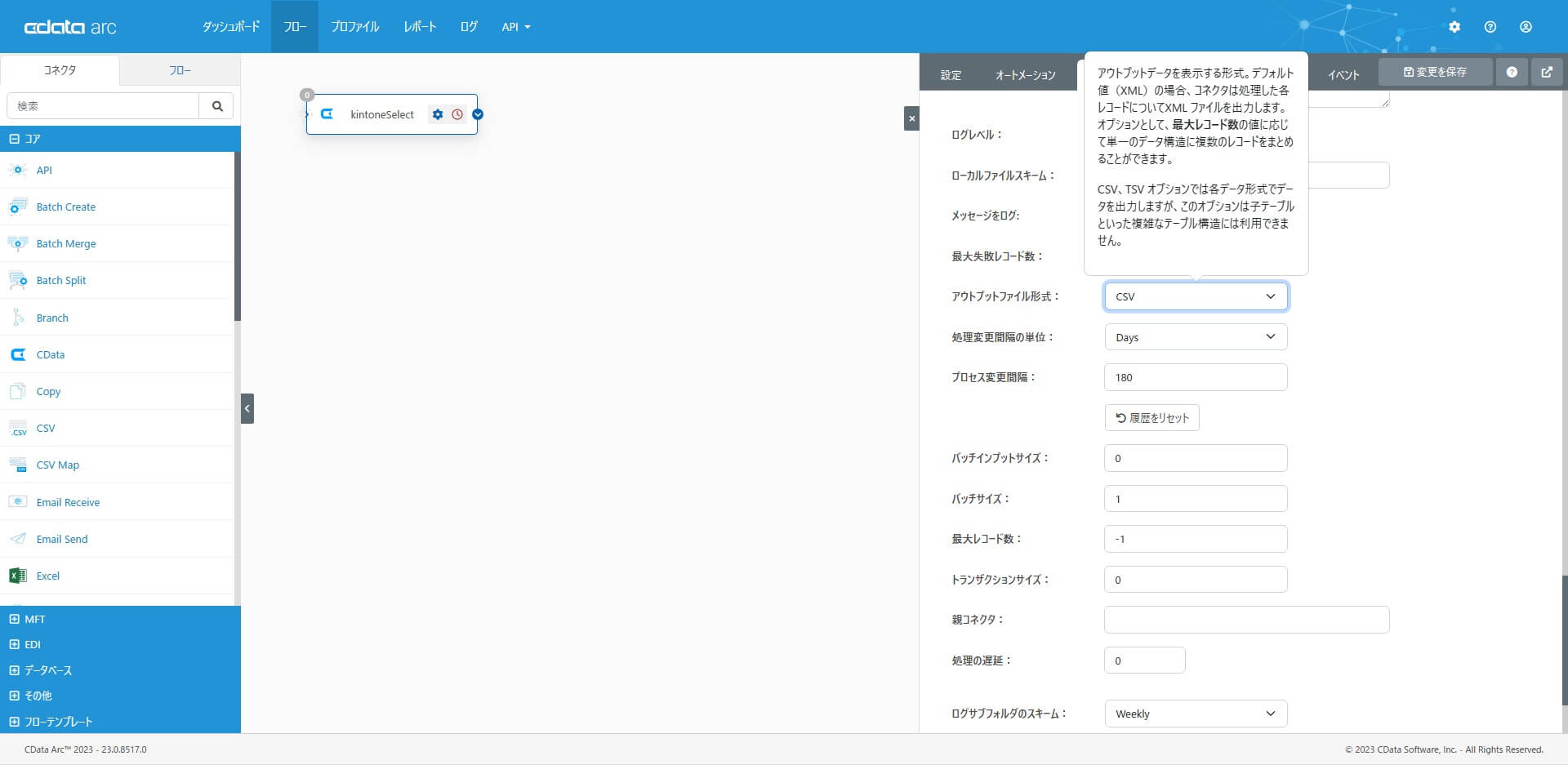
この記事では、取得データを編集・加工せず、そのまま予測データとして利用するため、アウトプットファイル形式に「CSV」を選択して、簡略化しました。
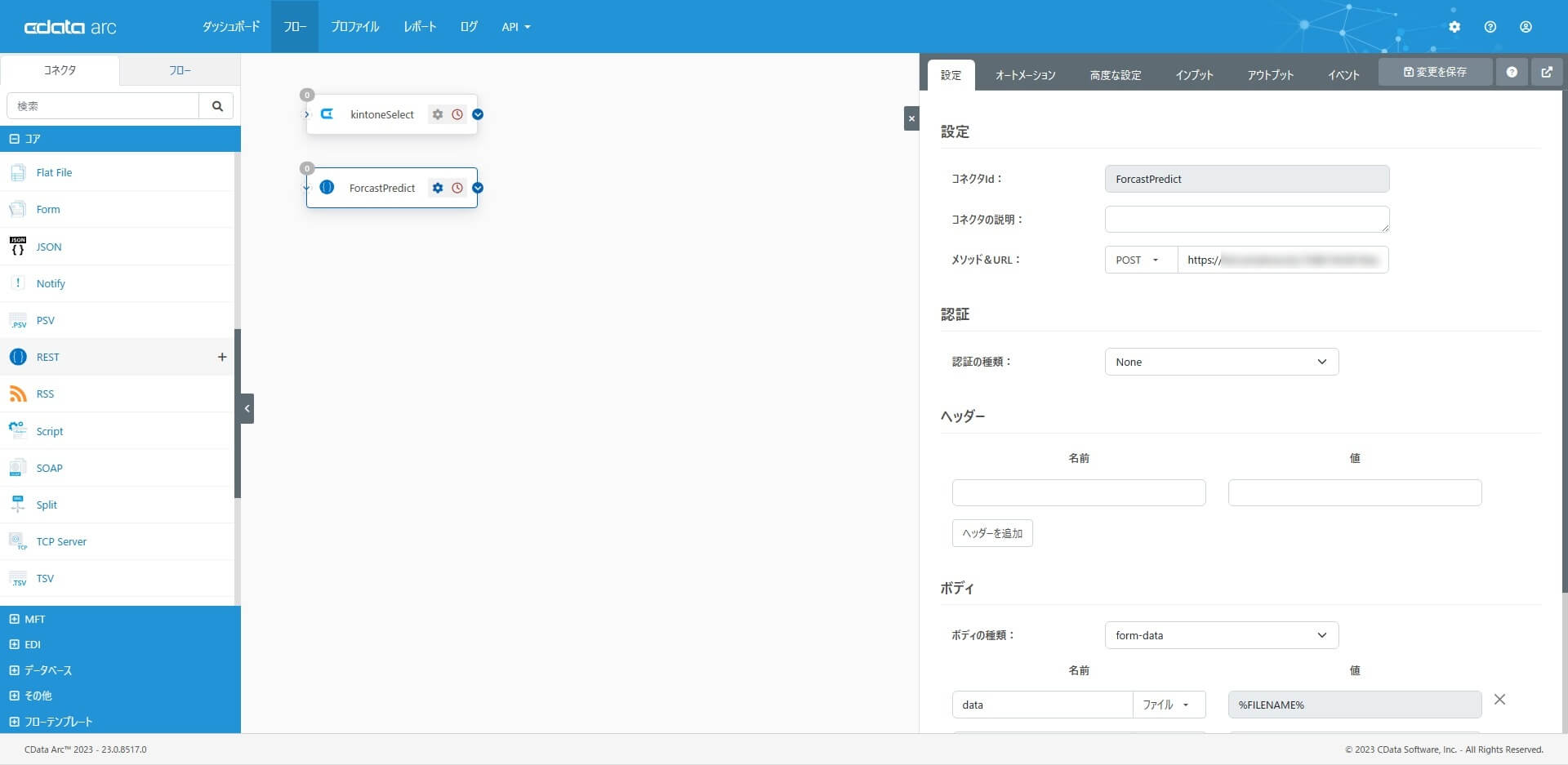
2. REST コネクタ
REST コネクタを配置し「AnyData の予測実行API を実行」するための設定をします。コアカテゴリから「REST コネクタ」を選択・配置して、メソッドを「POST」、URL は「マイページで確認できるAPI キー」と「データ予測ページで控えたエンドポイント」で構成します。
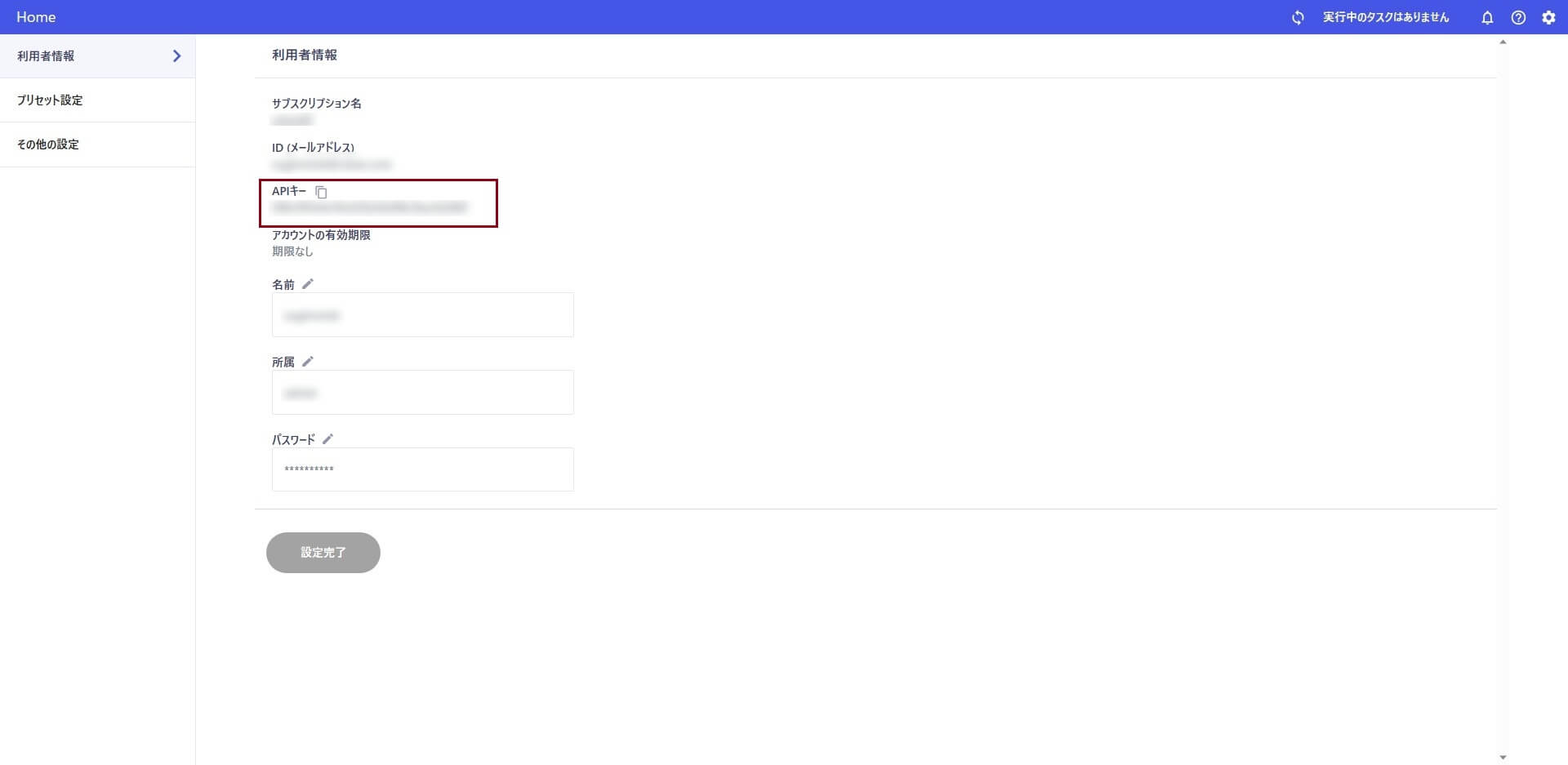
{データ予測ページで控えたエンドポイント}/{マイページで確認できるAPI キー}
なお、この記事ではv2.0 のAPI を利用しました。
API に関する詳細はAnyData のマニュアルなどを確認してください。
data として1. で取得したCSV ファイルを。ShopId は予測結果を反映する際のkey 情報にも利用するので、予測結果にShopId を含んで出力されるように、on_index も併せて指定しています。
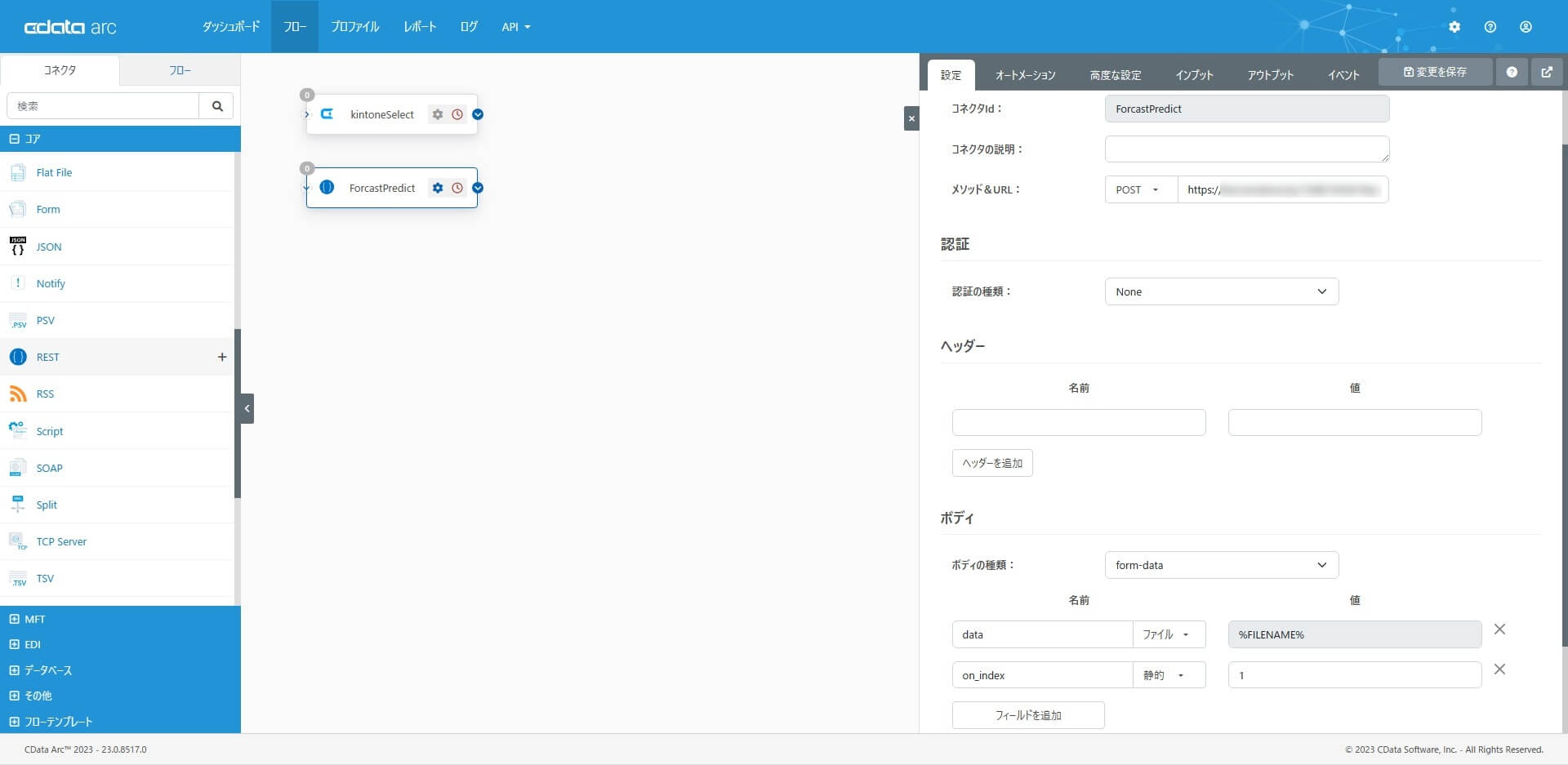
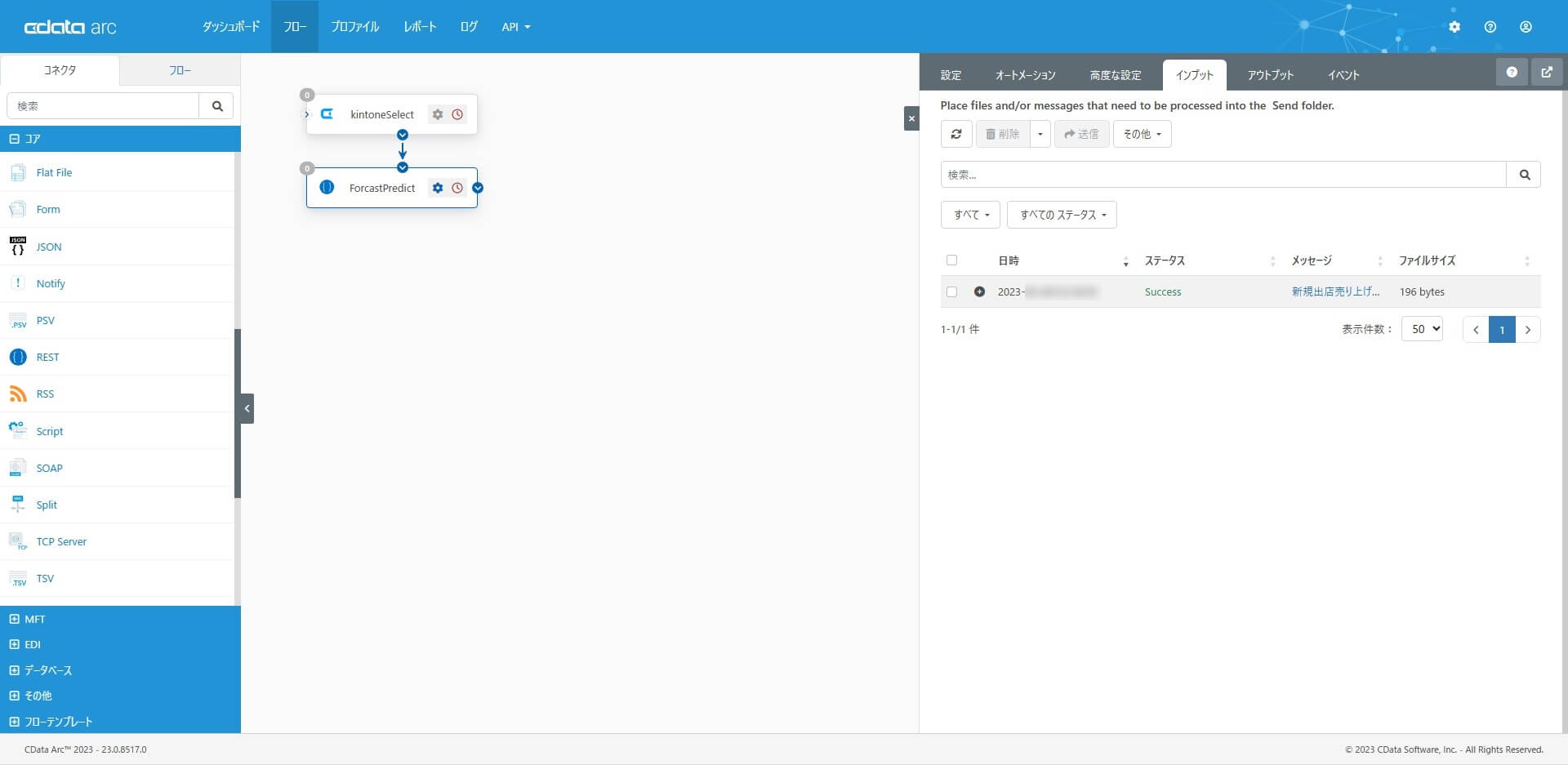
この記事では、このコネクタが一番の確認ポイントです。1 と2 のコネクタをつなげて、起点である1 のCData コネクタで受信を実行し、確認してみます。
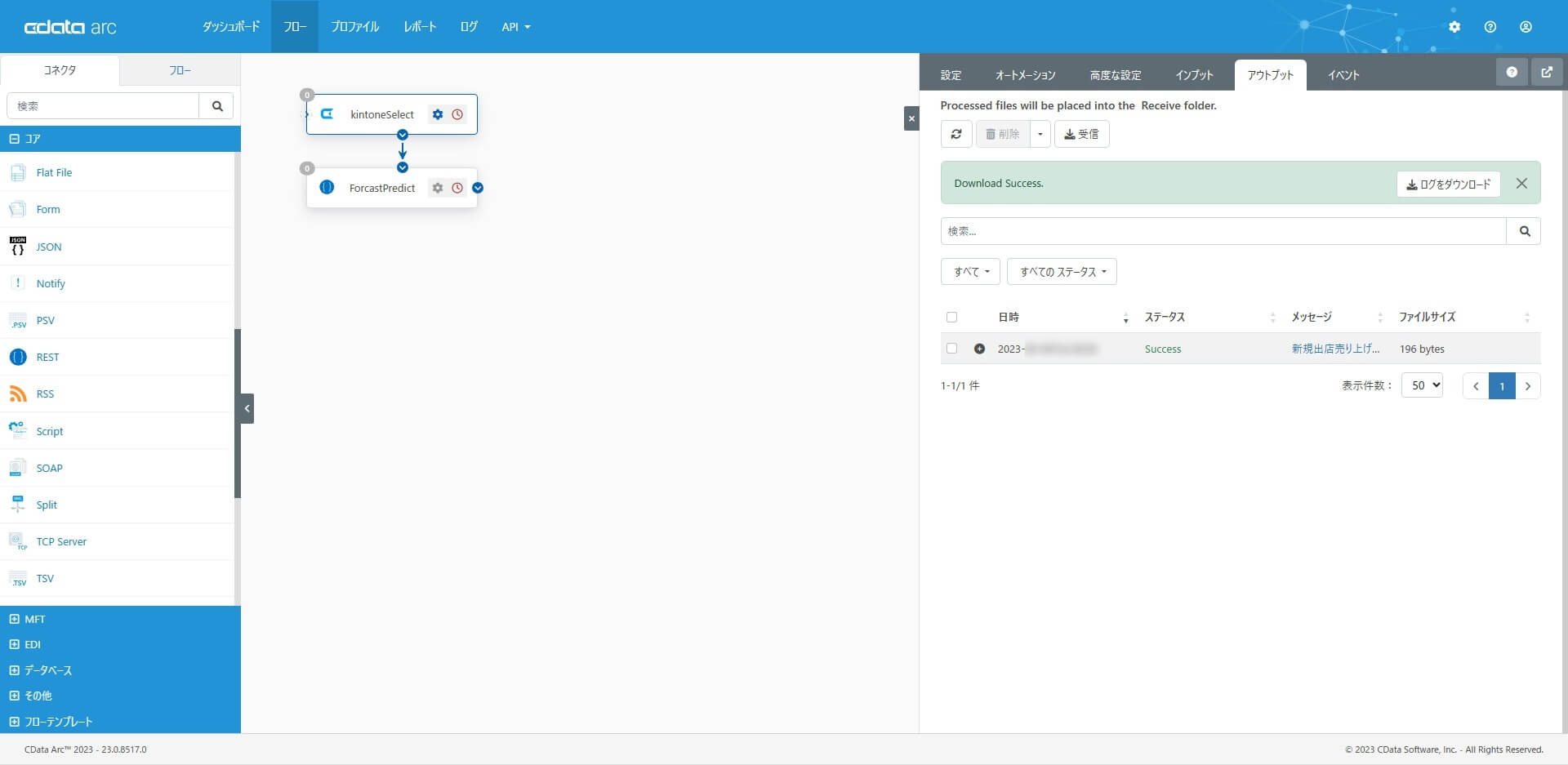
REST コネクタでAnyData の予測実行API が正常に実行できていることが確認できます。
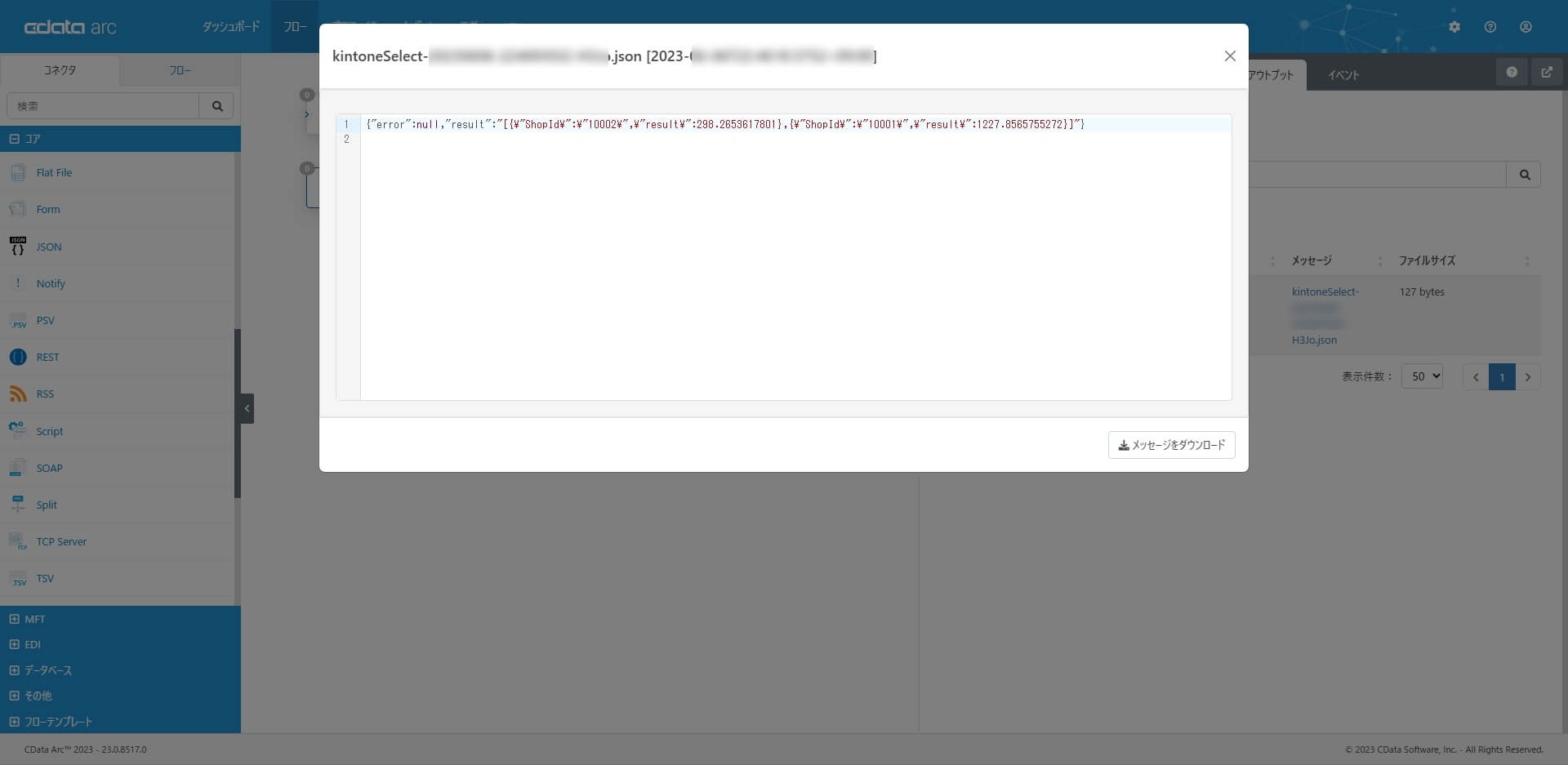
REST コネクタのアウトプットタブから、予測実行API のレスポンス(予測結果)を確認することができます。期待通りに予測結果を得られていることが確認出来ました。
3. JSON コネクタ
JSON コネクタを配置し「予測実行API のレスポンスをXML に変換」するための設定をします。コアカテゴリから「JSON コネクタ」を選択・配置します。設定はデフォルトで大丈夫です。設定したらフローをつないでおきます。
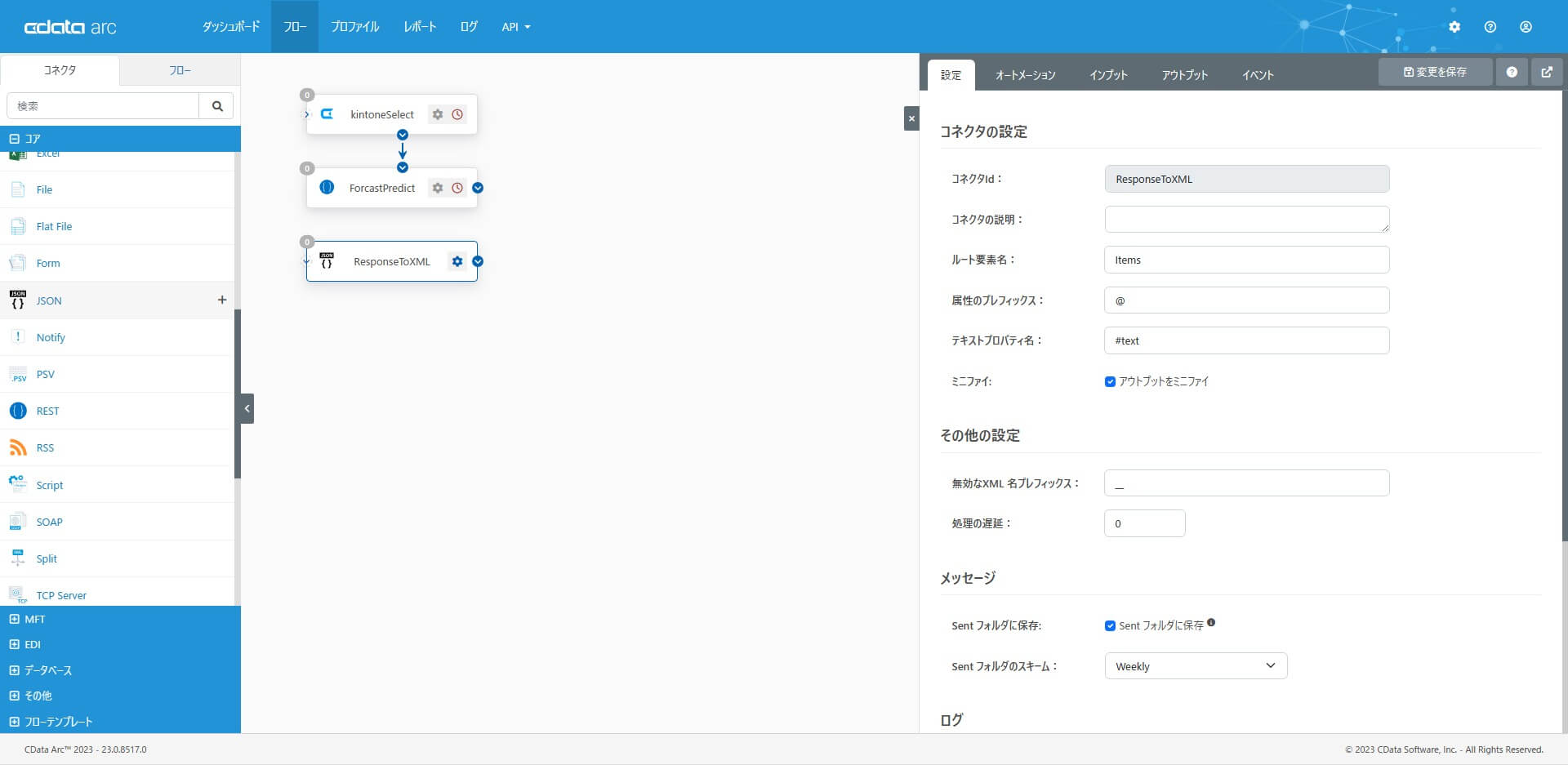
4. Branch コネクタ
Branch コネクタを配置し「予測実行API のレスポンスから成功/失敗を判断」して分岐するための設定をします。コアカテゴリから「Branch コネクタ」を選択・配置します。3. でXML 変換したAPI レスポンスに含まれるerror 属性をXPath に指定し、error 要素がNull か否かで成功を判断します。設定したらフローをつないでおきます。
この記事の時点で、v2.0の予測実行API は下記のようなレスポンスを返し、予測処理中にエラーが発生した場合は、error が非Null に設定されます。
{
result:{[
{column1:1,column2:’test’},
{column1:2,column2:’test_2’},
…
]},
error:null
}
5. Script コネクタ
予測実行API の実行が成功だった場合の流れです。Script コネクタを配置し「レスポンスから予測結果部分のJSON を抽出」するための設定をします。コアカテゴリから「Script コネクタ」を選択・配置します。3 でXML に変換した中でもresult 要素はJSON 文字列として保持されていますので、xmlDOMGet オペレーションを利用して、(JSON 文字列である)result 要素を抽出し、メッセージファイルとして出力(push)します。設定したら青いフローをつないでおきます。
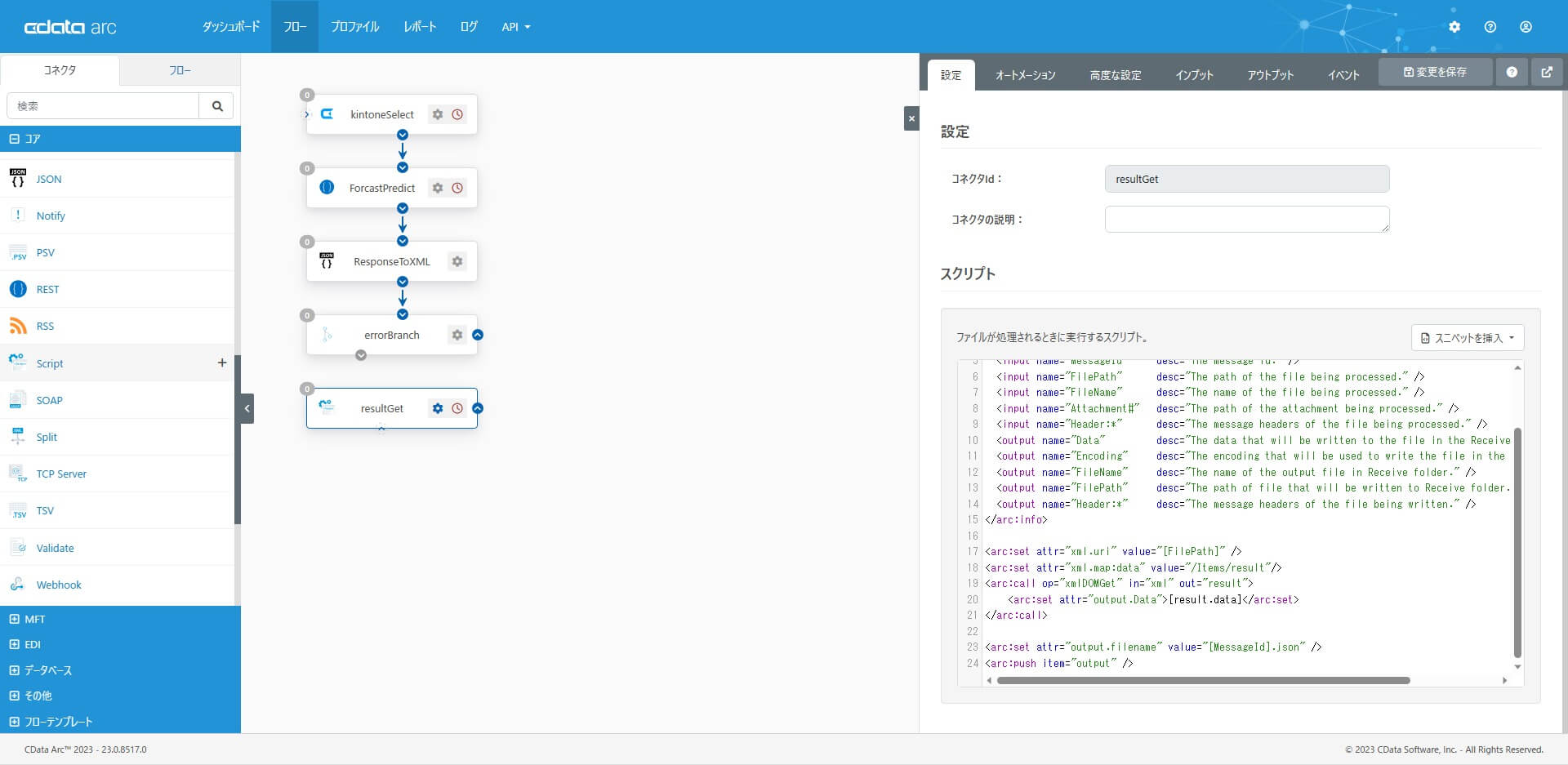
<arc:set attr="xml.uri" value="[FilePath]" /> <arc:set attr="xml.map:data" value="/Items/result"/> <arc:call op="xmlDOMGet" in="xml" out="result"> <arc:set attr="output.Data">[result.data]</arc:set> </arc:call> <arc:set attr="output.filename" value="[MessageId].json" /> <arc:push item="output" />
6. Notify コネクタ
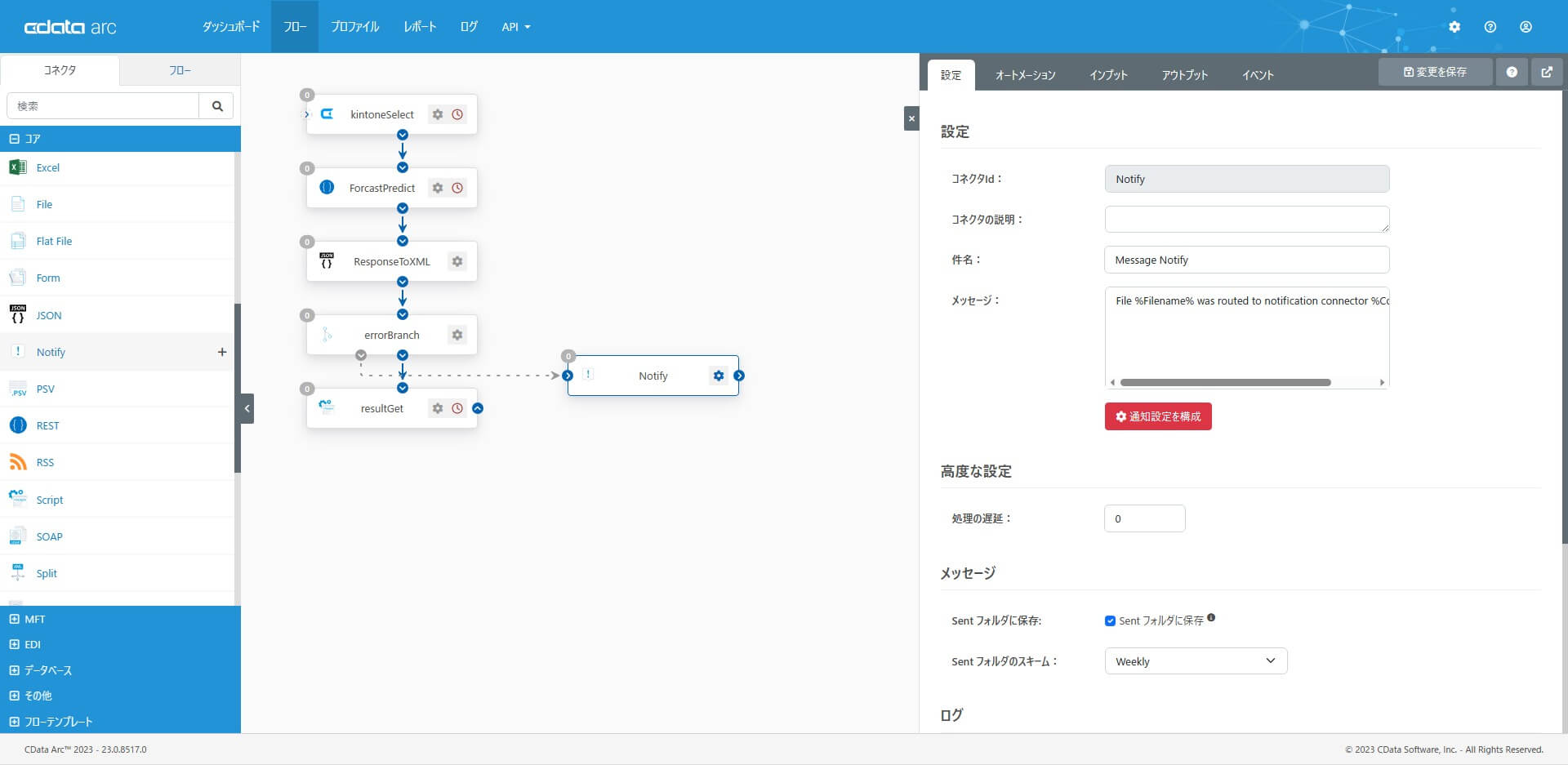
予測実行API の実行が失敗だった場合の流れです。Notify コネクタを配置し「メール通知」するための設定をします。コアカテゴリから「Notify コネクタ」を選択・配置します。エラーの通知先設定を構成してください。設定したら灰色のフローをつないでおきます。Branch コネクタで値が一致しなかった場合、灰色のフローパスにルーティングされます。
7. JSON コネクタ
JSON コネクタを配置し「抽出した予測結果部分をXML に変換」するための設定をします。コアカテゴリから「JSON コネクタ」を選択・配置します。設定はデフォルトで大丈夫です。
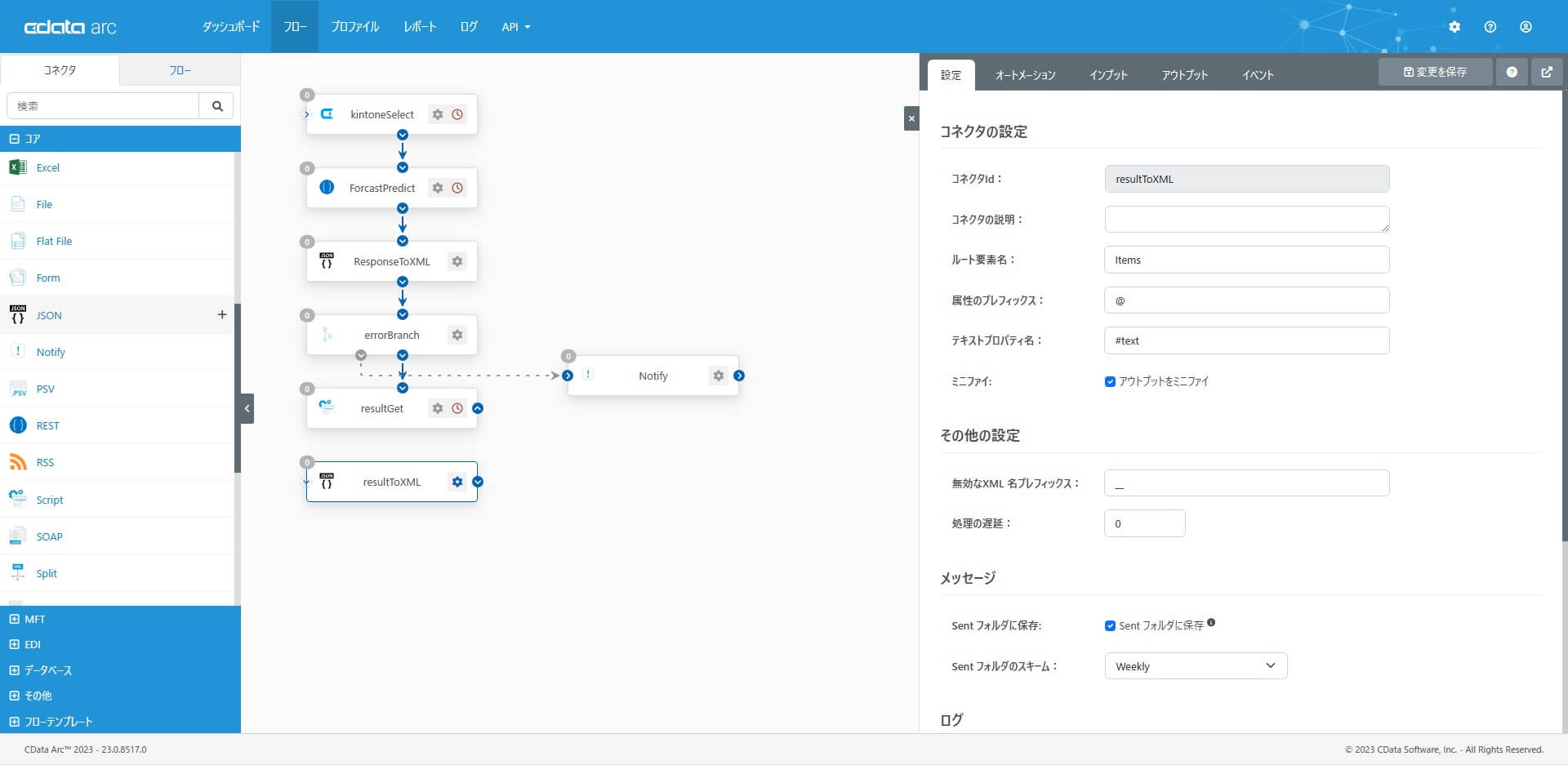
JSON コネクタから出力するXML 構造を後続のXMLMap で簡単に指定できるように、予測結果のデータ構造を表すJSON ファイルを用意して「テストファイルをアップロード」します。設定したらフローをつないでおきます。
[{"ShopId":"","result":0}]
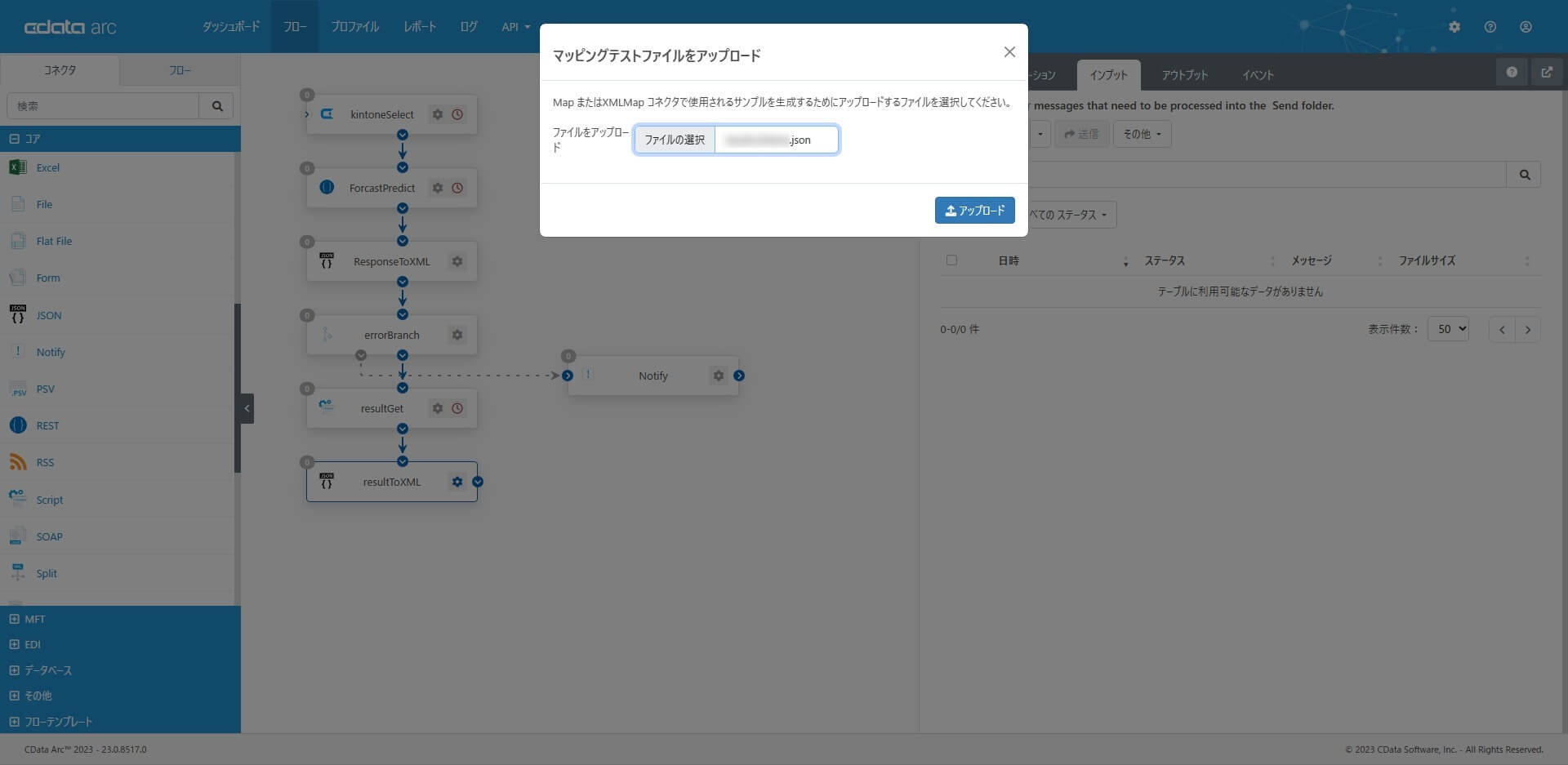
9. CData コネクタ
XMLMap コネクタを構成する前に、CData コネクタを配置し「kintone へUpsert」するための設定をします。コアカテゴリから「CData コネクタ」を選択・配置して、kintone への接続を構成します。
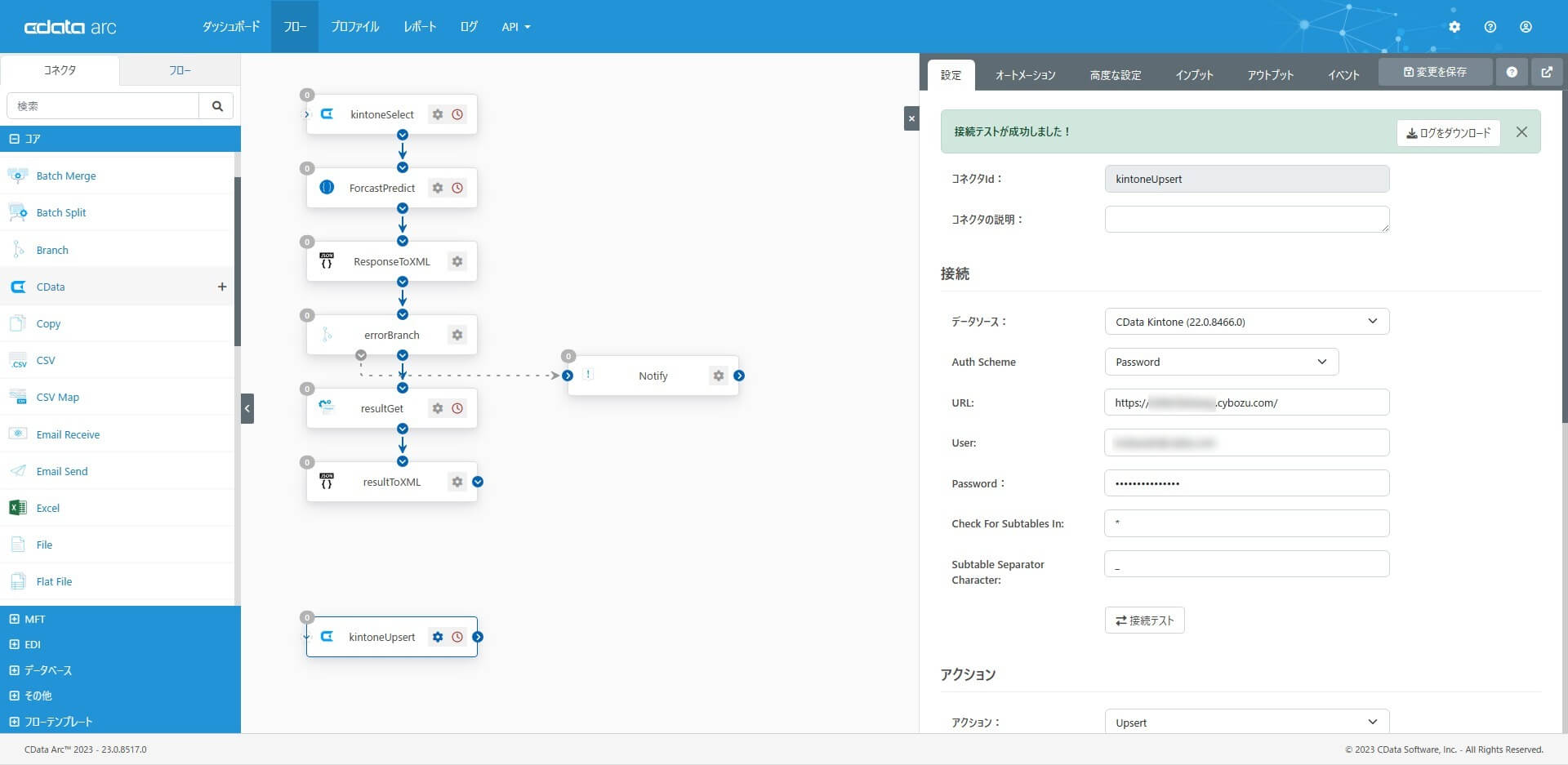
アクションとして「Upsert」を選択して、テーブルの追加で対象テーブル(アプリ)を選択します。
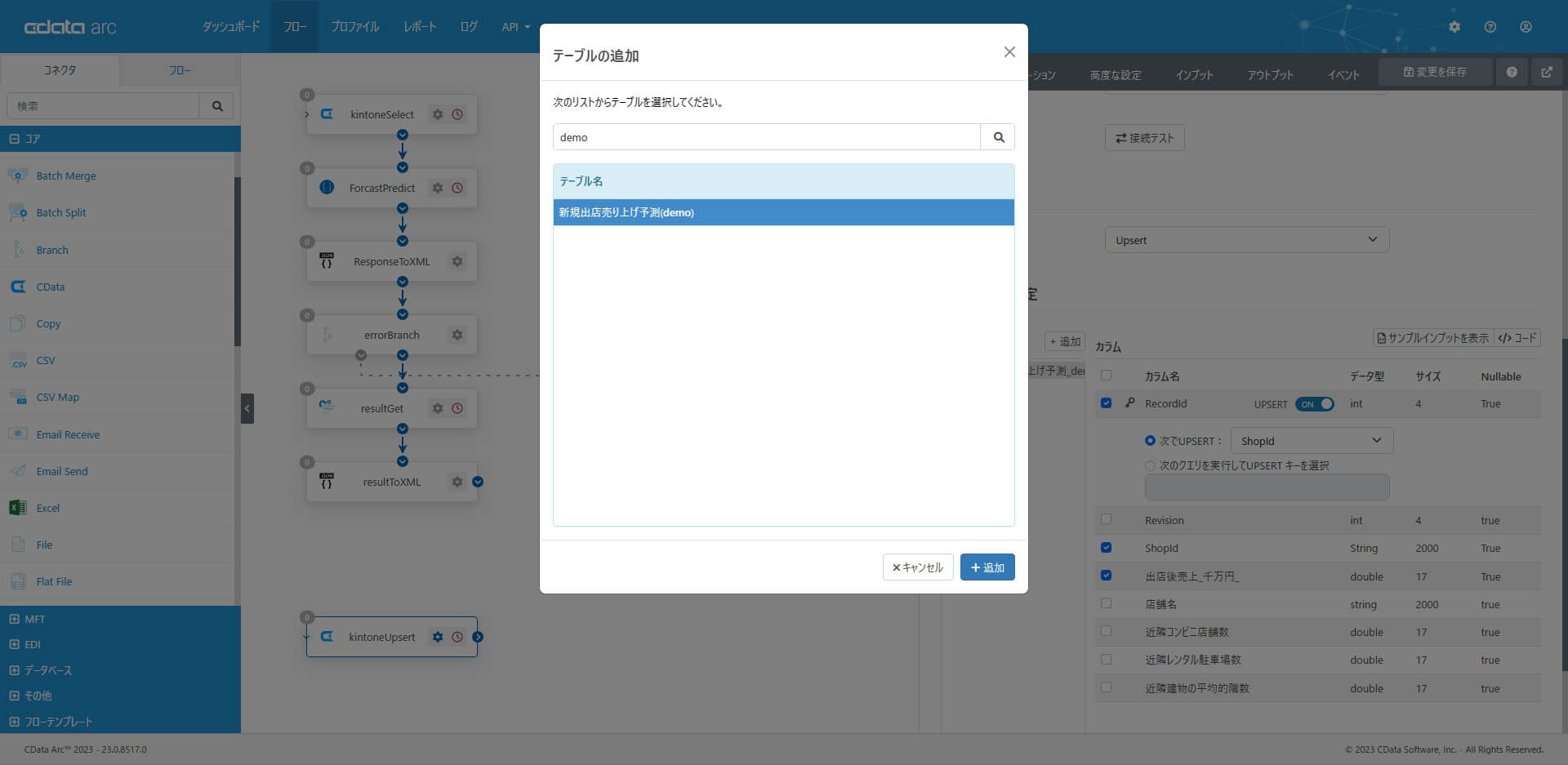
カラム設定で、key と更新対象のカラム(列)を選択します。「次でUPSERT」で指定できるUpsert 時のkey には「ShopId」を指定しています。
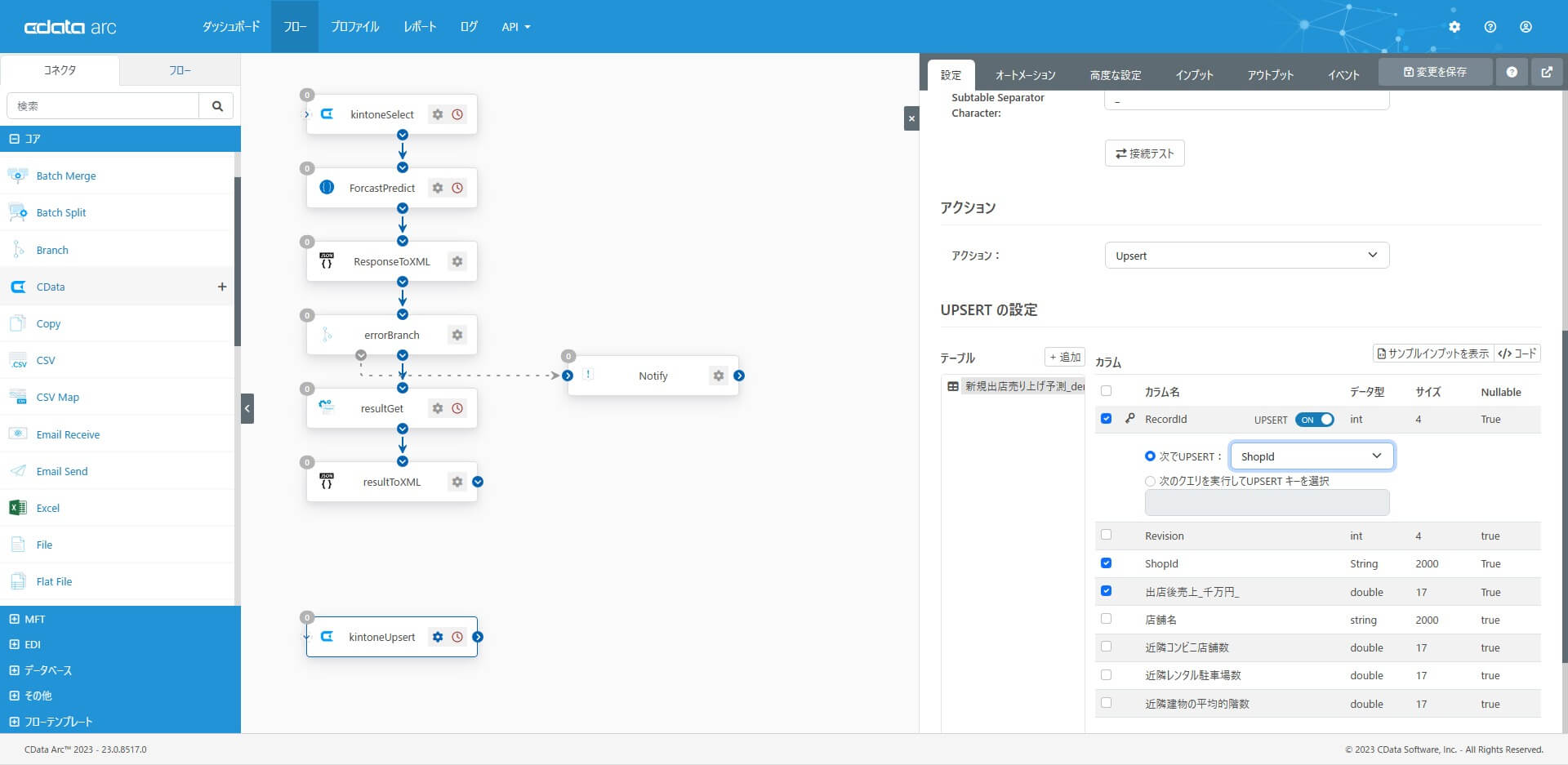
8. XMLMap コネクタ
XMLMap コネクタを配置し「7 のデータを9 にマッピング」するための設定をします。コアカテゴリから「XMLMap コネクタ」を選択・配置します。
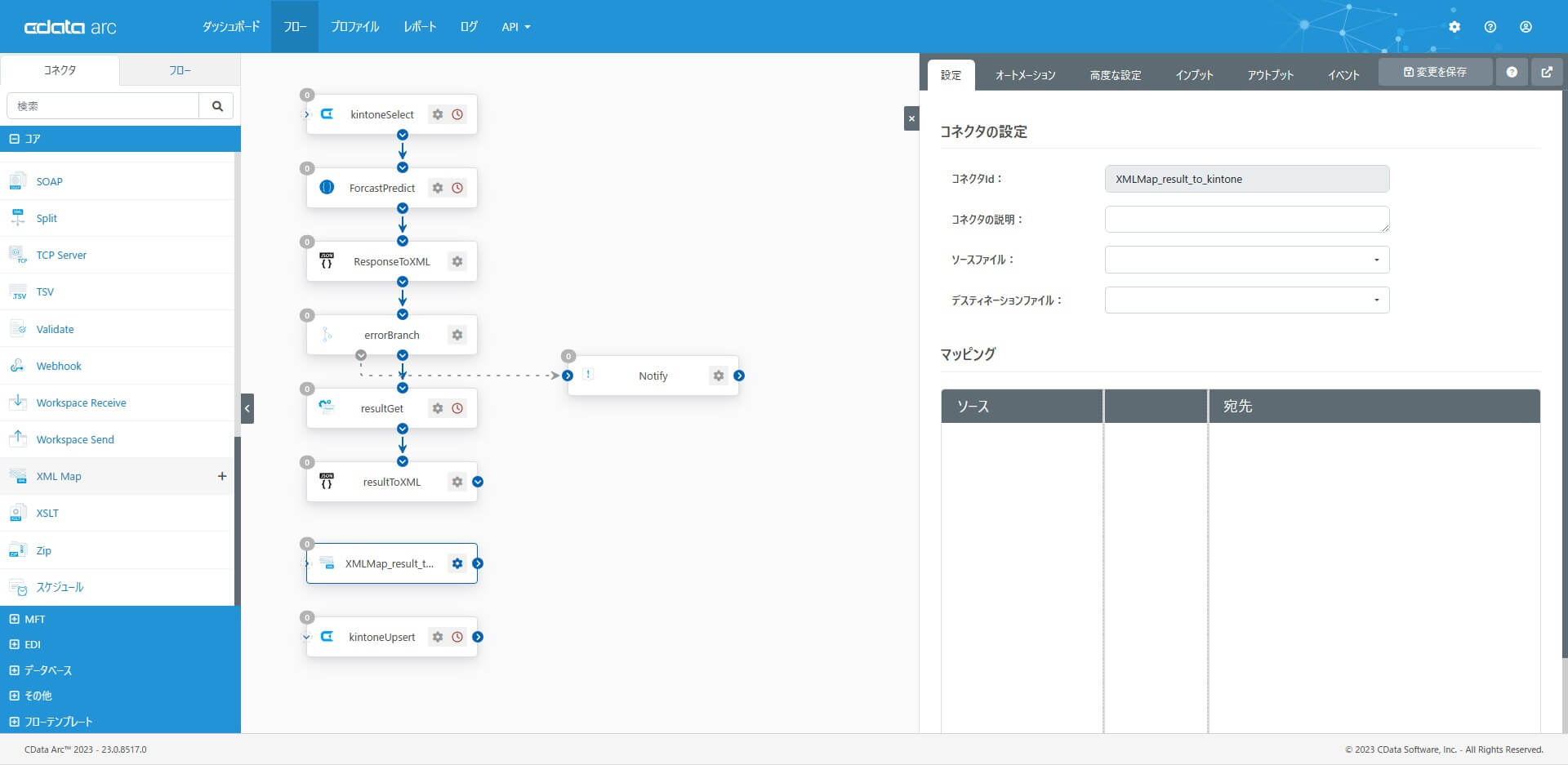
フローをつなぐと、ソースファイル・デスティネーションファイルが選択できるようになり、マッピングでは同名項目は自動的にマッピングされます。
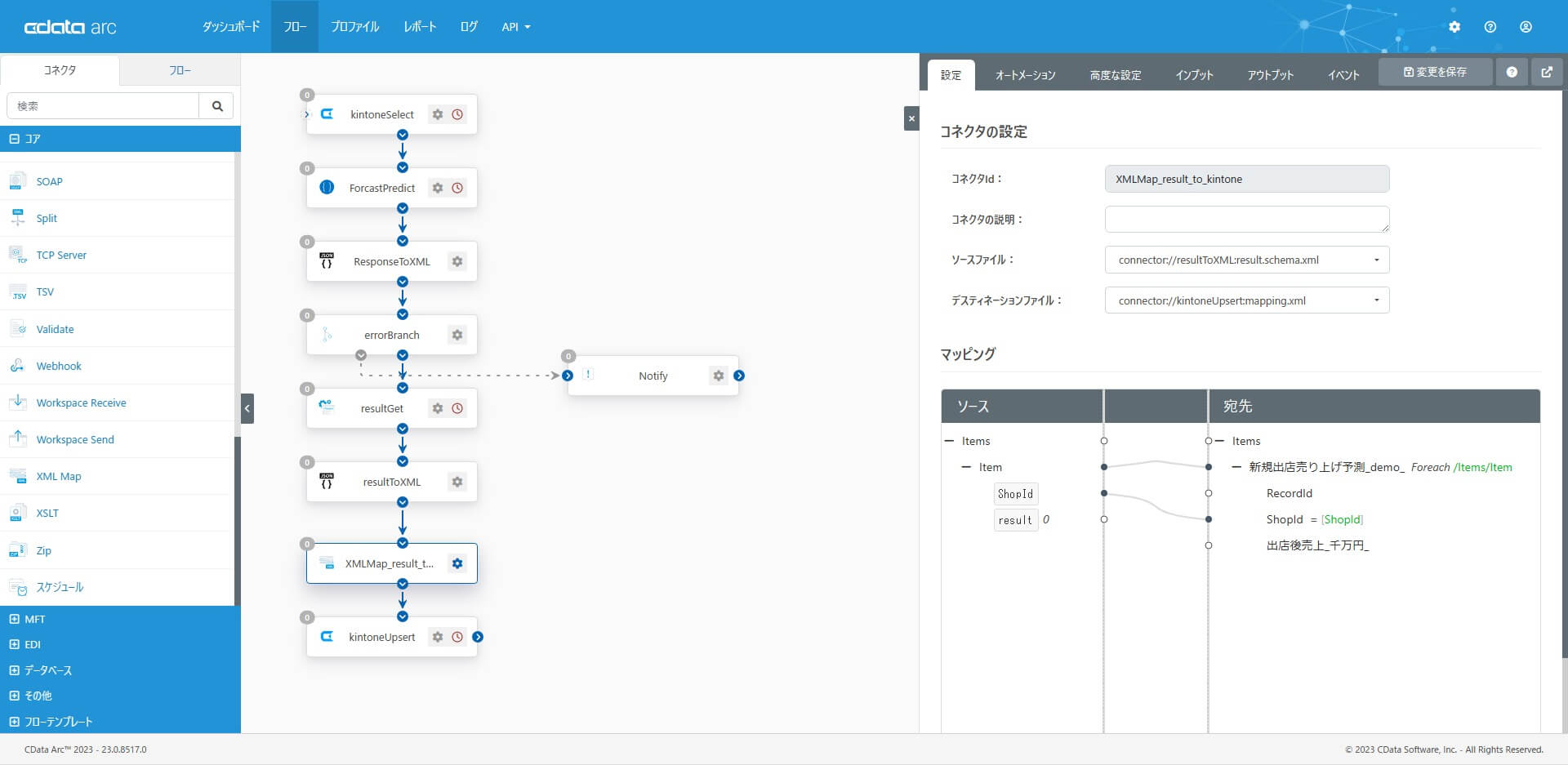
予測結果の予測値である「result」を、kintone の「出店後売上」にマッピングします。
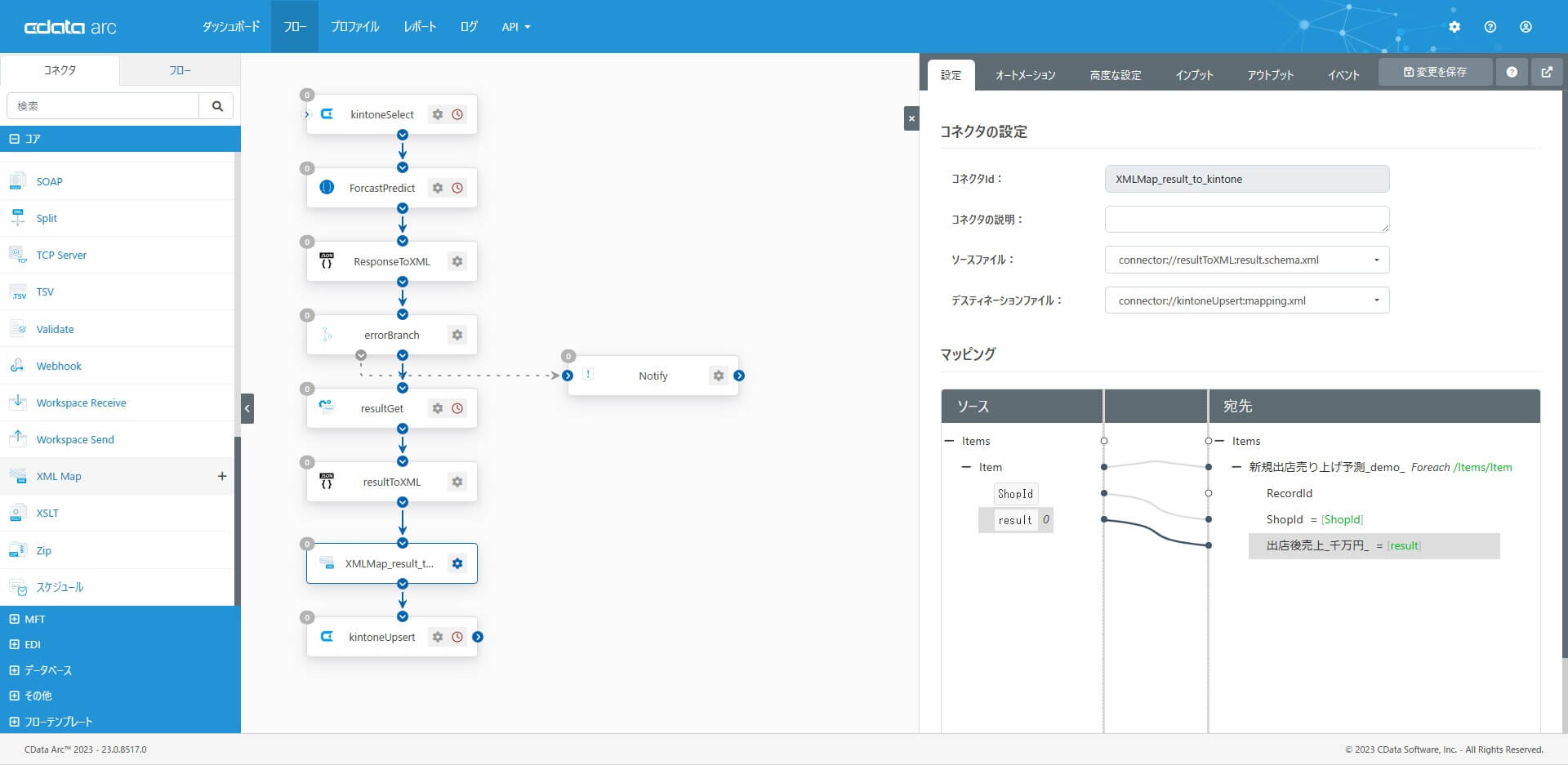
これで「AnyData で構築したAI モデルに対して、kintone から予測データを収集し、AI での予測を実行して、予測結果をkintone に連携する」フローができあがりました。
連携フローの実行と確認
作成したフローを実行して確認してみましょう。
起点となるCData コネクタからフローを実行してみます。アウトプットタブから「受信」を実行します。
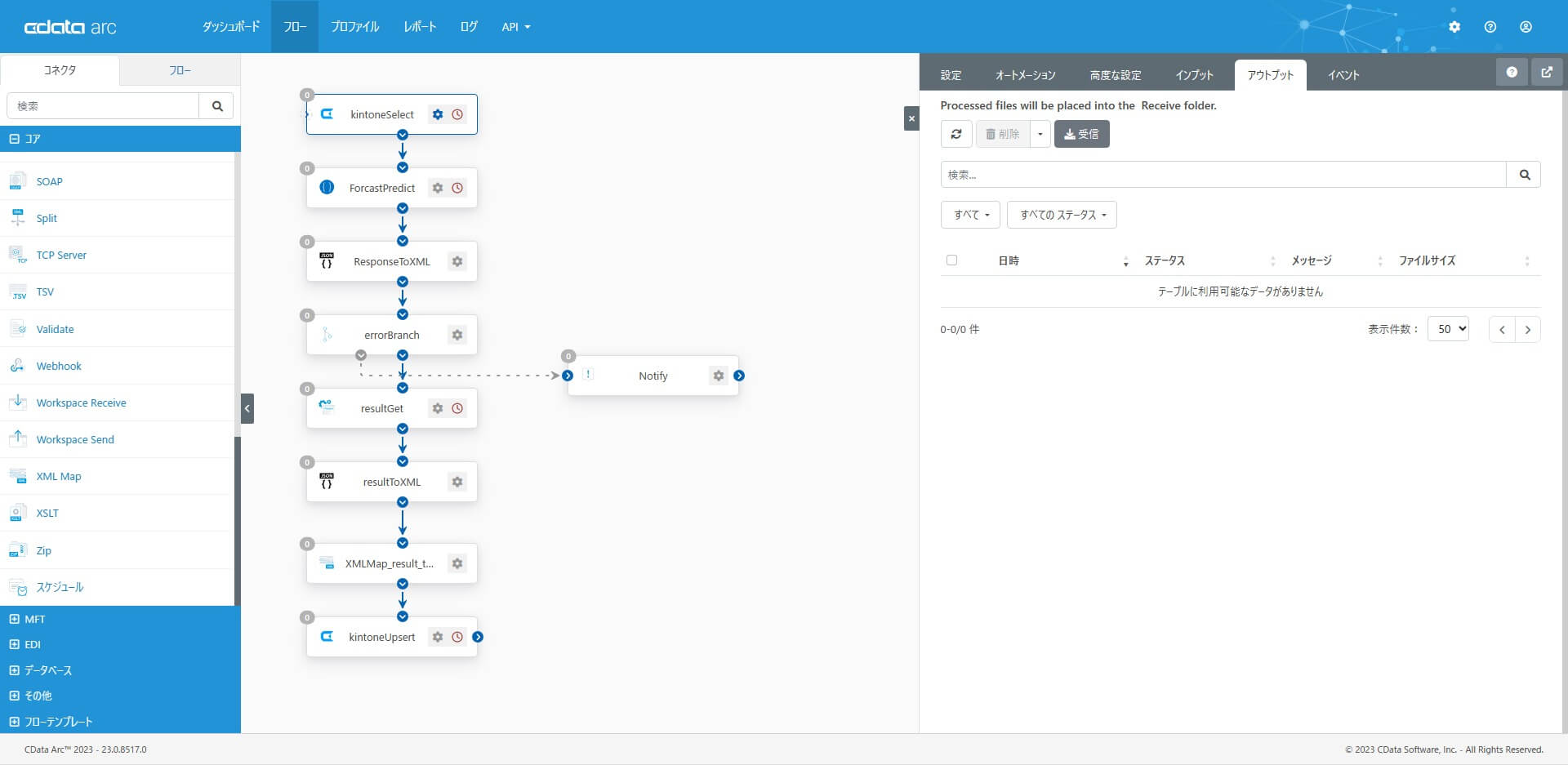
フローの終点となるCData コネクタ(kintone)のインプットタブの結果を確認します。kintone への更新実行の成功が確認できます。
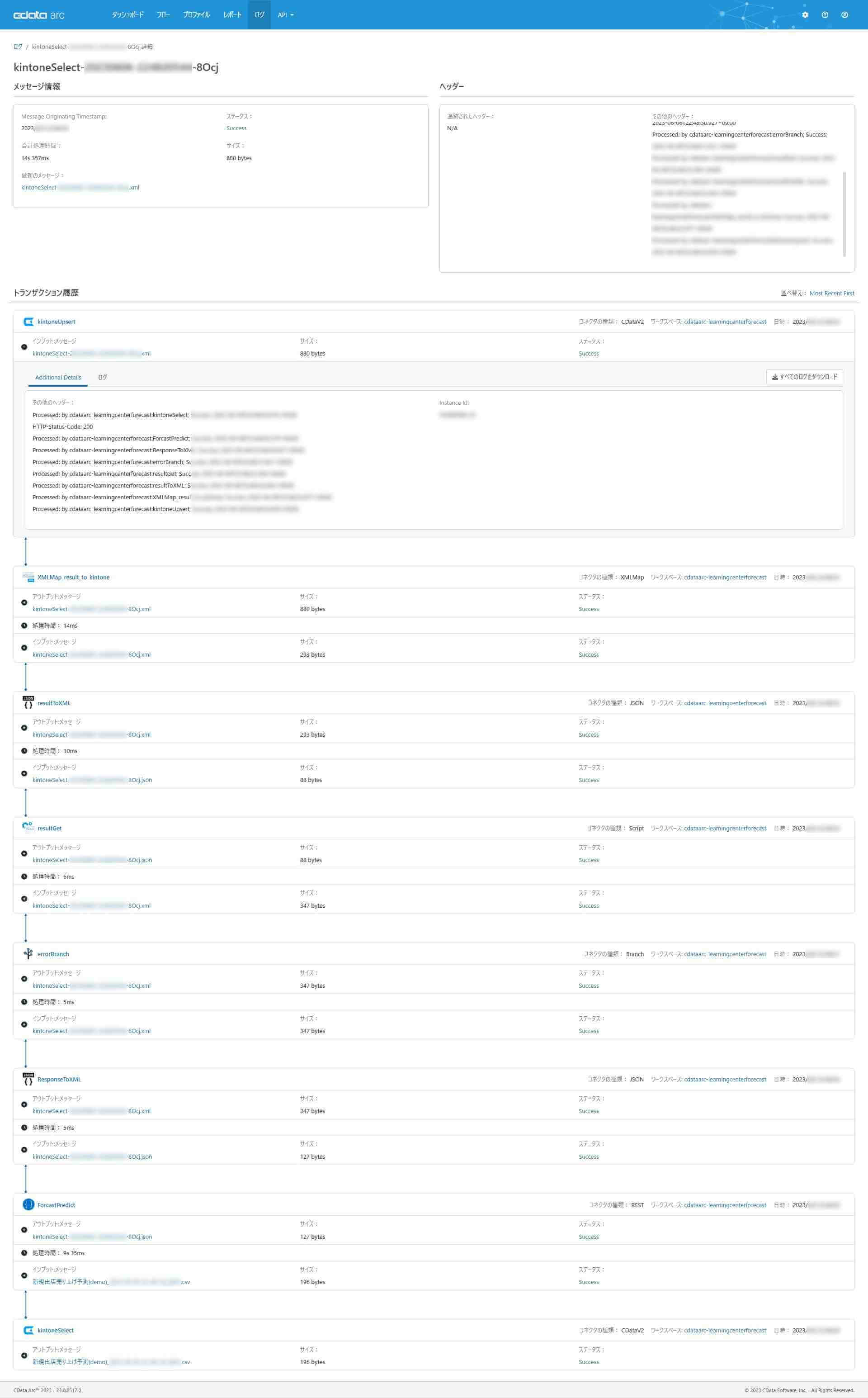
「詳しくはこちら」から表示できるメッセージビューアで、フローの一連の実行状況を確認します。
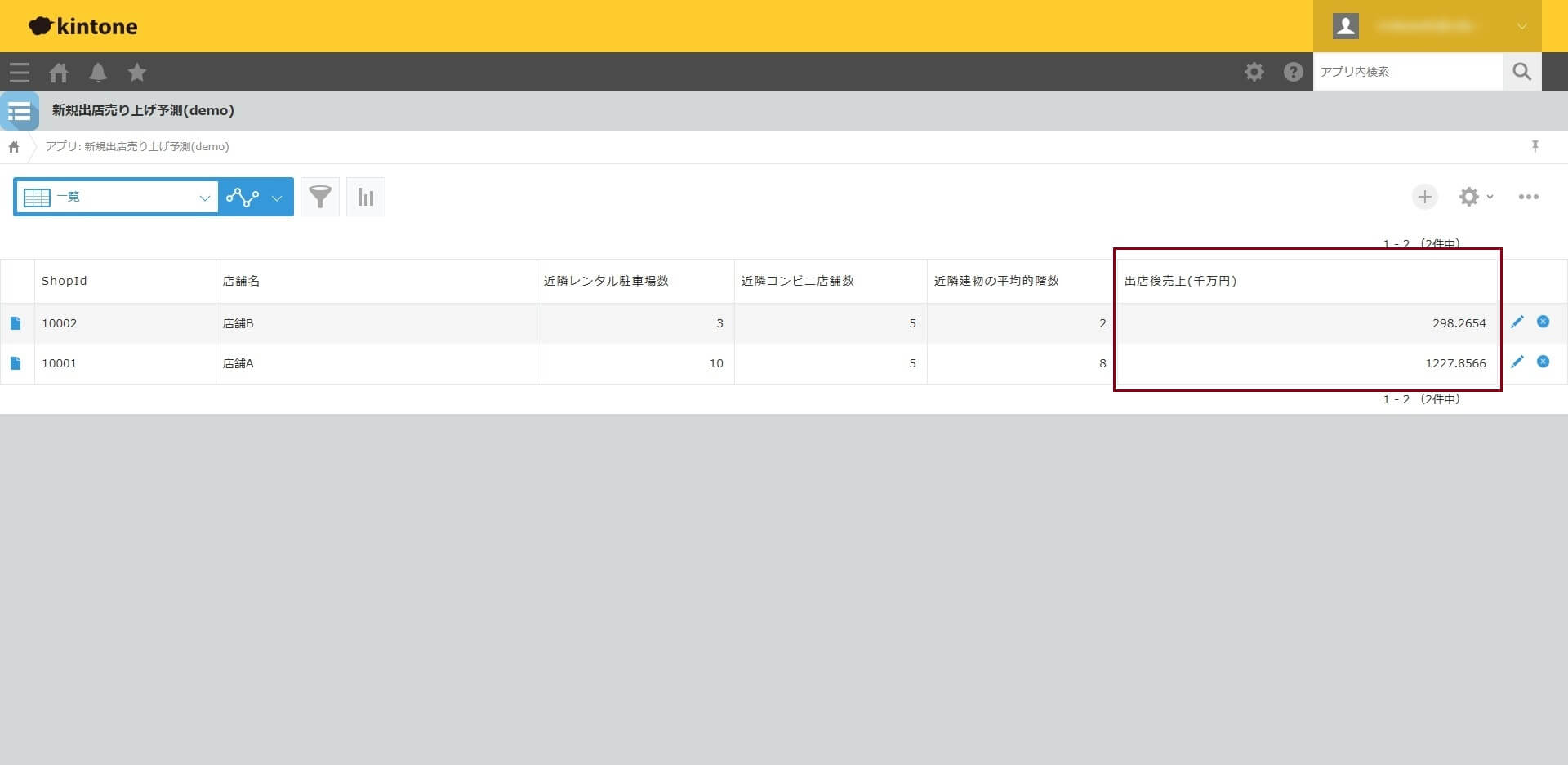
kintone へ予測された「出店後売上」が連携されていることが確認できます。
シナリオの自動実行
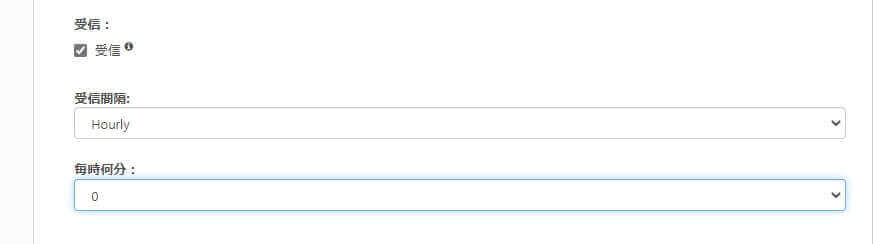
CData Arc ではフローを定期実行するスケジューラ機能を持っています。今回のシナリオであれば、フローの起点となるコネクタの「オートメーション」タブで設定することができます。1時間に1度、毎時0分に定期実行する場合は、このように設定します。
おわりに
さまざまな業務領域でAI の活用が進んでいますが、効率的で簡易化されたUI/UX でAI の民主化を強力にサポートするマルチモーダルなAI 統合基盤「AnyData」と、業界最多級の連携先を誇るCData Arc とCData Drivers を組み合わせれば、さまざまな分野でのAI 活用とその自動化をノーコード&ローコストで実現することができます。
CData Arc はシンプルで拡張性の高いコアフレームワークに、豊富なMFT・EDI・エンタープライズコネクタを備えたパワフルな製品です。CData Drivers との組み合わせで250を超えるアプリケーションへの連携を実現できます。必要な連携を低価格からはじめられる事も大きな特長です。
皆さんのつなぎたいシナリオでぜひ CData Arc を試してみてください。
製品を試していただく中で何かご不明な点があれば、テクニカルサポートへお気軽にお問い合わせください。
この記事では CData Arc™ 2023 - 23.0.8517.0 を利用しています。