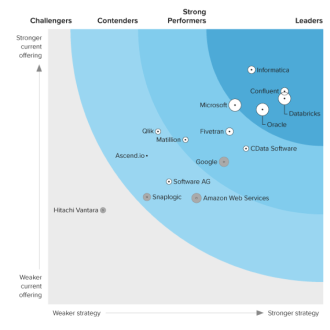
Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →


Use CData Sync to Replicate Data to Amazon S3
Amazon S3 is Internet storage designed to enable and empower web-scale computing. With S3, you can store and retrieve any amount of data, from anywhere, at any time. Developers gain access to scalable, reliable, fast, cost-effective storage exactly like the infrastructure Amazon uses.
AWS Lake Formation is Amazon's service to ease the setup and security of your data lake. You simply define where in S3 your data is and your access and security requirements. Lake Formation uses machine learning to cleanse and categorize data, enabling your users to consume the data in the analytics and machine learning services of their choice. For more information, you can read up on Amazon S3 and AWS Lake Formation from the AWS site.
Configuring Amazon S3
To replicate enterprise data to Amazon S3 using CData Sync, you will need a bucket in Amazon S3. With the bucket in place, CData Sync manages the rest of the replication, from creating new sub-buckets for each replicated entity to updating existing buckets with new data entities.
Creating an Amazon S3 Bucket
If you do not already have a bucket or you want to create a new one, log into the AWS Management Console, (search for) and click "S3," then click "Create bucket."
 In the Create bucket wizard, name your bucket, select a Region, and click "Create" (optionally configure options and set specific permissions).
In the Create bucket wizard, name your bucket, select a Region, and click "Create" (optionally configure options and set specific permissions).

With the bucket configured, you are ready to connect to Amazon S3 as a replication store from CData Sync.
Connecting to Amazon S3 from CData Sync
CData Sync connects directly to an Amazon S3 bucket as a data replication destination. Coupled with the 100+ supported data sources CData Sync supports, you can rapidly configure Amazon S3 as your single data store for all of your enterprise data, from marketing automation and CRM to ERP, accounting, social media, collaboration platforms and more.
To authorize S3 as a destination, use the credentials for an AWS administrator account or for an IAM user with custom permissions. Set Access Key to the access key ID. Set Secret Key to the secret access key.
Note: Though you can connect as the AWS account administrator, it is recommended to use IAM user credentials to access AWS services.
Obtaining an Amazon Access Key and Secret Key
To obtain the credentials for an IAM user, follow the steps below:
- Sign into the IAM console.
- In the navigation pane, select Users.
- To create or manage the access keys for a user, select the user and then select the Security Credentials tab.
To obtain the credentials for your AWS root account, follow the steps below:
- Sign into the AWS Management console with the credentials for your root account.
- Select your account name or number and select My Security Credentials in the menu that is displayed.
- Click Continue to Security Credentials and expand the Access Keys section to manage or create root account access keys.
Creating the Amazon S3 Connection
To connect to Amazon S3, navigate to the Connections page, click the Destinations tab, and select Amazon S3.

Name your connection and set the Access Key, Secret Key, Region and Bucket properties.

Back on the Settings tab, click Test Connection to ensure that you have configured the connection properly and click Save Changes to finish the Connection configuration.
Replicating Data to Amazon S3
With Amazon S3 configured and CData Sync connected, you are ready to replicate your enterprise data to Amazon S3. For the data sources you wish to replicate, configure a source connection. While several data sources are embedded in CData Sync out of the box, you can easily download new Data Source Connections (click the link in the CData Sync app or navigate directly to the Data Source Connections download page).
From the Jobs tab, create and schedule your replication jobs. You can see job creation in our CData Sync 2019 Overview (video jumps to job creation):
CData Sync creates a sub-bucket for each replicated entity. Within the sub-buckets, you will find a .CSV file for each replication transaction. Your enterprise data is stored in an easy-use .CSV format, and since a new file is created for each replication, CData Sync automatically maintains a history of your data.
Beyond Amazon S3
Once you replicate your data, you can use the suite of Amazon services to query and visualize your data. CData Sync is capable of automatically generating Hive DDL statements that can be used in Amazon Athena to create resources based on the data replicated to Amazon S3. With those resources configured, you can work with your replicated data in Amazon QuickSight, Amazon's cloud-based business intelligence service.
Configuring Amazon Athena
Amazon Athena allows you to query your S3 data using SQL. To configure Amazon Athena to work with the replicated data found in Amazon S3, navigate to the Amazon Athena console and create a new database (or select an existing one) using a statement similar to `CREATE DATABASE IF NOT EXISTS

With the database selected, you can run the Hive DDL statements to create external tables that can be used to query your replicated data from any tool, application, or platform that support Amazon Athena connectivity.

Visualizing Data in Amazon QuickSight
Amazon QuickSight natively supports connecting to and visualizing Amazon Athena databases. To begin visualizing your replicated data, navigate to the Amazon QuickSight console, click "New analysis," and click "New data set." In the data set menu, select Athena, name the data source, and click "Create data source."

Select a database and table to visualize (or create a custom SQL query), choose whether to query live or import to SPICE, and select your dimensions and measures to visualize.

Free Trial & More Information
Now that you have seen how to replicate data to Amazon S3 and work with that data in other Amazon services, visit our CData Sync page to read more information about CData Sync and download a free trial. Start consolidating your enterprise data to a data lake today! As always, our world-class Support Team is ready to answer any questions you may have.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers