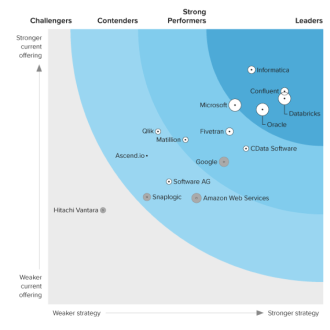
Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



Cassandra ETL/ELT Data Pipeline
Automated Replication to popular Databases, Data Lakes, & Data Warehouses
- Straightforward automated data replication.
- Synchronize data with 100+ destinations.
- Easy-to-use ETL/ELT data movement.
Download Now Start the Product Tour
Other Drivers
-
![Apache HBase]()
-
![Apache Avro]()
Apache Avro
learn more » -
![Apache CouchDB]()
Apache CouchDB
learn more » -
![Apache HDFS]()
Apache HDFS
learn more » -
![Apache Hive]()
Apache Hive
learn more » -
![Apache Impala]()
Apache Impala
learn more » -
![Apache Kafka]()
Apache Kafka
learn more » -
![Apache Parquet]()
Apache Parquet
learn more » -
![Apache Phoenix]()
Apache Phoenix
learn more » -
![Apache Spark SQL]()
Apache Spark SQL
learn more »
Cassandra is one of more than 200 data sources included in CData Sync [learn more].

CData Sync provides a straightforward way to continuously pipeline your Apache Cassandra data to any Database, Data Lake, or Data Warehouse, making it easily available to Analytics, Reporting, AI, and Machine Learning.
- Synchronize data with a wide range of traditional and emerging databases.
- Replicate Apache Cassandra to RDBMS systems to facilitate operational reporting.
- Offload queries from operational systems to reduce load and increase performance.
- Connect Apache Cassandra to analytics for BI and decision support.
- Archive data for disaster recovery.
Automated Continuous Data Replication
CData Sync provides users with a straightforward way to synchronize data from Cassandra with a wide range of traditional and emerging databases including:
MySQL
SQL Server
Azure SQL
Amazon Redshift
Amazon S3
Google BigQuery
DB2
Oracle
Couchbase
Snowflake
CSV/TSV
MariaDB
SAP HANA
Apache Kafka
Azure Blob Storage
Azure Event Hubs
Azure Data Lakes
PostgreSQL
Azure Synapse
Vertica
Databricks
MongoDB
SingleStore
Teradata
Google AlloyDB
Salesforce
Google Cloud Storage
Oracle Autonomous
MySQL HeatWave
Key Features
Replicate Any Data Source To Any Database With a Few Clicks
-
Simple Point-And-Click Replication
Configuring replication is easy: Login to the application, select the tables of data to replicate, and select a replication interval. Done.
-
Heterogeneous Support & Database Independence
Supports replication across a wide range of commonly used databases, ensuring offline replication without the need to setup and maintain a new or foreign DBMS. In addition, database connectivity is extensible, providing systems integrators with the ability to synchronize with entirely new data stores.
-
Automated Iterative Data Extraction
CData Sync extracts data iteratively, causing minimal impact on operational systems by only querying and updating data that has been added or changed since the last update.
-
Full or Partial Data Replication
Users have complete control to define which data should be replicated and how that data should be replicated to a database. CData Sync offers the utmost in flexibility across full and partial replication scenarios.
-
Secure Backup & Archiving
Protect your organization from the loss of valuable data. CData Sync ensures that your critical data is stored safely in the on-premise or cloud database of choice.
-
DBA-Friendly Setup
CData Sync is completely self-contained. As a result it does not require special administration or installation on target databases.
-
Flexible Mapping, Configuring, & Scheduling
CData Sync is incredibly simple, yet highly customizable. Almost every facet of the application can be customized to integrate with the user's ideal replication configuration.
-
Unix Cron-Style Scheduling
CData Sync includes flexible scheduling capabilities. Users can easily schedule replication tasks at customizable intervals.
-
Dynamic Schema Replication
Replicates schema changes dynamically, ensuring that data sources are in sync. CData Sync monitors changes in the connected datasource and the changes are automatically detected and updated within the local replicated database.
-
Advanced Logging & Transaction Monitoring
Transaction logging is available to enable closer monitoring of changes being made to replicated data and data accessed directly through CData Sync.
-
On-Premise Or In The Cloud
CData Sync is a go-anywhere application that is designed to perform equally well hosted on-premise (Windows, Unix / Linux, Mac OS) or in the Cloud (Azure, Amazon, Google).
Frequently Asked Cassandra Data Integration Questions
Learn more about using CData Sync to replicate Cassandra
What is Cassandra Data Integration?
Cassandra data integration is the seamless connection and synchronization of data between Cassandra and other organizational systems. ETL & ELT (Extract, Transform, Load / Load, Transform) processes play a crucial role in integrating Cassandra data with other systems within an organization's data infrastructure. Data is extracted from Cassandra, transformed as needed, and loaded into another destination, typically for storage, analysis, or reporting purposes. CData Sync plays a critical role in Cassandra data integration, making it easy to replicate Cassandra data any database or data warehouse and maintain parity between systems
How do I move Cassandra data to SQL Server?
Unlike replicating Cassandra to a cloud data warehouse or data lake where data is commonly moved first and transformed at the destination via an ELT process, relational databases like SQL Server require ETL and in-flight data transformation. There are many ways to build ETL processes that integrate Cassandra data with SQL Server. We recommend CData Sync, an easy-to-use data pipeline tool that helps users automatically and continuously replicate Cassandra data to any database or data warehouse, including SQL Server.
Can I export Cassandra to S3?
Amazon Simple Storage Service (Amazon S3) is an object storage service providing scalability, data availability, security, and high performance. CData Sync offers the ability to create jobs that will transfer Cassandra data to Amazon S3 to support backup, enable cost efficiencies, enforce security, and meet compliance requirements. CData Sync will convert Cassandra data automatically into popular flat-file formats like CSV, parquet, and Avro and push those files to Amazon S3 as objects.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers