
Businesses today, especially in heavily regulated industries such as financial services or healthcare, are actively working to balance modernization and data security. While many organizations keep sensitive data in-house for security reasons, the need to modernize with cloud platforms has made integration a critical priority.
Trusted cloud platforms like Databricks offer unmatched performance, scalability, and analytics capabilities that legacy systems can't compete with. Organizations must find a way to install some form of a hybrid architecture to modernize their data stack with platforms like Databricks, so they get the most out of their data.
In this blog, we review the challenges users can experience with hybrid integrations and explore how it bridges the gap between on-premises systems and Databricks all while not relying on costly local agents.
On-premises integration challenges
We know that a hybrid integration architecture is needed to get the best of both worlds; cloud scalability and performance with the data security of an on-premises system. However, this introduces a new set of challenges that are unique to hybrid integrations. From legacy system complexity to strict security requirements, businesses must overcome these challenges to have a seamless hybrid integration:
Legacy system complexity
Organizations today continue to rely on self-hosted legacy systems such as SAP ERP, Microsoft Dynamics, or IBM DB2. These older systems typically come with proprietary data models and architectures, highly customized deployments, and limited connectivity options. The process of integrating these systems with cloud tools like Databricks can require custom code and involve legacy connectors or middleware.
Network and infrastructure constraints
Many cloud integration tools will require installing on-premises agents to extract and transmit data from your local systems. This traditional approach often adds additional operational burdens such as increased infrastructure cost, firewall complexity, and performance bottlenecks. These limitations make it difficult for a business to support real-time or near-real-time integrations that can remain scalable and agile.
Performance and change data capture (CDC) requirements
Modern analytics and data engineering pipelines demand low-latency data access, especially when leveraging a powerful cloud platform such as Databricks. When working with on-premises and legacy systems, you can run into issues like full data extracts straining production systems, batch ETL jobs causing data staleness, or no support for CDC. These factors can limit how effectively an organization can implement its cloud analytics initiatives.
Compatibility with enterprise tools
While Databricks may be the main tool used for an organization's modern analytics plan, many organizations still rely on existing enterprise tools that are on-site, such as SQL Server Reporting Services (SSRS) for operational reporting or SQL Server Analysis Services (SSAS) for multidimensional models. These tools can require direct access to local relational data models and often are not natively compatible with cloud-based systems like Databricks.
Security and compliance concerns
Sensitive and regulated data, especially in industries such as financial services, government, and healthcare, must adhere to strict data governance rules to ensure proper data security. These industries are typically governed by regulations like the Health Insurance Portability and Accountability Act (HIPAA) or the General Data Protection Regulation (GDPR), so integrating with cloud platforms like Databricks can be challenging as these regulations not only apply to the cloud platform but also the integration solution used to connect to the on-premises systems.
Learn how CData helps integrate Databricks data into Microsoft SSAS cubes
Bridging on-premises systems and Databricks with CData
The CData Databricks Integration Accelerator is tailor-made to solve the challenges that come with connecting the scalable power of the cloud with business data that remains securely self-hosted. It enables high-performing and secure integration between on-premises systems and Databricks, all with a no-code, enterprise-grade approach to live data integration.
Key features
Agentless architecture
Unlike traditional hybrid integration tools that can require deploying local agents or setting up complex VPNs, CData's solution is fully agentless. This eliminates the need for installing any on-premises agents or software behind your firewall and on your system. This means your IT teams can retain full control over your data movement and avoid the need for additional infrastructure.
Enterprise-grade security
CData's connectors are built with enterprise-grade security at the core, empowering organizations to fully leverage Databricks while meeting the strictest compliance standards. CData is SOC 2 Type II certified, which ensures that organizations can deploy CData solutions with the confidence that the product meets industry-standard criteria.
Built for enterprise-grade integration
The Databricks Integration Accelerator supports the most complex and heavily customized systems that organizations need to integrate with. Whether you are connecting to a legacy enterprise resource planning (ERP) platform, like SAP ECC or Microsoft Dynamics, or a legacy relational database management system (RDBMS) like Oracle or IBM DB2, CData's connectors can dynamically handle varying schemas, support custom objects and tables, and handle non-relational or nested data structures. This makes CData ideal for enterprise environments with rigid legacy systems.
ETL without consumption pricing
Gone are the days of unpredictable and high variability pricing with hidden fees and scaling penalties. Whether replicating 10 GB or 10 TB, CData offers predictable connector-based pricing that helps organizations manage the cost of data replication and optimize spend when compared to other approaches. This pricing model is critical for IT teams and business leaders, as it provides cost transparency and gives financial control back to the organization.
Example use cases
|
Source System
|
Goal
|
Key Benefit
|
Link
|
|
SAP ERP
|
Move SAP ERP data to your Databricks lakehouse.
|
Near-real-time replication without the need for an on-premises agent.
|
Full use case
|
|
IBM DB2
|
Power predictive analytics in Databricks with legacy DB2 data.
|
Secure access to your legacy system.
|
Full use case
|
|
SQL Server
|
Merge local and cloud data for your analytics in Databricks.
|
CDC support for real-time reporting.
|
Full use case
|
Learn how NJM Insurance accelerated their integration build time here: NJM Insurance Case Study
Implementation guide
Getting started with the Databricks Integration Accelerator is fast, secure, and doesn’t require any coding. Below is an overview of how is typically implemented to enable seamless on-premises to cloud data replication.
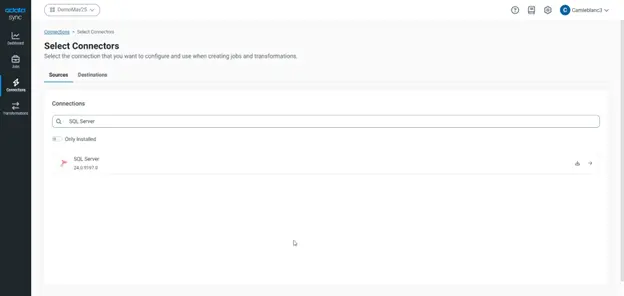
- Connect to your local source
Choose the data source that you want to integrate with Databricks. In CData Sync, navigate to the Connections tab and then:
-
- Click Add Connection.
- Select a source (SQL Server is shown below).
- Configure the connection properties.
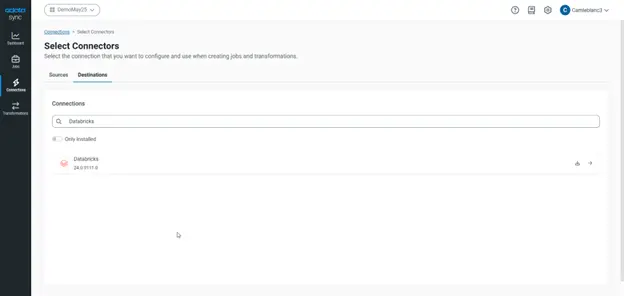
- Connect to your Databricks destination
After connecting to your source, you can create a destination connection for Databricks. To add a replication destination, navigate to the Connections tab and then:
-
- Click Add Connection.
- Select Databricks as a destination (Shown below).
- Configure the connection properties.
- Create a replication Job
With both the Source and Destination connections configured, you can now create a job in CData Sync to replicate your data to Databricks. To create a new job, navigate to the Jobs tab and then:
-
- Click Add Job -> Add New Job
- Name the job and select your Source and Destination
- After creating the job, go to the Task tab to add the tables you want to replicate.

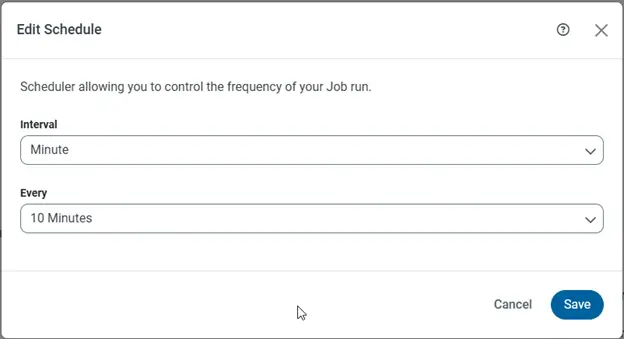
- Schedule, verify, and monitor your jobs
Now that you have created the replication job to move your on-premises data to Databricks, you can schedule the job to run automatically, verify your job runs successfully, and monitor your job's progress.
-
- Schedule your replication to run automatically, configuring the job to run after specified intervals ranging from once every minute to once every month.
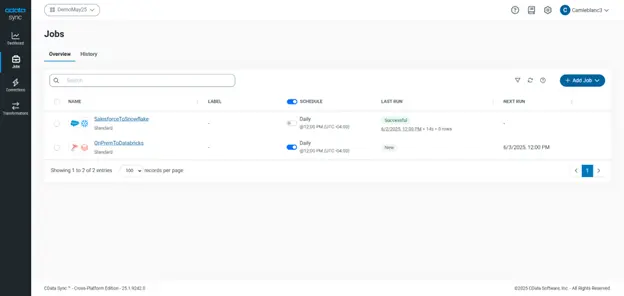
- Verify and monitor your jobs with CData Sync's built-in job monitoring dashboard.
Get started with the CData Databricks Integration Accelerator
The CData Databricks Integration Accelerator makes it simple to integrate Databricks with your on-premises data sources. Get started today with a free, 30-day trial of CData Sync to start optimizing your organization's data for analysis and see how beneficial a hybrid deployment can be for your organization.
Explore CData Sync
Get a free product tour to learn how you can migrate data from any source to your favorite tools in just minutes.




