




Embedded Data Virtualization
A logical data layer for any data, anywhere
Remove data bottlenecks with a consolidated connectivity layer that unifies data access across data sources.
The growing problem of data fragmentation
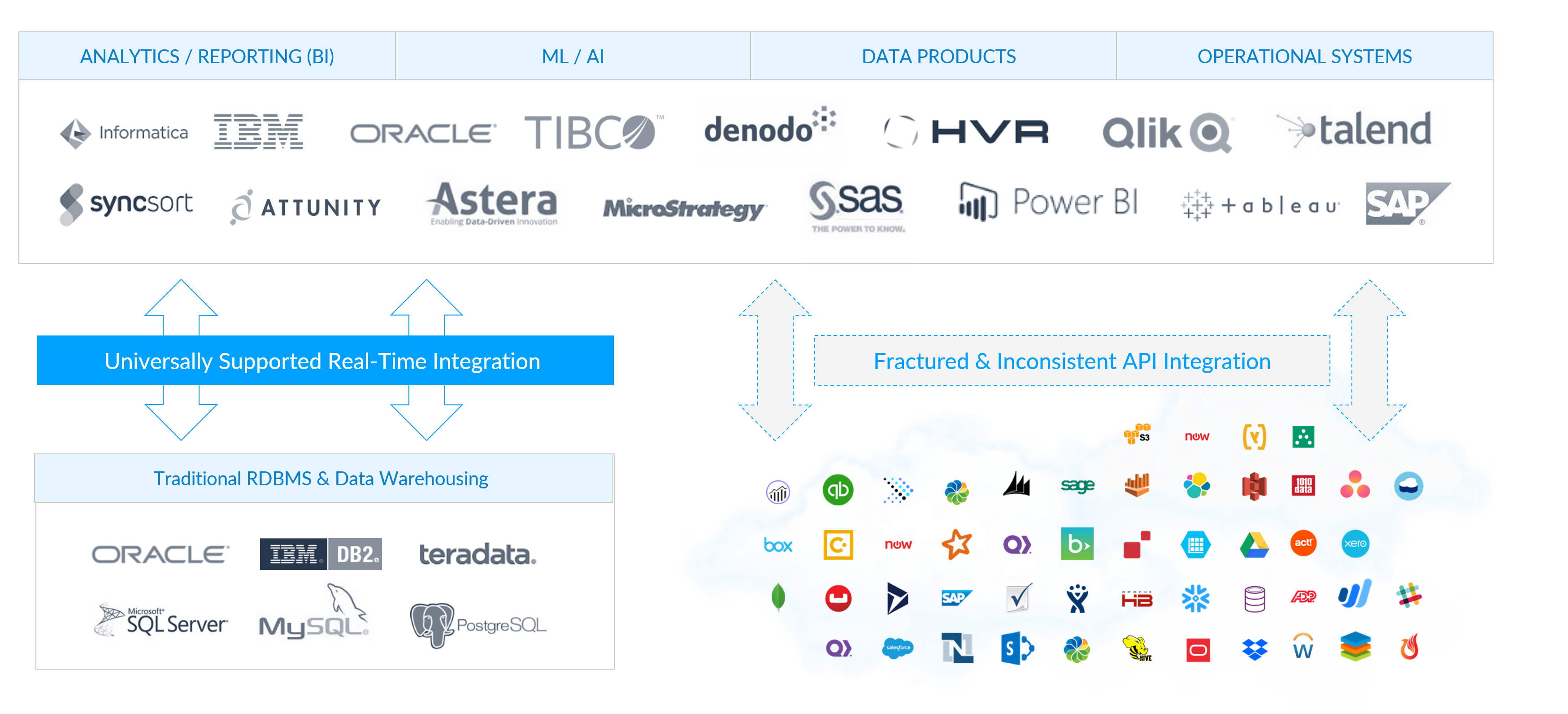
Historically, BI and data integration tools only had a handful of data sources to integrate and connect with. SaaS and cloud technologies have created a very different looking market landscape. Data is locked in multiple clouds, apps, databases and legacy platforms, creating data silos.
Moving data around in these environments is a slow process, posing a challenge for business analytics. Data can sometimes change by the time it is replicated and integrated which leads to inaccurate analysis.
Data virtualization approaches
Drawing value from massive amounts of siloed data is an arduous task, but data virtualization solves that problem. Data virtualization is the ability to orchestrate data in real-time or near real-time from disparate data sources, whether on-premises or cloud, into coherent self-service data services to support various business use cases and workloads.
The most common approach is to deploy a stand-alone server that acts like a logical data warehouse layer for data connectivity. Embedded Data Virtualization shares many of the same characteristics of stand-alone DV, but instead of one external platform, systems are augmented with a common unified data access layer.

Stand alone data virtualization solutions are a common approach to logical data warehousing. However, many of these systems are large, costly and difficult to maintain. Furthermore, a project of this scale typically needs to be endorsed by the entire IT organization.
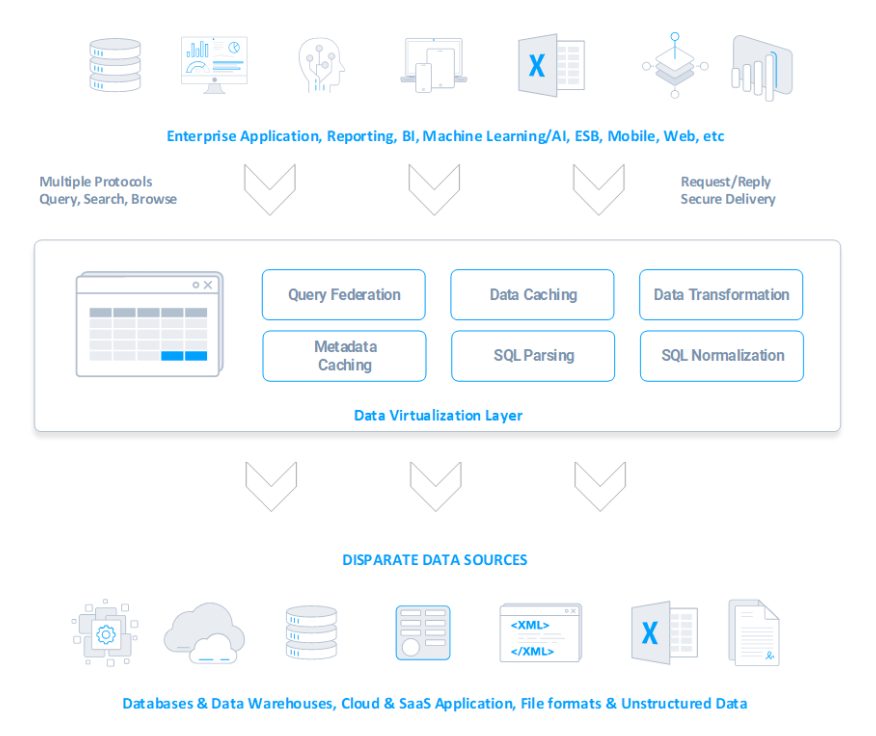
Unlike stand-alone Data Virtualization solutions, Embedded DV can be deployed as a tactical component of other applications. Analytics or integration solutions can leverage Embedded DV as an interface for extensibility and can pick and choose the features that matter most for their applications.
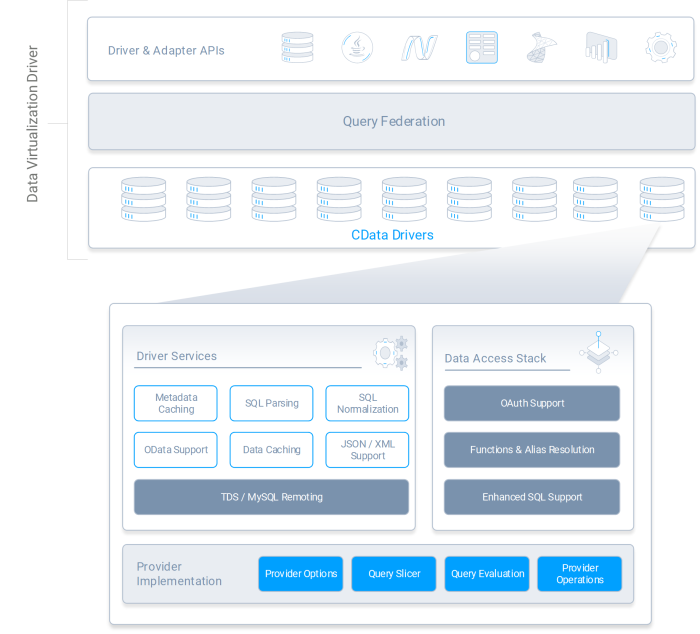
The CData Drivers provide components of Embedded DV, offering a common SQL interface on top of disparate data. For joining data across sources, users can leverage CData Connect AI.
Benefits of embedded data virtualization:
- Simplified Application Development - Developers can pick multiple data processing systems and access all of them with a single SQL-based interface.
- Query Across Multiple Systems - With query federation, you can write queries that combine data from different sources directly, on-demand.
- Up to 85% Faster - Faster and easier data connectivity vs. traditional data warehousing and ETL.

Embedded DV in action
Watch the Query Federation Driver overview video for a first-hand look at how applications can simplify and consolidate data connectivity through a common interface.

Connectivity for data virtualization
Pair CData Driver technologies with common tooling to enhance virtualized data connectivity.
In addition to being embedded in leading data integration and virtualization solutions, CData Driver technologies can be easily paired with common tooling. With universal support for ODBC, JDBC, ADO, and Python, our drivers work with Federated Queries, SQL Server Linked Servers, Polybase, and other popular DV technologies.
Virtualizing data access with CData
Data virtualization resources
Learn more about the architectural benefits of using embedded data virtualization to simplify integration and speed solution delivery.
Drivers & data virtualization
Want to learn more about how CData Drivers and Adapters enhance data connectivity through data virtualization technologies? Contact us below, and let's talk.