Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



CData Architecture: Core Driver Services
Welcome to Part 3 in the series of blog posts on our CData Driver architecture. I mentioned in Part 2 of this series (Supporting Multiple Technologies) that our core code base has several different services offered to provider implementations. Some of these are generic services used by each provider, while others simplify the implementation of a certain class of provider.
This post will focus on the driver services:
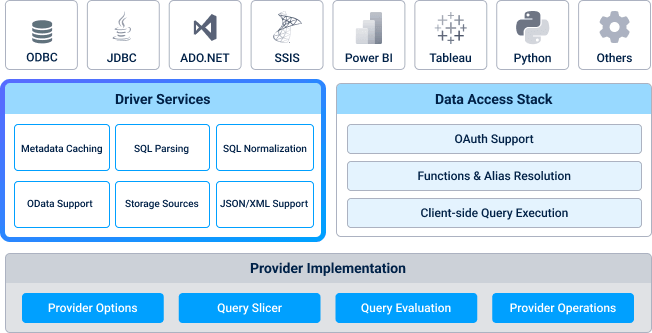
Metadata caching
Metadata is a critical part of every data access driver. Every provider implementation needs to support basic metadata operations, such as:
- Querying the list of tables and views in the data source.
- Querying the list of columns on a table/view.
- Querying other objects such as stored procedures, indexes, and so forth.
We've discussed some challenges around metadata already in a previous post, but one of the most common challenges is that, for many technologies, obtaining metadata from the data source can be very expensive.
Our metadata layer is architected in such a way that every driver provides metadata in a common format (which is also extensible, if needed) while providing significant performance advantages by transparently caching the discovered metadata.
By default, metadata is cached in memory and refreshed periodically, but our metadata caching service is also capable of caching metadata in an external repository, such as a Derby or SQLite database.
One challenge we've faced in our in-memory metadata caching service implementation is supporting data sources with large, complex data models. Optimizing our internal metadata cache and metadata discovery process has been a priority.
SQL normalization
The SQL normalization engine is another key component of the CData Driver model. When our provider receives a SQL query, it typically applies a set of normalization rules to the query before attempting to execute it.
What do we mean by SQL normalization?
A SQL normalization rule is merely a transformation of the query Abstract Syntax Tree (AST) that preserves the meaning of the query. This transformation simplifies driver implementation by making it easier to interpret the query based on some assumptions about the shape of the query.
Why is this important? To support all the most popular business intelligence and analytics tools, our drivers must support diverse query capabilities. These tools generate SQL statements automatically based on their internal rules. Often at first glance, these queries seem very complex but express simple concepts. For example, a tool might generate a nested SELECT statement that could be simplified into a single one.
We currently have over twenty different common normalization rules (and more that are provider-specific), so I'm not going to discuss every single one. However, let me mention a few examples to illustrate the point.
One trivial normalization to apply is to column references in the WHERE clause. A query could contain something like, "... WHERE 5000 < revenue", which we can normalize so that the column reference always appears on the left side of the expression: "... WHERE revenue > 5000" .
A more interesting example could be criteria minimization. Reporting tools often use tricks, such as adding "... AND (1=1)" in the WHERE clause. Since this always returns true, we can safely remove it from the query if the right conditions are present, so that the provider-specific code doesn't have to deal with it.
For each provider we build, we select the right set of normalizations to apply automatically during query processing. For some providers, we can also do additional transformations that take advantage of source-specific query capabilities to make queries run correctly or faster.
OData support
A significant number of CData Drivers are for data sources that expose OData endpoints. We also have a generic . Thus, it made sense to create a reusable, core OData implementation that simplified the implementation of additional drivers based on the standard.
This shared component takes care of tasks, such as:
- Reading and interpreting OData service and metadata documents
- Core implementations for OData data operations (both queries and data modification)
- Support for ATOM and JSON (JavaScript Object Notation) formats, and OData version differences
For most OData-based drivers, this shared component is invoked directly from the provider implementation.
Other services
There are other services in our driver core, including some that are not presented in the architecture diagram, such as:
- A connection pool implementation to reduce the cost of opening and closing connections
- Bulk Row Manager, which implements bulk data update support
- RowScan, which is our shared implementation for supporting scanning data rows from tables to dynamically discover column metadata
- Page Providers, which support retrieving result sets in pages for drivers created using our internal framework
- Parallel Fetch supports fetching pages both serially, as well as in parallel for increased performance
Conclusion
In this third post in the series, we have covered some of the services implemented as part of our driver code to simplify the development of a new driver.
- Read Part 1: Key Considerations for Data Driver Development
- Read Part 2: CData Architecture: Supporting Multiple Technologies
In the next post, we'll discuss the core driver model, and how queries are executed.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers