 As enterprises scale analytics and AI initiatives, data readiness – not platform capabilities – has become the primary constraint. Microsoft Fabric provides a powerful, unified platform for analytical persistence, modeling, and AI consumption, but it assumes that data is already accessible and appropriate to land for analytical use.
As enterprises scale analytics and AI initiatives, data readiness – not platform capabilities – has become the primary constraint. Microsoft Fabric provides a powerful, unified platform for analytical persistence, modeling, and AI consumption, but it assumes that data is already accessible and appropriate to land for analytical use.
In practice, much enterprise data remains operational, dynamic, and unnecessary (or even impractical) to persist continuously. Treating all data as analytical by default increases cost, complexity, and latency, and slows AI initiatives that depend on timely operational context. CData Connect AI resolves this at the data layer enforcing governed, live access to operational data through Model Context Protocol (MCP) and CData’s connectivity capabilities without requiring persistence first.
Together, Fabric and Connect AI enable a balanced, purpose-driven architecture: Fabric is applied where analytical persistence creates value, while Connect AI supports real-time, contextual access to operational data. This separation reduces unnecessary data movement, preserves source-system integrity, and lets AI operate on current data, not yesterday's sync.
The enterprise data problem in the Fabric era
Enterprises are investing heavily in modern data platforms to unify analytics, enable AI, and reduce architectural sprawl. Microsoft Fabric represents a significant step forward by consolidating analytics, data engineering, and AI workloads into a single, coherent ecosystem. Yet despite this progress, many organizations continue to struggle with a familiar set of data challenges, now amplified by the urgency of AI initiatives.
At the core of the problem is a growing mismatch between how data is produced and how it is consumed. Operational systems generate data continuously, with varying schemas, latencies, and governance requirements. Analytical platforms, by contrast, assume data is already accessible, stable, and suitable for downstream modeling and AI consumption. Bridging this gap has traditionally required extensive data movement, replication, and custom pipelines, often resulting in brittle architectures that are expensive to maintain and slow to adapt.
The result is a familiar pattern:
Operational systems are overused for analytical access
Data pipelines proliferate and become fragile
Governance is applied after ingestion, not at the source
AI initiatives stall due to data readiness, not model capability
These challenges highlight a structural gap between operational data access and analytical data consumption – one that becomes increasingly critical in an AI-driven world.
Fabric’s role in the modern data estate
By bringing together data engineering, data integration, analytics, and AI experiences into a single platform, Fabric simplifies the data estate and reduces fragmentation that has historically slowed insight and innovation. Within this unified foundation, Fabric excels at analytical persistence and consumption. Through Microsoft OneLake, organizations gain a centralized data layer that supports reporting, semantic modeling, and AI-driven experiences such as Microsoft Copilot. Fabric’s tight integration across services enables teams to move efficiently from raw data to insight while maintaining consistency in governance, security, and access controls.
Fabric also plays a critical role in standardizing how data is prepared for downstream use. Its tooling is well-suited for transforming, modeling, and enriching data once it has been ingested, making it easier to support enterprise-wide analytics and AI initiatives at scale. For many organizations, Fabric becomes the system of record for analytical data.
However, this also implies a set of architectural assumptions. Fabric's strength is operating on data that is already available, sufficiently stable, and appropriate to persist for analytical use. In practice, not all data meets these criteria. Operational systems often contain high-volume, rapidly changing, or transient data that is expensive (or even unnecessary) to replicate continuously. Other data must be current, where pipeline latency becomes a limiting factor.
As a result, organizations are frequently faced with architectural trade-offs:
Should data be landed in OneLake or accessed on demand?
How much data movement is justified for a given use case?
When does persistence add value versus when it simply adds cost and complexity?
Fabric provides powerful answers for analytical workloads, but it does not attempt to solve every aspect of operational data access. Instead, it assumes operational data is exposed through governed and contextual mechanisms, allowing Fabric to focus on what it does best: analytical workloads.
Connect AI’s complementary role
As organizations standardize on Fabric for analytics and AI consumption, a parallel need emerges: a reliable way to access operational data that is not yet ready (or even intended) for analytical persistence. This is where Connect AI plays a complementary role within the broader Fabric ecosystem.
Connect AI serves as an operational intelligence layer, providing real-time access to data directly from source systems and enforcing governance at the access layer, not after ingestion. Rather than assuming all data must be moved, replicated, or transformed before it can be used, Connect AI enables organizations to expose operational data responsibly, preserving source-system integrity while making that data available for downstream consumption. By providing live access through MCP and CData’s underlying connectivity layer, Connect AI supports low-latency and operationally contextual use cases without first landing data into OneLake.
This does not replace or manage analytical persistence within Fabric. Instead, it removes the requirement to persist all data by default, allowing teams to make intentional decisions about what data should be landed for analytical use and what data is better accessed live. Fabric handles analytical workloads. Connect AI handles operational access. Neither overreaches into the other's domain.
Connect AI enforces access controls at the source, before data is ingested into any analytical platform. Governance is applied at query time, not after the fact. In practice, governance responsibilities are distributed: source systems enforce their own security models, Connect AI provides workspace isolation and role-based access controls, and downstream platforms such as Fabric apply analytical governance. In AI-driven scenarios where overly broad access can introduce risk, inconsistency, and unintended cost, a layered approach helps ensure that operational data is accessed intentionally and contextually, which is especially important. This is illustrated below.
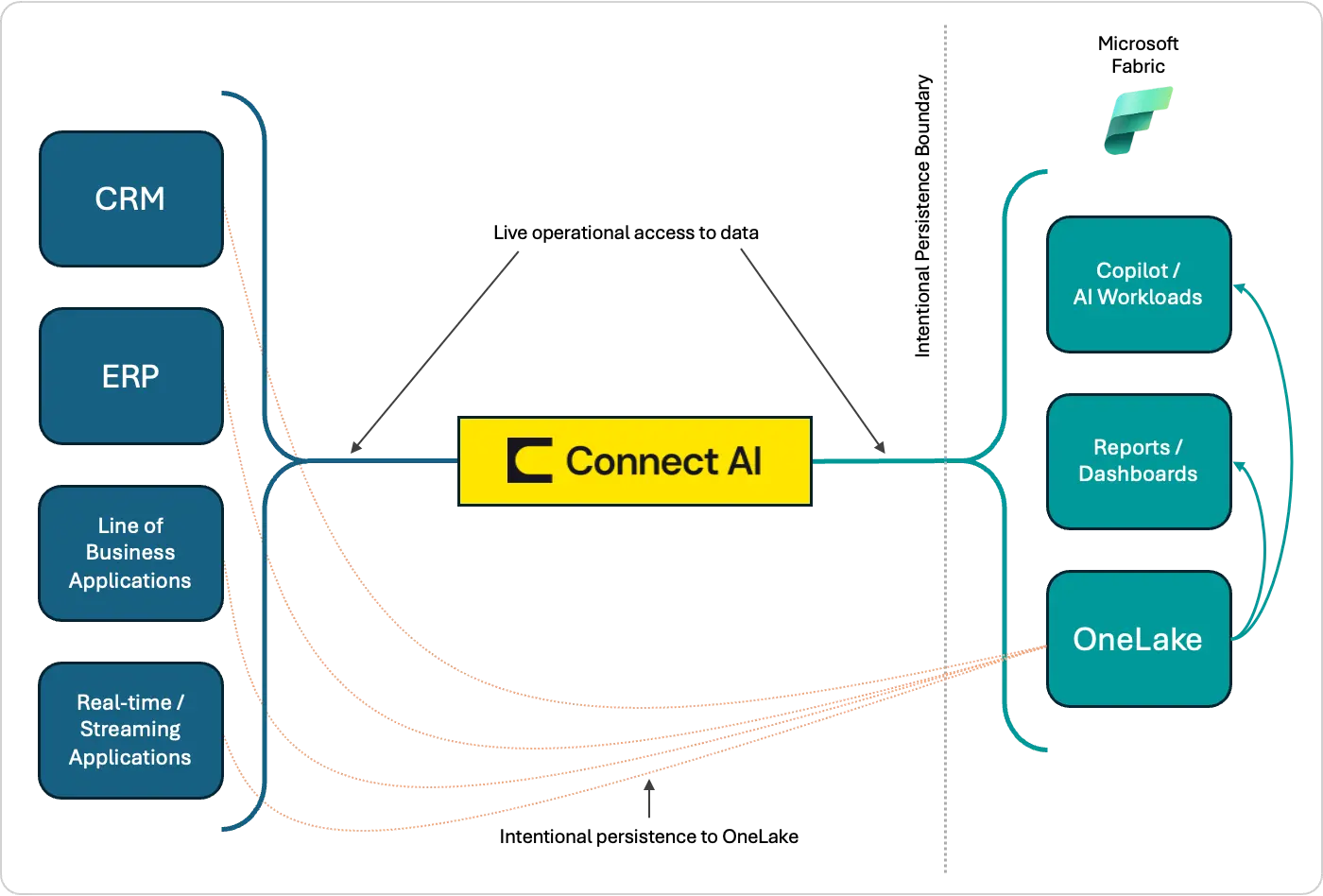
AI-readiness through operational intelligence
AI agents and copilots are increasingly expected to perform investigative and decision-support tasks: retrieving current records, checking in-flight transactions, and reasoning across operational state. To do so effectively, they require access not just to historical summaries but to operationally current, detailed data.
Connect AI addresses this need by enabling AI systems to interact with data closer to its source through data access capabilities provided by Connect AI, while still respecting governance and access boundaries. This allows AI-driven experiences to retrieve relevant data on demand, with appropriate controls and latency guarantees.
This distinction becomes especially important in the Fabric ecosystem because many AI scenarios require both persisted analytical data for trend analysis and modeling, and live operational signals for real-time context. (See the diagram below.) Without this balance, organizations risk either over-replicating data or depriving AI systems of timely context.
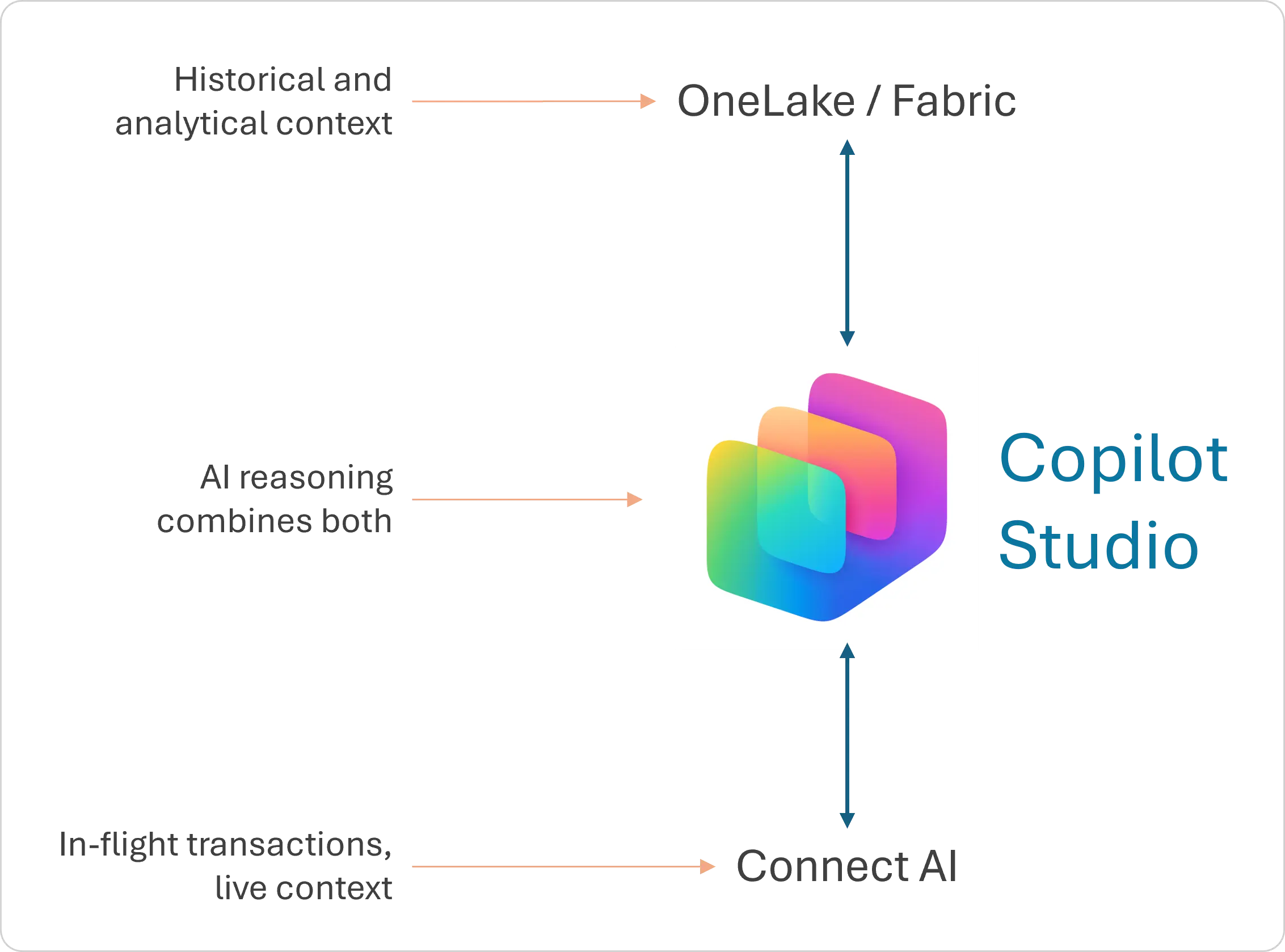
Operational intelligence also improves trust and reuse. By standardizing how operational data is accessed and governed, organizations reduce ambiguity around data meaning, ownership, and freshness. AI systems built on this foundation are more explainable, more auditable, and easier to extend across use cases.
Architecture patterns and decision guidance
Rather than defaulting to full data replication, teams can choose patterns based on latency, cost, governance, and business intent. One common decision point is whether to query data live from source systems or to introduce an operational data store (ODS) as an intermediary layer.
Live access is well-suited for scenarios where data freshness is critical, volumes are manageable, and operational semantics must be preserved. In these cases, querying data on demand avoids unnecessary data movement while ensuring AI and analytical workloads reflect the current state of the business.
An ODS becomes appropriate when operational data must be stabilized, enriched, or shared across multiple downstream consumers. By persisting a curated subset of operational data, organizations can reduce load on source systems, improve query performance, and introduce consistency without immediately persisting all operational data into OneLake. This pattern is especially effective when multiple AI or reporting use cases depend on the same operational signals.
Hybrid patterns are becoming more common: selected operational data is persisted into an ODS or landed into OneLake for analytical purposes, while higher-velocity or more contextual data is queried live, are becoming more common. This allows teams to balance performance and freshness, using persistence where it adds value and live access where it preserves agility.
Across all patterns, several guiding principles emerge:
Persist data when it delivers analytical or operational leverage
Query live data when freshness and context outweigh aggregation needs
Introduce an ODS to decouple source systems from downstream demand
Treat governance as a first-class concern, regardless of pattern
By applying these principles, organizations can align their data architectures with both Fabric’s analytical strengths and the operational realities of enterprise systems, avoiding one-size-fits-all approaches in favor of intent-driven design.
Example scenarios
The following scenarios illustrate how organizations combine operational intelligence with Fabric by separating operational data access from analytical persistence.
Near real-time operational insight
A customer service organization deploys AI copilots that require current order and case status during live interactions.
Connect AI provides access to operational data directly from CRM and order management systems using MCP and underlying connectivity.
Fabric consumes this data selectively for reporting and historical analysis, without being used as the primary access path for real-time interactions.
Selective persistence for analytical enrichment
A retail organization analyzes sales trends and inventory performance across regions.
Connect AI provides access to detailed transactional data when freshness or drill-through is required.
Fabric persists aggregated and curated datasets into OneLake for trend analysis, forecasting, and semantic modeling.
This reduces storage needs and pipeline complexity.
Incremental modernization
A manufacturing firm introduces Fabric for analytics while retaining existing operational systems.
Connect AI provides access to operational data for AI-driven monitoring and decision support.
Fabric is introduced incrementally to persist selected datasets for analytics and reporting as requirements mature.
AI initiatives can proceed without waiting for full data migration or replatforming.
Key takeaways
Modern data platforms have dramatically improved how organizations analyze and consume data, but AI-ready architectures require more than analytical consolidation alone. Success depends on how effectively operational data is accessed, governed, and aligned with analytical systems.
CData’s Connect AI provides this operational intelligence layer. By resolving queries at the source, enforcing governance at query time through MCP, Connect AI removes the requirement to persist all data before it can be used. This allows organizations to apply persistence intentionally, using Fabric where analytical value is created and live access where operational context matters.
The most effective data architectures are defined by intentional design choices. When Connect AI and Fabric operate in their respective domains – operation access and analytical persistence – the result is a data layer that scale without accumulating unnecessary complexity.
Explore CData Connect AI today
See how Connect AI excels at streamlining AI and business processes for real-time insights.




