ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →






BigQuery やSnowflake などのデータソース側で提供される独自関数をNATIVEQUERY 機能を使ってDriver 経由で利用可能に!
こんにちは、プロダクトチームの宮本です。
BigQuery や Snowflake などのSQL が実行できる各種サービス先にはそれぞれ便利な関数が多数用意されているかと思います。例えばBigQuery ではArray 型のカラムであったり、Repeated カラムとして親子関係のレコードを作成することができますが、それらをフラット化して取得するためにはUNSET というBigQuery で用意されている関数で取得する必要があります。
このようなケースの場合、CData Driver を通して利用するにはQueryPassthrough というオプションを有効にしてしなければいけませんでした。
しかしQueryPassthrough を有効にするということは、その接続情報を利用したSQL は全てクライアント側からそのままデータソース側に送るという意味になるので、データソース側で対応していない関数の使用や一時テーブルを利用したバルクインサートなどを利用することができなくなってしまいますし、接続情報側でオンオフをいちいち切り替えることになるとCData Driver を組み込んでいるようなツールやサービス上では複雑さが増してしまいます。
そこで今回CData Driver では、NATIVEQUERY という機能を新たに追加し、接続情報を変えずに直接データソース先で実行させたい内容をクエリに組み込んで利用することが可能になりました。
では実際にNATIVEQUERY 機能の使い方をご紹介していきます。
クライアント側からBigQuery のPIVOT 関数を利用してみる
BigQuery コンソール画面から確認
BigQuery で以下のように縦持ちしているレコードをPIVOT 関数を用いて横持ちすることが可能です。
まずはテーブルに保存されているレコード。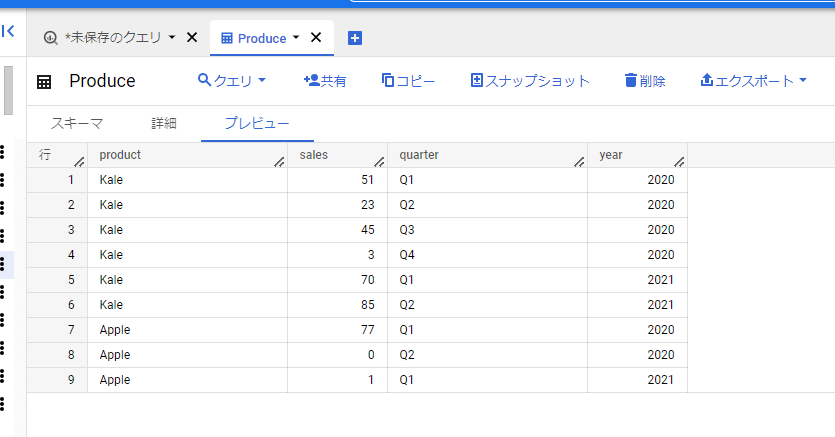
※レコードは公式リファレンスにあるものと同じ
クエリ構文 | BigQuery | Google Cloud
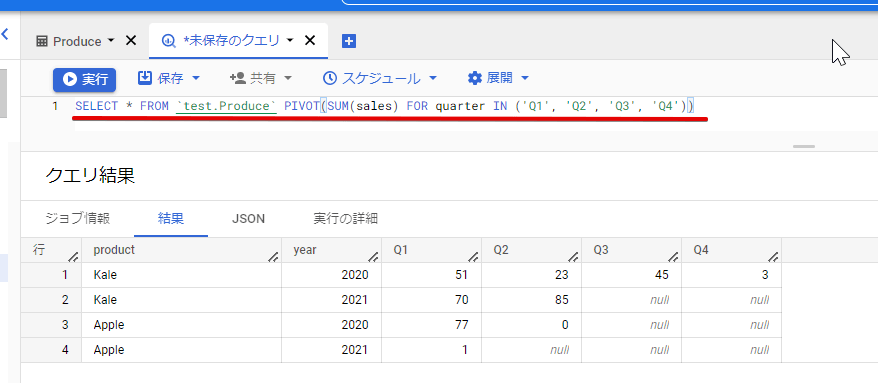
これをBigQuery コンソール画面でPIVOT 関数を使うと当該年のproduct ごとに横持ちに変換して表示させることができます。
CData BigQuery JDBC Driver のインストール&接続
今回はJDBC Driver を利用していますが、JDBC Driver 以外でも確認できます。
ではさっそくJDBC Driver をダウンロード/インストールしてみましょう。
最初に以下のURL よりCData BigQuery JDBC Driver のページを開き、ダウンロードボタンからインストーラーをダウンロードします。
BigQuery JDBC Driver: JDBC Driver for BigQuery - CData Software Japan
ダウンロード後そのままインストーラーを実行し、全て次へで進みます。

これでインストールが完了です。
今回、JDBC Driver はDbVisualizer というDB クライアントツールを使って確認します。
