Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



CData Architecture: Query Execution
This is Part 4 of a series of blog posts on our driver architecture. In previous posts, we discussed how we support various driver and adapter technologies, as well as other core driver services.
Read the series here:
- Part 1: Key Considerations for Data Driver Development
- Part 2: Supporting Multiple Technologies
- Part 3: Core Driver Services
This time, we'll focus on the data access stack (the right side of the middle layer) as well as the provider implementation (the bottom layer):
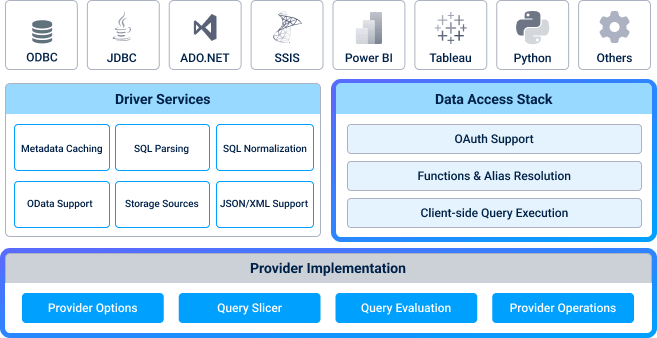
Data access chain
Query execution in our providers always flows through a data access chain (DAC). The DAC is a set of objects that implement core driver functionality through an interface called IDataAccess. It provides the following services:
- Opening and closing a transport connection
- Metadata queries
- Query and command execution
Data access objects are stacked in a chain in such a way that the upper layers can either completely intercept any operation or do pre- or post-processing of the operation before or after the next IDataAccess object in the chain.
A driver for a full database could have a simple data access chain consisting of a single element: the driver implementation itself. However, other drivers take advantage of the different layers to augment the data source capabilities as needed.
While we use several different implementations, there are a few that are more important and used by many drivers.
OAuth support
Providers that support the use of the OAuth protocol for authentication require complex logic to implement the protocol itself and obtain or refresh OAuth tokens. To make this simpler, we use an IDataAccess implementation that takes care of the work of ensuring that the connection has a valid OAuth token before the commands get to the driver.
This layer can also take care of persisting and refreshing tokens as necessary.
Function and alias resolution
For data sources with limited query capabilities, we have an IDataAccess implementation that handles transformations of the SQL query AST to make it simpler for the driver to interpret. These transformations can include things like:
- Resolving table aliases in column references.
- Expanding
*inSELECTreferences based on schema information (if possible). - Resolving function definitions in expressions. Some providers have native functions that may be evaluated server-side, but our query engine can augment these with functions that are evaluated client-side in this layer.
Client-side query engine
This component was built to support complex queries on providers that have limited query capabilities. It interacts with the provider implementation to evaluate a query and determine which parts of the query the data source can execute by itself and which parts must be completed client-side.
The goal of this analysis is to make smart decisions based on the query capabilities of the data source to push down as much of the computation as possible. How do the provider and the client-side query engine work together to achieve this? Through two different abstractions:
The provider's Query Evaluation component examines a SQL query and returns information indicating what parts of the query the driver is not capable of executing natively. For example, a provider could tell the client-side query engine that it can execute a operation but only for specific selectors.
Another example is a provider for a data source that supports filtering results natively but with limitations. Some data sources are capable of filtering based only on specific fields. Others allow filtering based only on equality comparisons but can't use other comparison operators.
The provider's Query Slicer component is used in more specific cases to break a single query into multiple independent queries. For example, consider a query such as:
SELECT * FROM Documents WHERE DocId IN (123, 342, 874)
If the data source only supports retrieving a single document given its ID, one way to execute this query is to slice it into 3 separate queries:
SELECT * FROM Documents WHERE DocId = 123 SELECT * FROM Documents WHERE DocId = 342 SELECT * FROM Documents WHERE DocId = 874
Based on the results of these evaluations, the client-side query engine will make decisions about how to:
- Simplify a query into something the provider can execute. This could involve, for example, simplifying the criteria in the
WHEREclause to produce a superset of the desired results and then filter them further client-side. - Break down complex queries into multiple queries if necessary. This could include, for example, queries involving joins, subqueries, or nested queries. It could also include cases in which the results of one query are used to build one or more additional queries to the data source.
- Push down aggregations or compute them client-side while minimizing the size of the result set produced by the data source.
Of course, there's a significant trade-off in evaluating queries, even partially, client-side. There will always be queries that are impossible to execute efficiently in this model, and some can be particularly expensive to compute in this manner. Our guiding principle is always to push down as much of the query as we can for the data source, to generate the most efficient query possible, but to also provide our customers with the most flexible query capabilities to meet their needs.
This efficiency is particularly important for customers using our drivers in business intelligence and data analytics/visualization tools, which generate highly complex queries that often cannot be computed natively in any way by the underlying data sources.
Result set chains
Before looking at the provider implementation components, it's worth mentioning how result sets are represented in our driver model. Result Set objects are produced by IDataAccess implementations as the result of executing a query.
A result set is represented as an object implementing the IResultSet interface, which includes:
- Obtaining metadata about the result set columns
- Iterating over results
- Obtaining values from columns for the current row
Just like IDataAccess, result sets can be layered. That is, an IDataAccess implementation might call the next element in the chain to execute a query, and then wrap the resulting IResultSet object to augment it or change its shape. This is exactly how the function and alias resolution component works.
Provider implementation
We have two options when implementing a new provider:
- Create a completely new, driver-specific
IDataAccessimplementation - Create the driver using a separate, internal framework that hooks into an existing generic
IDataAccessimplementation
Our decision here is basically around protocol vs. non-protocol drivers: For a provider that requires a custom transport protocol or is a full database system, we typically implement a new IDataAccess layer. For REST and OData-based drivers, we often use the second option. The framework used for the latter contains a lot of useful functionality to simplify driver development and handles many common scenarios, such as retrieving result sets in pages (including fetching pages in parallel).
Other than the data access chain, some key components are present in all providers, either as provider-specific implementations or by reusing base implementations in our framework. In this category, we find the Query Evaluation and Query Slicer components.
The one part that is mandatory for all providers is Provider Options, which configure much of the behavior of the upper layers and the request processing.
This includes:
- Configuring the
IDataAccesschain for the provider. - Configuring the Query Evaluation and Query Slicer components for the driver.
- Configuring global options and flags for the driver, such as:
- Does this driver support bulk operations?
- What SQL normalization rules should be applied by default?
- Registering which functions can be evaluated natively server-side by the data source.
- Does the data source support multiple schemas?
- Does the data source have static or dynamic schema?
Conclusion
Now that we've reached the end of the series, there are some key takeaways:
- Our framework based around code generation on the front end allows us to build native drivers to support different driver/adapter technologies. Our flexible, extensible model makes it very easy to support new ones.
- All drivers function consistently across technologies, with updates and improvements supported across the board.
- We're constantly improving our driver capabilities. We've built a flexible framework that allows us to improve or add new facilities once, while having multiple—if not all—drivers reap the rewards.
- Performance is a key consideration in our development process. We are constantly researching how we can improve our driver performance and applying lessons learned across our entire driver portfolio.
I hope this overview of our driver architecture has been useful and gives you a good idea of how we develop, maintain, and support more than 250 data sources across every major data access technology stack sustainably.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers