Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



Data Warehousing with Amazon Redshift and CData Sync

When your business grows, so does the size and complexity of the data used to run the business and drive continued that growth.
As businesses move from consolidated storage to a distributed SaaS, big data, and NoSQL portfolio, they often embrace some form of data warehousing to support their analytics and governance initiatives. Cloud data warehousing technologies like Amazon Redshift have made it easy for organizations to set up and maintain a data warehouse with virtually unlimited capacity.
However, selecting a data warehousing provider is only the first step. To make use of your warehouse, users need to find a way to automate and continuously aggregate business data.
CData Sync is designed to solve this type of data consolidation challenge. Our Sync replication tool automates the ingestion of all of your critical organization data into any backend database or data warehouse, including Amazon Redshift. With a straightforward point-and-click interface and support for more than 100 SaaS, Big Data, and NoSQL data sources, CData Sync allows you to rapidly configure and customize your data pipeline.
This article walks through setting up and configuring Amazon Redshift as a destination for CData Sync.
Configuring Amazon Redshift
Amazon Redshift is fast and can handle data at the petabyte scale, enabling low-hassle, cost-effective data access for your data analysts and developers. With a traditional database structure, you can easily source and organize data from dozens of disparate locations.
To replicate enterprise data to Amazon Redshift using CData Sync, you will need an Amazon Redshift cluster and an existing database in the cluster. From there, CData Sync manages the rest of the data replication, from creating new tables to updating existing tables with new data entries.
Create an IAM Role
If you do not already have an AWS Identity and Access Management (IAM) role for accessing Redshift instances, you will need to create one:
- Log into the AWS Management Console for IAM, type "IAM" into the Find Services bar and click "IAM"
- Click the Roles tab and click "Create role"
- In the AWS Service group, choose Redshift, select "Redshift - Customizable," and click "Next:Permissions"
- Attach the "AmazonS3ReadOnlyAccess" policy and click "Next:Tags" and optionally add tags
- Click "Next:Review," add a name for your role (like myRedshiftRole), review the information and click "Create role"
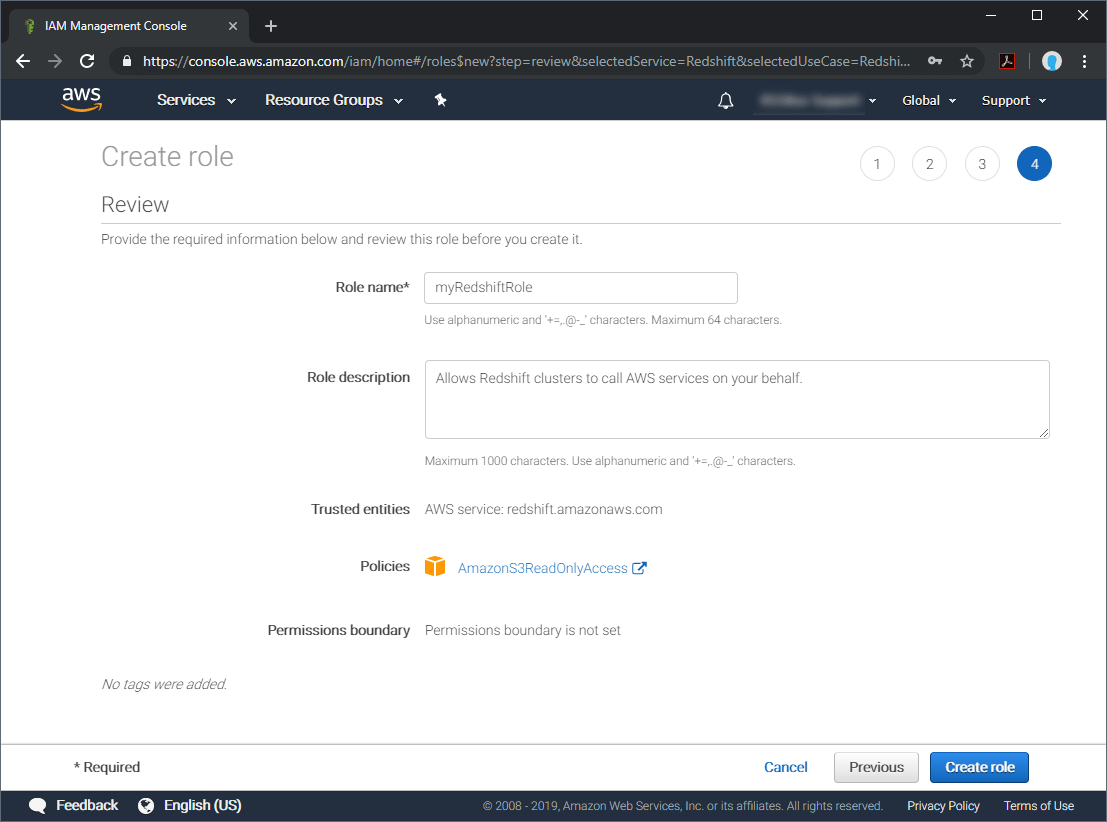
- Choose the role name of the role you just created and copy the "Role ARN" to the clipboard
Launch an Amazon Redshift Cluster
With the IAM role created, you are ready to launch a new Amazon Redshift cluster:
- Log into the AWS Management Console for Redshift
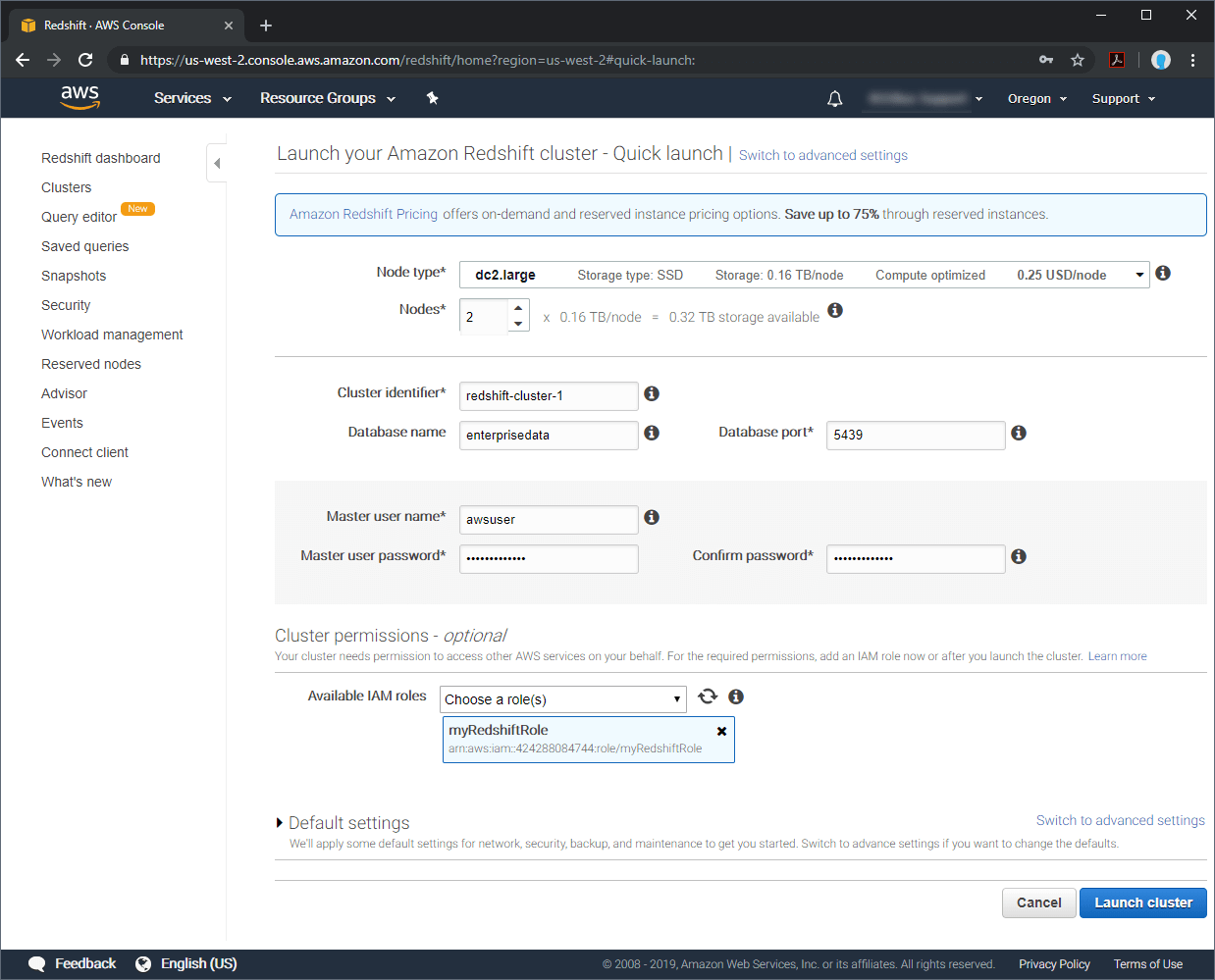
- Select the region for your new Amazon Redshift cluster
- Click "Quick launch cluster" and configure the cluster, including "Database name," "Master user name" and "Available IAM roles"
Authorize Access to the Cluster
Once the Amazon Redshift cluster is live, configure a security group to authorize access:
- In the Amazon Redshift console, choose "Clusters"
- Open your new cluster and navigate to the "Configuration" tab
- Choose your security group and navigate to the "Inbound" tab
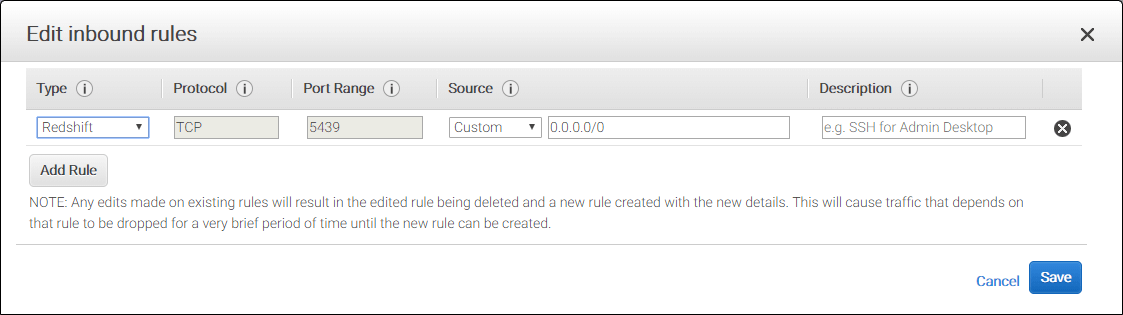
- Choose "Edit," "Add Rule" and enter the following
- Type: Redshift (or Custom TCP Rule if you use a non-default port)
- Protocol: TCP (default for the Redshift rule type)
- Port Range: 5439 (default for the Redshift rule type)
- Source: Select Custom, then type the IP address and port of the client machine (use 0.0.0.0/0 to allow access from anywhere)
Connect to Amazon Redshift from CData Sync
CData Sync connects directly to an Amazon Redshift database as a replication destination. Coupled with the 100+ data sources CData Sync supports, you can rapidly configure Redshift as a single data warehouse for all of your enterprise data, from marketing automation and CRM to ERP, accounting, social media, collaboration platforms and more.
To connect to Amazon Redshift, open CData Sync, navigate to the Connections page, click the Destinations tab, and select Amazon Redshift.

Name your connection and set the Server, Database, User, and Password properties. Click Test Connection to ensure you can connect and click "Save Changes" to save your connection.

Replicating Data to Amazon Redshift
With your Amazon Redshift cluster configured and CData Sync connected, you are ready to generate replication jobs to pull data into Amazon Redshift. For each data source you wish to replicate, configure a source connection. While several data sources are embedded in CData Sync out of the box, you can easily download new Data Source Connections (click the link in the CData Sync app or navigate directly to the Data Source Connections download page).
Create and schedule replication jobs on the Job tab. You can see job creation in our CData Sync 2019 Overview (video jumps to job creation):
Beyond Amazon Redshift
Once you replicate your data, you can get the most from your enterprise data: performing analytics in BI tools (like Tableau), gaining and sharing insights from visualizations built in Amazon QuickSight, and building predictions using Amazon ML.
Key CData Sync Features
CData Sync dramatically simplifies the process of aggregating enterprise data - from any data source to any destination. Features include:
- Support for more than 100 data sources, including every major database and data warehouse destination
- Easy configuration: tables are created in the replication destination, as needed, for each table (entity) in the original data source
- Incremental data replication: only entries added or updated since the last replication are included in the replication job
- Fully customizable replication and data transformation: select specific columns (fields), filter data, create aggregations, and more!
Ready to get started? Download a free, 30-day trial of CData Sync, today.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers