Today's organizations rely on data, and database efficiency is crucial to maintaining an efficient data ecosystem. In this article, you'll learn about the core concepts of replicating organizational data to SQL Server, and gain insights into the optimal configuration steps. Discover how this process can elevate your data synchronization game and contribute to streamlined database management.
What Is SQL Server replication?
SQL Server replication is the process of copying and distributing data and database objects from one database to another and synchronizing the data between them to maintain the integrity and consistency of the data. It's a central feature in Microsoft SQL Server that enables you to create and maintain multiple copies of a database for various purposes, such as scalability, high availability, and reporting.
Microsoft SSMS (SQL Server Management Studio) is a convenient tool for replicating SQL Server databases, though it has limitations. If you're looking for database replication beyond SQL Server, CData Sync provides you with the tools you need to easily implement automated, continuous, customizable database replications.
In this post, we explore SQL Server replication including the key components, the 4 types, and the logical steps.
The key components of a SQL Server replication process
The replication process is simple and direct. There are three main roles in MS SQL database replication: Distributor, Publisher, and Subscriber. A Distributor is an MS SQL database instance configured for collecting transactions from publications and distributing them to subscribers. A Distributor acts as the database for storing replicated transactions. A Subscriber is a server that receives replicated data.
Each of these roles have additional components, typically involving associated databases, that you need to know about. The components involved in SQL Server replication include:
- Articles: The basic units of SQL Server. Articles are made up of views, tables, and stored procedures. You can use the filter option to scale the article either vertically or horizontally, and you can create multiple articles on one object with customized limitations.
- Publication: A logical collection of articles and the associated information needed to replicate them. Publication allows us to define and configure article properties at the higher level so all the articles in that group are inherited.
- Publisher DB: A database instance that makes data available to other locations through SQL Server replication. The Publisher can contain multiple publications, each defining a logically related set of objects and data to replicate.
- Distribution DB: An optional server that acts as an intermediary between the publisher and subscribers. It stores the article details, data, and replication meta-data and manages the distribution process.
- Subscriber: The server that receives the replicated data. It acquires the SQL Server Replication data from a publication. The Subscriber can receive data from one or more publications and Publishers.
- Subscription: A request for a copy of a publication on a specific subscriber.
- Subscription DB: The target database of a replication model.
- Agents: SQL Server components that act as background services for relational database management systems. You can use them to schedule the execution of jobs, such as MS SQL database backup and replication. There are five types of agents: Snapshot, Log Reader, Distribution, Merge, and Queue Reader Agents.
The 4 types of SQL Server replication
There are four types of replication available to SQL Servers, each serving different purposes:
-
Snapshot replication
A point-in-time copy of the data is taken from the publisher (source) and applied to the subscribers (destination). Snapshots are suitable for small to medium-sized databases or where data changes are infrequent.
-
Transactional replication
Transactional replication is based on the concept of transactions. It involves capturing and replicating individual transactions from the publisher to the subscribers in near real-time. Ideal for scenarios that require high throughput, including improving scalability and availability, data warehousing and reporting, integrating data from multiple sites, integrating heterogeneous data, and offloading batch processing. Transaction replication is suitable for high-volume environments where data changes frequently.
-
Peer-to-peer replication
Peer-to-peer replication is a replication type where the publisher server replicates data to multiple subscriber servers at the same time. It is used for enhancing the availability and scalability of data by maintaining copies of data across different server instances, also known as nodes. One centralized data center manages the data on other data centers' data. Peer-to-peer replication is suitable for coordinating among multiple data center locations around the world.
-
Merge replication
Merge replication is the process of distributing data from Publisher to Subscribers, allowing the Publisher and Subscribers to make updates while connected or disconnected, and then merging the updates between sites when they are connected. The data is synchronized between servers continuously, at a scheduled time, or on demand. Changes made at separate locations can be merged, resolving conflicts as necessary. Merge replication is suitable for scenarios where updates can occur at multiple locations and need to be synchronized.
Setting up a SQL Server replication
Setting up a replication involves configuring publications, defining articles, creating subscriptions, and monitoring the replication process. It's important to choose the appropriate type of replication depending on factors such as the size of the database, the frequency of data changes, and the specific use case requirements.
Although replication is a powerful feature, it also introduces complexity. Proper planning and maintenance are essential for its successful implementation and operation.
-
Prepare the environment
- Make sure you have the necessary permissions set for replication
- Make sure that the necessary components are installed on all participating servers
-
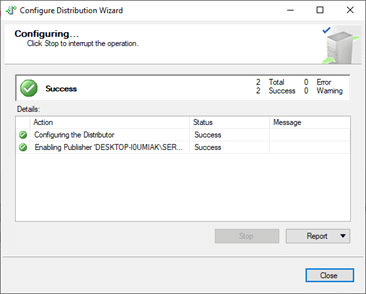
Create a distribution
- Define the distribution (name, etc.)
- Configure the replication distribution database
- Specify the Publishers to have access to the Distributor
- When you finish, you should see a success window:
-
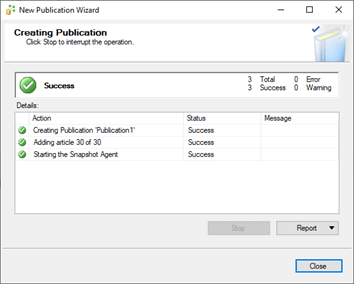
Create a publication
- Define the database articles to be replicated (tables, views, stored procedures)
- Configure publication properties, such as snapshot or transactional replication
- When you’ve succeeded, you see a success window:
-
Configure subscribers
- Define the subscribers (destination servers) that will receive the replicated data.
-
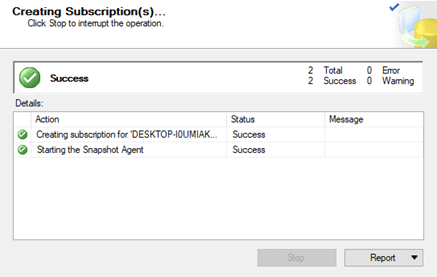
Initialize subscribers
- Initialize Subscribers through snapshot files or by using backup/restore methods.
- When you finish, you should see a success window:
-
Start replication
- Start the replication process to begin copying and synchronizing data
- Monitor the replication status and troubleshoot any issues
-
Monitor and maintain
- Regularly monitor the replication for any errors or latency
- Perform routine maintenance tasks such as cleaning up old data, optimizing indexes, etc.
-
Handle failures and conflicts
- Implement conflict resolution mechanisms, especially in merge replication scenarios
- Have a plan for handling replication failures and resuming replication
These steps provide a high-level overview, and the specific details may vary based on your SQL Server version and the exact requirements of your environment. See the official Microsoft documentation for your specific SQL Server version for detailed and up-to-date information on configuring replication.
Setting up a SQL Server replication in CData Sync
CData Sync greatly simplifies the process of replicating a SQL Server. Follow these steps:
-
Configure SQL Server as a replication destination
Since we're connecting to SQL Server instances as both the source and the destination, the instructions are the same for both. You'll configure a SQL Server connection twice, once for the source database and once for the target database. These correspond with the Distributor and Subscriber respectively (CData Sync acts as the go-between, eliminating the need for a Publisher).
From the Connections page, add and configure a SQL Server connection. The host of the SQL Server instance determines how you connect.
Connecting to Microsoft SQL Server
Connect to Microsoft SQL Server using the following properties:
- User: The username provided for authentication with SQL Server.
- Password: The password associated with the authenticating user.
- Database: The name of the SQL Server database.
Connecting to Azure SQL Server and Azure Data Warehouse
Set the following properties to authenticate to Azure SQL Server or Azure Data Warehouse:
- Server: The server running Azure. You can find this by logging into the Azure portal and navigating to "SQL databases" (or SQL data warehouse > Your database > Overview > Server name).
- User: The name of the user authenticating to Azure.
- Password: The password associated with the authenticating user.
- Database: The name of the database, as seen in the Azure portal on the SQL databases (or SQL warehouses
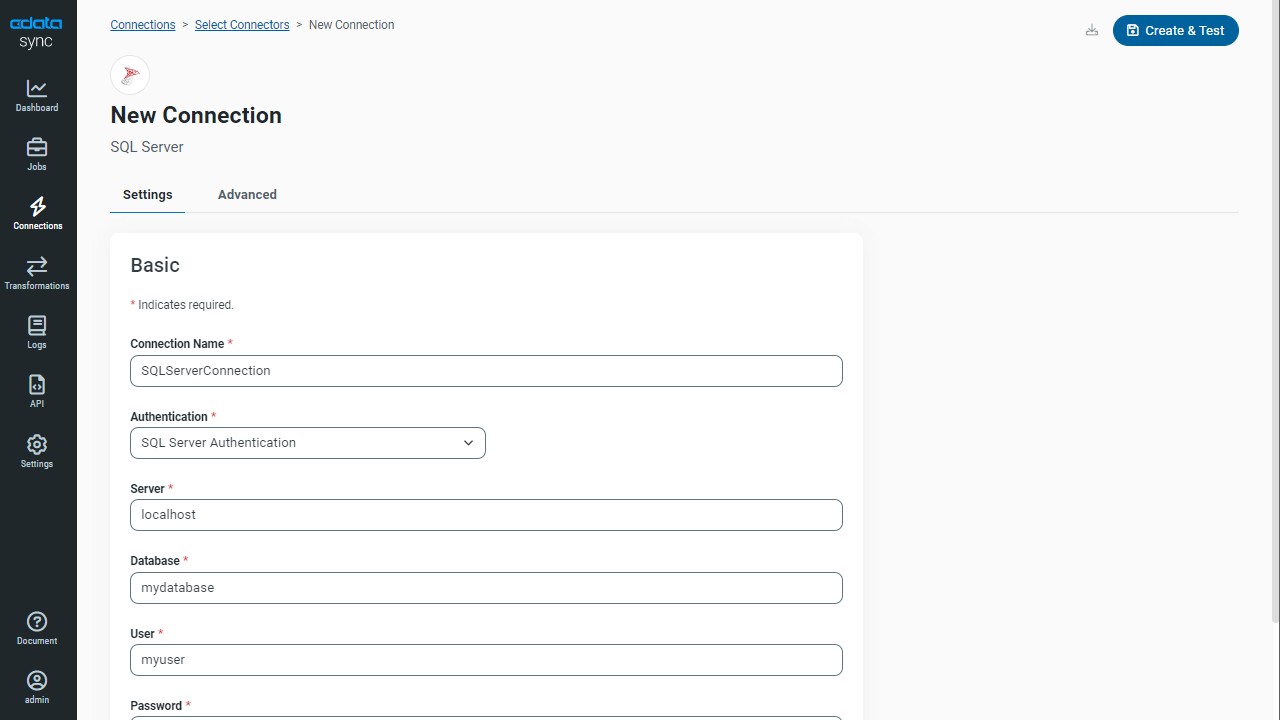
Once you configure the connection, click Create & Test to confirm the configuration.
-
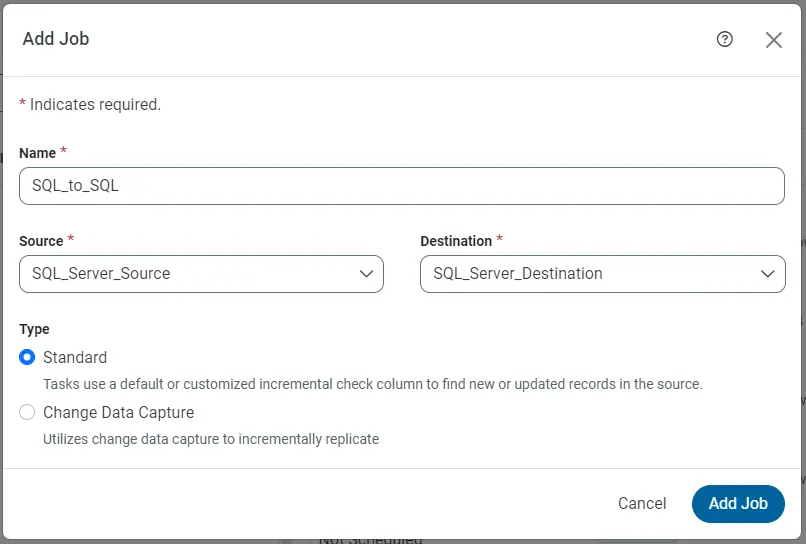
Configure replication queries
CData Sync enables you to control replication with an easy-to-use point-and-click interface and SQL queries. For each replication you want to configure, navigate to “Jobs” and click Add Job. Select the Source and Destination for your replication.
Replicate entire tables
To replicate an entire table, click Add Tables in the “Tables” section, choose the table(s) you want to replicate, and click Add Selected Tables.
Customize your replication
You can use the “Columns” and “Query” tabs to customize your replication. The Columns tab allows you to specify which columns to replicate, ren columns at the destination, and even perform operations on the source data before replicating. The Query tab allows you to add filters, grouping, and more.
-
Schedule your replication
In the Schedule section, you can schedule a job to run automatically, configuring the job to run after specified intervals ranging from once every 10 minutes to once per month. After you have configured the replication job, click Save. You can configure any number of jobs to manage the replication of your SQL Server data.

Why CData?
CData Sync does what can't be done in SQL Server Management Studio. With SSMS, you can set up distribution, publication, and subscription to and from instances of SQL Servers. But with Sync, you have access to the full range of hundreds of sources and dozens of destinations, including SQL Server. PostgreSQL, MySQL, Oracle, SAP HANA, and many others are supported.
CData Sync integrates live SQL Server data into mirrored databases, always-on cloud databases, and other types of databases in minutes. Automated, continuous replication is supported—create a job once and schedule it for automatic execution whenever you want.
Along with continuous replication, you can also perform incremental replication through CDC or row data, replicating the data using the last modified column, the integer count column, or version column.
CData supports the replication of any combination of on-prem and cloud servers, not just SQL Server. Mix and match to your heart’s content. And unlike SSMS, supports in-flight ETL (extract-transform-load) and in-place ELT (extract-load-transform) transformations
All these features are seamless and can be implemented in a matter of minutes.
Check out CData Sync
t a free 30-day trial of CData Sync and uplevel your data integration strategy.