DbVisualizer でサードパーティ製Driver を利用する場合は、Tools → Driver Manager... から事前に登録しておく必要があります。
Driver 登録が完了したら接続文字列をセットしてBigQuery に接続します。

※接続方法についてはこちらをご参照下さい。
CData JDBC Driver for Google BigQuery - 接続の確立
CData BigQuery JDBC Driver から実行
今回はJDBC Driver を利用していますが、JDBC 以外のドライバーでも確認できます。
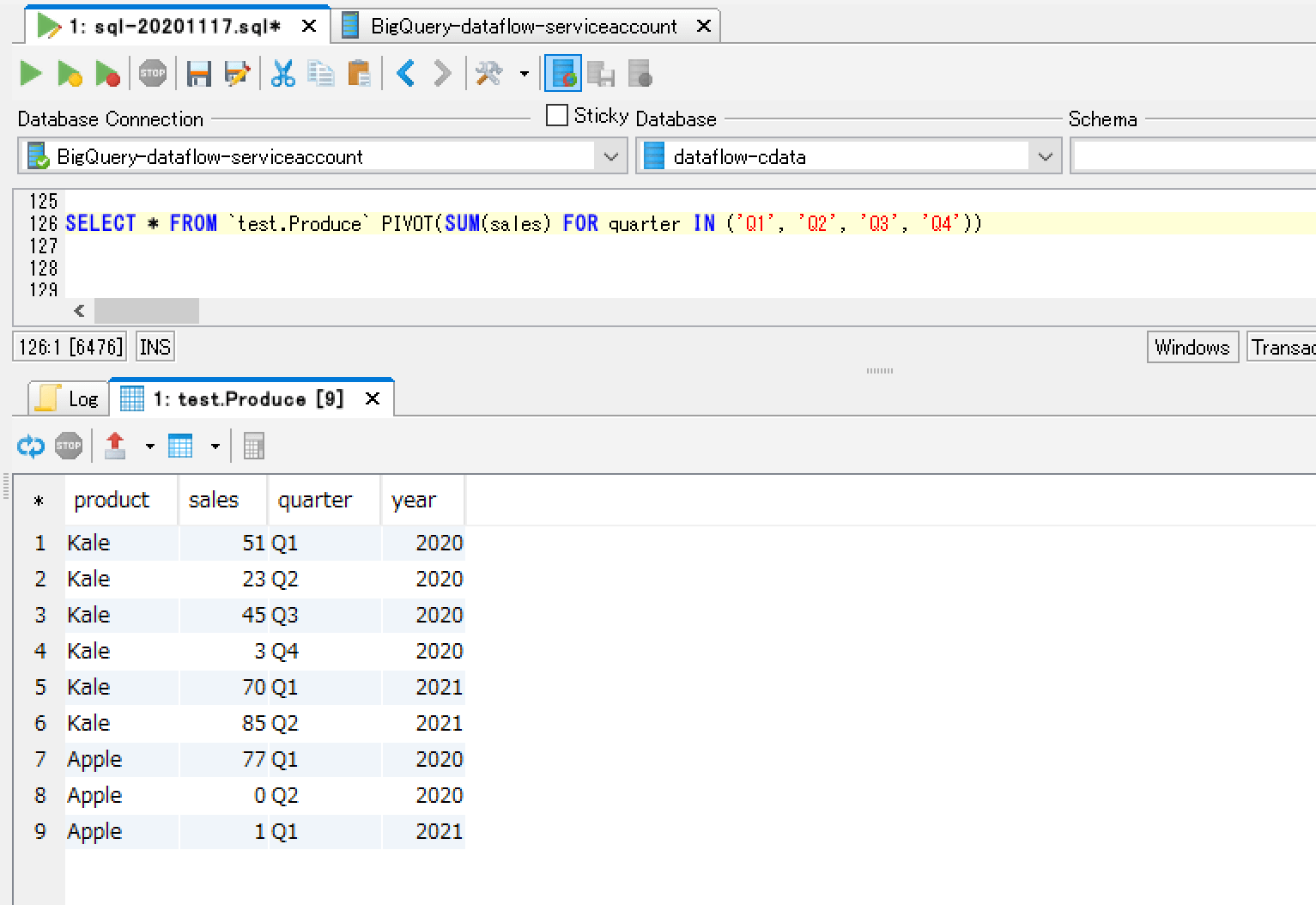
では先ほどBigQuery コンソール画面で実行したクエリをそのまま貼り付けて実行してみましょう。
SELECT * FROM `test.Produce` PIVOT(SUM(sales) FOR quarter IN ('Q1', 'Q2', 'Q3', 'Q4'))
そうするとテーブルの内容がそのまま表示されました。
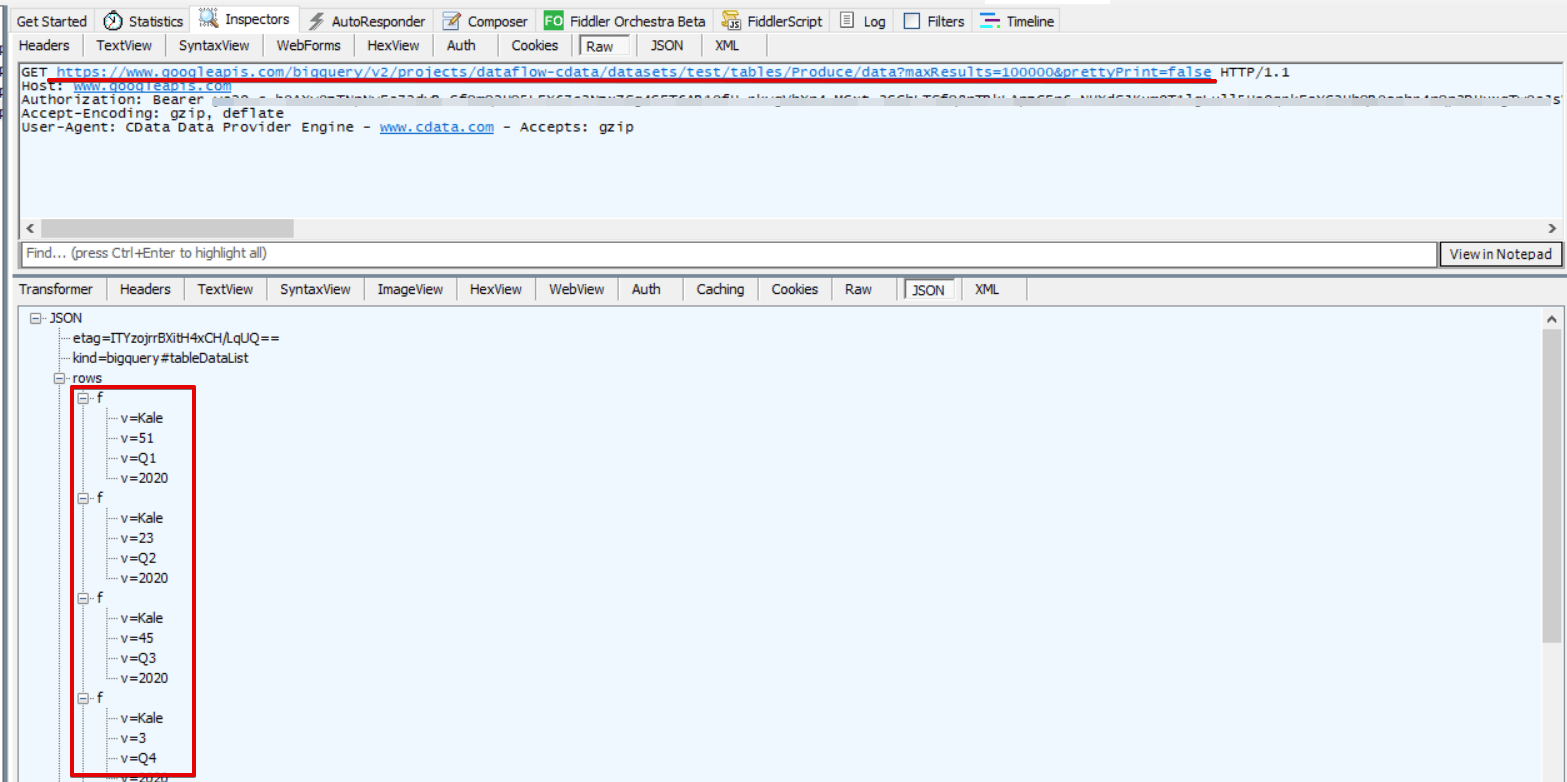
このときのリクエスト内容はテーブルに格納されている全レコードを取得するものとなっています。
これはPIVOT 関数がCData Driver では認識できない関数となっていることで、そこを切り捨てた内容で解釈されリクエストされていました。
ここで今回追加されたNATIVEQUERY 機能を使うと、接続情報を変更せずともデータソース先の関数も指定することができるようになります。
使い方は、FROM 句にNATIVEQUERY(データソース側で実行したいクエリ) という形式で指定し実行します。
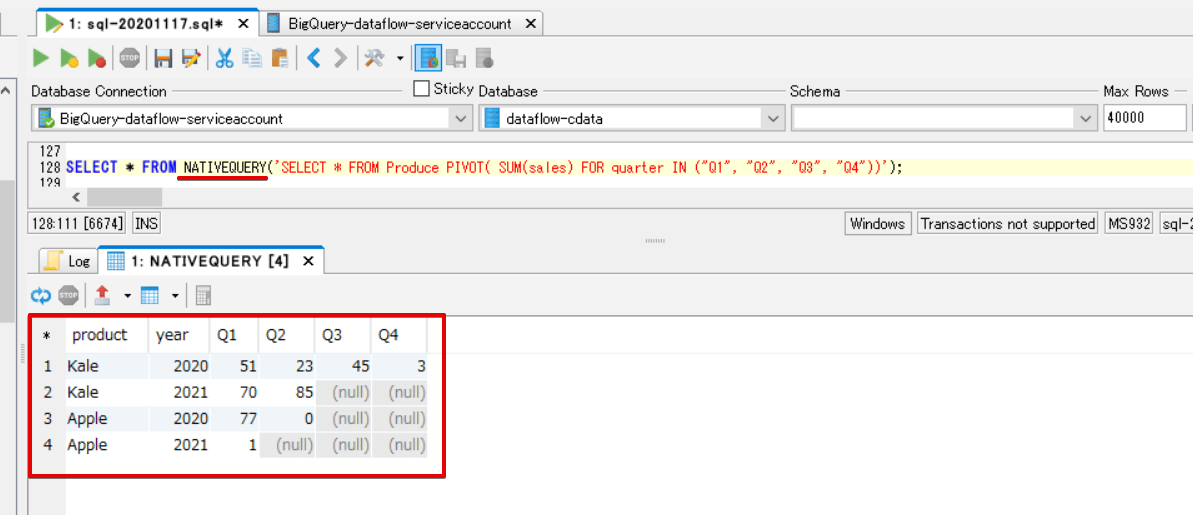
では、以下のクエリを実行してみましょう。
SELECT * FROM NATIVEQUERY('SELECT * FROM Produce PIVOT( SUM(sales) FOR quarter IN ("Q1", "Q2", "Q3", "Q4"))');
すると、BigQuery コンソール画面で取得した結果と同じ内容が表示されました!
このNATIVEQUERY は指定した内容をそのままデータソース側に送信する仕組みなので、
このようにテーブル作成の指定も可能です。(戻り値の関係上クライアント側にはエラーが表示される可能性はあります)
SELECT * FROM NATIVEQUERY('CREATE Table `test.Produce3` (Id int,Name String,Campany String);');
ということから、select しか実行できないサービス、ツールからも柔軟に更新系やDDL 関連の実行も可能になりそうです。
おわりに
NATIVEQUERY 機能についていかがでしたでしょうか。今回の利用ケースはほんの一例でありますが、as-is でクライアントで指定したクエリをデータソース側に送信できる機能であるため、さらに幅広いケースにも対応できるのではと思っています。
ご紹介した Cdata BigQuery JDBC Driver をはじめ、CData 製品は全て30日間の無償トライアル利用が可能です。
CData Software Japan - JDBC Drivers
トライアル中からサポートデスクへの問合せも可能ですので、ぜひCData Driver をお試しください!