Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



Data Warehousing with Google BigQuery and CData Sync

The popularity of data warehousing continues to surge as tools for business intelligence (BI), artificial intelligence (AI), and machine learning (ML) are helping organizations realize new business value from their enterprise data. Advances in data warehousing, and subsequent tooling, is enabling businesses to operate on data on a massive scale.
The benefits are obvious, but aggregating all of your organizational data into a common repository can be a challenge. Your organization is likely using a variety of applications, platforms, and services for everything from payroll and accounting to marketing automation and CRM - each with their own unique APIs or interfaces. What's more, data dumps are impractical as ingestion needs to happen in an automated and continuous way.
CData Sync is designed to solve these types of data consolidation challenges. Our Sync data replication tool can be configured to automate the data ingestion of all of your critical organization data into any back-end database or data warehouse. With a straightforward point-and-click interface and support for more than 100 SaaS, Big Data, and NoSQL data sources, CData Sync allows you to rapidly configure and customize your data pipeline.
The rest of this article walks through setting up and configuring Google BigQuery, a popular data warehouse, as a destination for CData Sync. The same basic configuration can also be used for any supported data destination.
Configuring Google BigQuery
Google BigQuery is serverless and highly scalable, meaning your data analysts and developers can work with data in a BigQuery warehouse quickly, easily, and without breaking your budget. The scoping of data tables and views into projects and datasets lets you structure your business data logically, even if it is sourced from dozens of locations. Configuring a different dataset for each source of data (e.g. Salesforce, QuickBooks, Facebook, etc.) allows you to maintain the separation of different analytical domains while still enabling cross-source analytics. For more information on using BigQuery as a data warehouse, refer to the Google article on BigQuery for Data Warehouse Practitioners.
To replicate enterprise data to Google BigQuery using CData Sync, you will need a project in the Google Cloud Platform and a dataset in your project. With both of those in place, CData Sync manages the rest of the replication, from creating new tables to updating existing tables with new data entries.
Create a Google Cloud Platform Project
If you do not already have a project or you want to create a new one, log into the Google Cloud Platform, click the down arrow to the right of "Google Cloud Platform," and click "New Project."

In the New Project wizard, name your project, select a location, and click "Create."

Create a Google BigQuery Dataset
With the Project created or selected, you can create a new dataset to house your enterprise data. Select BigQuery from the Menu (or navigate directly to the BigQuery Console).
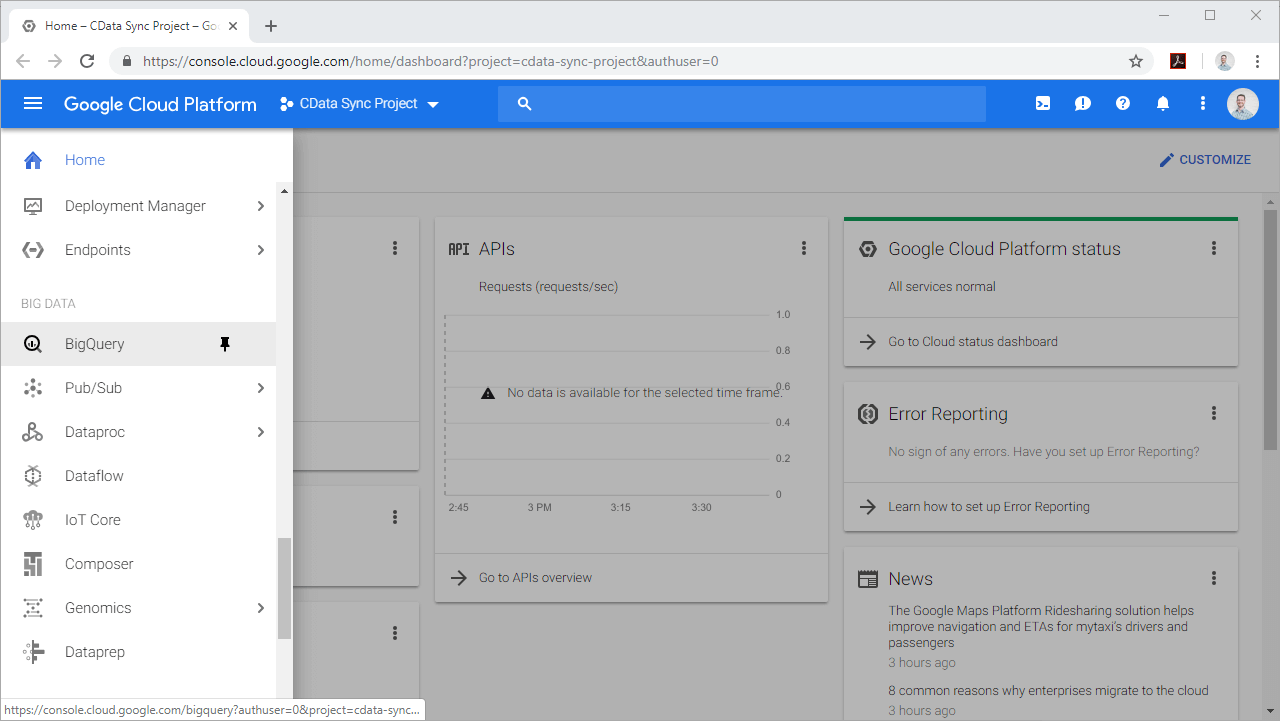
Click "Create Dataset," configure the Dataset ID, Data location, and Default table expiration. Click the button to create the new dataset.

With the project and dataset configured, you are ready to connect to Google BigQuery as a replication warehouse from CData Sync.
Connect to Google BigQuery from CData Sync
CData Sync connects directly to a Google BigQuery dataset as a data replication destination. Coupled with the 100+ supported data sources CData Sync supports, you can rapidly configure BigQuery as your single data warehouse for all of your enterprise data, from marketing automation and CRM to ERP, accounting, social media, collaboration platforms and more.
To connect to Google BigQuery, navigate to the Connections page, click the Destinations tab, and select Google BigQuery.

Name your connection and set the dataset and project IDs. When you click Connect, you will authenticate with Google to grant permission for CData Sync to connect to Google BigQuery. Click "Save Changes" to save your connection.

Replicating Data to Google BigQuery
With Google BigQuery configured and CData Sync connected, you are ready to generate replication jobs to pull data into Google BigQuery. For each data source you wish to replicate, configure a source connection. While several data sources are embedded in CData Sync out of the box, you can easily download new Data Source Connections (click the link in the CData Sync app or navigate directly to the Data Source Connections download page).
Create and schedule replication jobs on the Job tab. You can see job creation in our CData Sync 2019 Overview (video jumps to job creation):
Beyond Google BigQuery
Once you replicate your data, you can get the most from your enterprise data: performing analytics in BI tools (like Tableau), gaining and sharing insights from visualizations built in Looker Studio (formerly Google Data Studio), and building predictions using BigQuery ML.
Key CData Sync Features
CData Sync dramatically simplifies the process of aggregating enterprise data - from any data source to any destination. Features include:
- Support for more than 100 data sources, including every major database and data warehouse destination.
- Easy configuration: tables are created in the replication destination, as needed, for each table (entity) in the original data source.
- Incremental data replication: only entries added or updated since the last replication are included in the replication job.
- Fully customizable replication and data transformation: select specific columns (fields), filter data, create aggregations, and more!
Ready to get started? Download a free, 30-day trial of CData Sync, today.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers