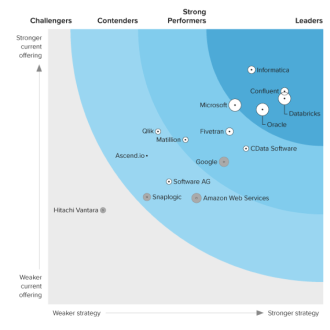
Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →




Build and deploy ETL/ELT data pipelines in minutes
Use one tool to integrate and replicate data from on-prem to on-prem, cloud to cloud, on-prem to cloud, and cloud to on-prem.
Connect to any cloud or on-prem source:

APIs

Applications

Databases

Files

NoSQL

Data Warehouses

Data Lakes
Target any cloud or on-prem destination:
Databases
Data Warehouses
Data Lakes
Connect to any cloud or on-prem source
Target any cloud or on-prem destination
Why CData Sync is different
Connect to sources that matter
Connect to any relational/NoSQL database or application, including Dynamics 365, NetSuite, Salesforce, ServiceNOW, SharePoint, Workday, and more.
Get your data to the destinations you want
Support for the destination of your choice, including Snowflake, S3, Redshift, Databricks, MongoDB, SQL Server, Azure Data Lake, and more; plus Salesforce through reverse ETL.
Fast, efficient Change Data Capture
Save time and overhead by replicating only changed data from transactional databases (Oracle, SQL Server, MySQL, Postgres) into data warehouses with CDC.
Don’t pay for every row
Predictable connector-based pricing helps you manage the cost of data replication and optimize spend when compared to other approaches.
Access the data you need, when you need it
Connect your data how you want with flexible hosting to fit your organization. Deploy Sync on-premises or in AWS/Azure for flexibility, or maximize convenience with CData-hosted Sync Cloud.
Replicate from any source to any destination
CData Sync supports unlimited data movement to whichever database or data warehouse you use: Amazon Redshift, Amazon S3, Databricks, Google Big Query, IBM DB2, Microsoft SQL Server, MySQL, Oracle, PostgreSQL, Snowflake, Teradata, Vertica, and more. Connect to hundreds of data sources and targets with one no-code data integration tool.
Supported sources and destinations

Transform data the way you want
Support for any data integration pattern. Execute ETL and ELT processes flexibly using dbt Core, dbt Cloud, or custom SQL transformations. Schedule and monitor data pipelines and add transformations, functions, and filtering before, during, or after data is moved to its destination.
Discover how it worksMove data without boundaries
Unlike cloud-only solutions, Sync easily integrates data between on-premises, public cloud (AWS, Azure, GCP), and private cloud environments. Sync can even be deployed in customer-owned environments to support specific enterprise architectures and data residency requirements for privileged data.
Read more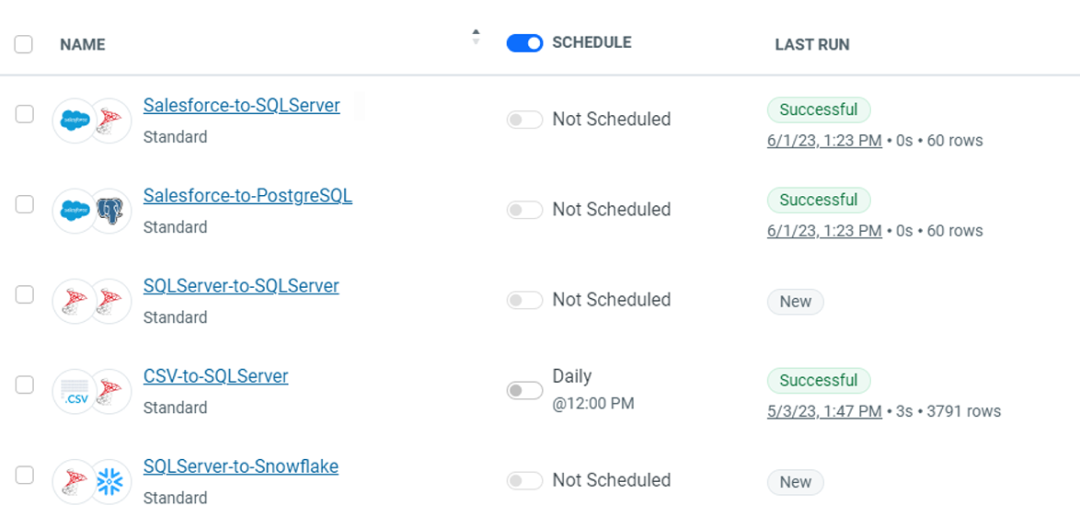

Enrich your business applications
Support for enterprise-grade reverse ETL lets organizations enrich their business applications like Salesforce with data from warehouses like Microsoft SQL Server and Snowflake. Teams can leverage this more comprehensive data set for decision-making and strategy development.
See it in actionCData Sync powers data replication initiatives for top organizations
Holiday Inn Club Vacations Rests Easy with Error-Free Salesforce Data Movement
“I can sleep again knowing that the replication is working. If I stopped CData Sync today, I'd get flooded with calls from my teams in the next 20 minutes. The near-real-time data we get with Sync has transformed how we work in a big way.”
— Irving Toledo
Sr. Software Architect, Holiday Inn Club
Read case study

MobilityWorks Leverages CData to Support Proactive Business-Wide Reporting
“CData Sync has become a system that I don't have to think about. From an automation standpoint, it's the ultimate panacea. I don't have to worry about it. It’s my dream to have a system that works in the background — and Sync works flawlessly.”
— John Hill
MobilityWorks Marketing Automation Manager
Read case study
Monrovia Nursery Co. Plants a Strong Foundation for Organizational Data
“We began looking for a tool that would do all that forklifting for us and put [the data] into one repository where we would have everything ready so we can build our reports. That’s where CData stepped in for us.”
— Todd Noe
Monrovia Nursery Co. IT Manager
Read case study

Support all your data replication use cases
- Consolidate customer data for better insights and reporting
Replicate data from your Salesforce ecosystem to Microsoft SQL Server, PostgreSQL, or Snowflake for improved analytics, historical reporting, and customer experiences. - Migrate your databases to the cloud
Replicate data from Microsoft SQL Server, MySQL, and PostgreSQL to a data warehouse such as Snowflake, Google Big Query, and Azure SQL database. - Move CSV files to databases with ease
Easily import data in files by moving CSV and other files to Microsoft SQL Server, Snowflake, and more. CData Sync maps CSV fields into respective columns for quicker integrations.

3 Easy steps to move and replicate data
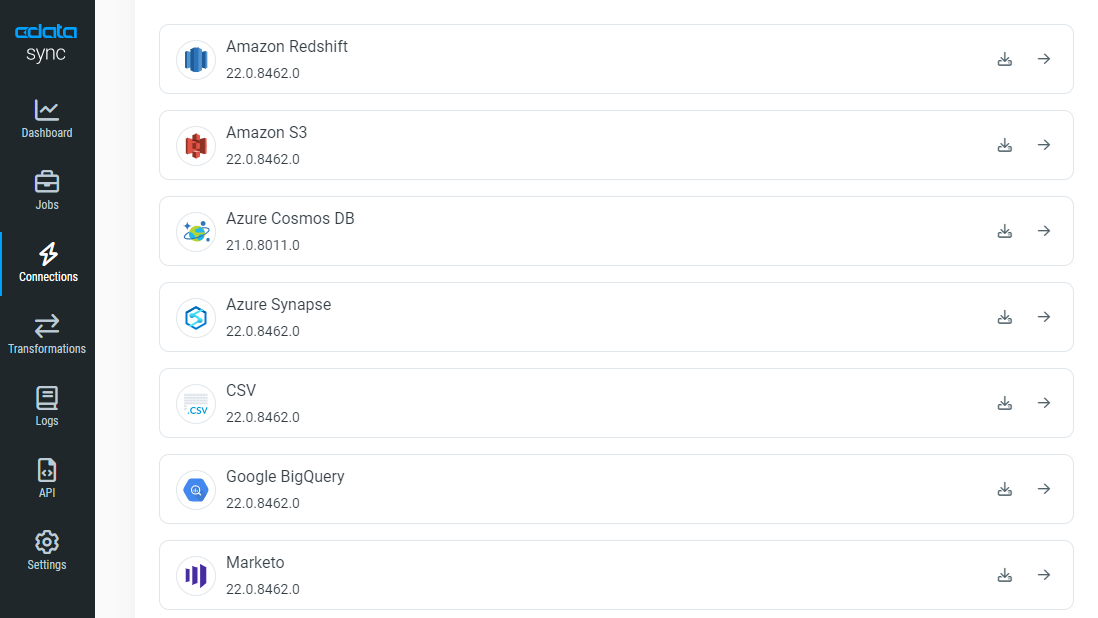
1. Configure your sources
CData Sync makes it simple to get to the data you need. To get started, log into Sync and select from any of the 250+ available sources including popular on-premises and SaaS applications across your data ecosystem. You can easily configure any number of sources depending on your needs.
CData automatically generates dynamic schemas and table views for all sources, even when they don't exist natively in the source system. This ensures a simple consistent process regardless of what source you choose.
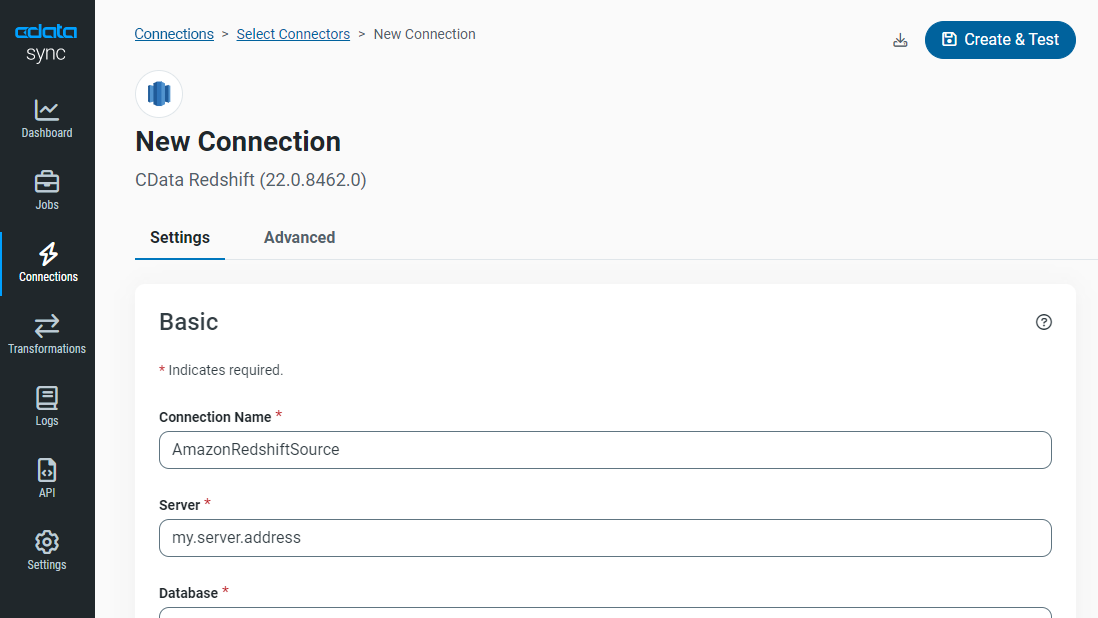
2. Configure Your Destination
Choosing a destination is just as easy. Simply select from the catalog of cloud or on-premises destinations — including the most popular relational or NoSQL databases and data warehouses. Fill out the appropriate user credentials, test the connection, and you're all set.
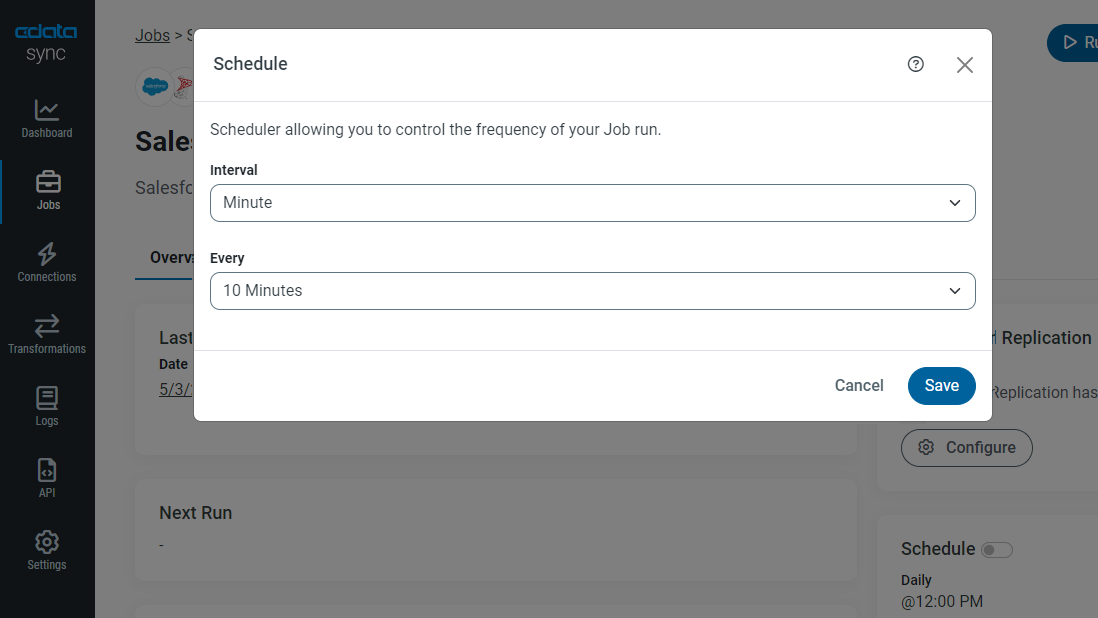
3. Create your data replication job
After configuring data connections, you can schedule a job to automatically execute data replication at any desired interval or in real-time using Change Data Capture capabilities. You can even apply optional data transformations in-flight or after the job has been run.
Technical features
Intelligent Change Data Capture and incremental load
Leverage incremental replication for a wide variety of data sources to synchronize only new or altered data after the initial replication. Whether you're dealing with large data sets, slow APIs, or daily quotas, we've got you covered. CData Sync features an incremental check column, which pinpoints and updates modified records, and Change Data Capture (CDC), which scans source log files to identify and replicate data changes. These approaches dramatically reduce bandwidth and latency and ensure that your data warehouse is always up-to-date and ready for analysis. Experience unmatched flexibility and efficiency with our advanced data synchronization.
Expansive connector library
Unlock boundless integration possibilities with CData Sync’s comprehensive connector library. Equipped with hundreds of pre-built connectors, our platform allows you to bring together data from a multitude of sources including databases, SaaS applications, APIs, and more. With a broad spectrum of connectivity at your disposal, CData Sync ensures that your data integration needs are always met, no matter the data source or its format. Plug-and-play into this library and enhance your data operations with flexible and diverse connectivity.
Schema management
Keep pace with your evolving data using the dynamic Change Schema feature, specifically designed to combat schema drift. CData Sync meticulously compares the source and destination schema in every run to detect discrepancies. Be it a new column in the source table or an increase in data type size, CData Sync automatically alters the destination to ensure accurate data representation. CData Sync never deletes columns from the destination table or reduces the size of a destination column – even when changes occur in the source. Experience worry-free data management with a tool that adapts to your data, not the other way around.
Advanced data transformations
Elevate your data management with robust, in-flight ETL and Post-Job ELT Transformations, including a powerful custom SQL query builder and integration with dbt™. dbt prioritizes SQL as its primary language, enabling teams to implement analytics code while adhering to essential engineering principles like modularity, portability, CI/CD, and documentation. Transform your data before or after replication using SQL scripts executed in your destination transformations database. Create and execute SQL SELECT statements, manage projects, and honor dependencies with dbt integration. Rename, add, remove, or concatenate columns, apply filters, calculations, or partition data while in-flight. Also, take advantage of scheduling, notifications, and other management features to ensure your data is primed for analytics and reporting.
High-performance data handling
Supercharge your data processing capabilities with advanced performance features. CData Sync supports Clustering, which enables multiple installations to work in unison and evenly distribute tasks for improved scalability and increased availability. With Parallel Processing, each job can utilize multiple worker threads, accelerating data transfer and boosting efficiency. By allowing several tasks to run simultaneously, CData Sync ensures that more data is moved in less time. Embrace a new standard of performance with a solution designed for the highest levels of productivity and reliability.
Streamlined data integration
Streamline your data processes with CData Sync's automated data integration. This advanced functionality allows you to combine and synchronize data from multiple sources across various formats and structures, into your centralized data warehouse. Forget manual intervention — CData Sync performs near real-time updates, ensuring consistent data availability for your analytics and operations needs.
Empowered business processes with events
Powerful Pre- and Post-Job Events features allow you to incorporate external information into your data flow tasks and automate key actions with ease. Utilizing built-in APIScript language, you can inject query parameters, trigger external processes, and automate common tasks, such as running batch files or sending emails. The ability to create environment variables gives you full control over your job execution, enabling dynamic and flexible data pipelines.
Data lineage and history with logging
Gain full visibility and accountability with Logging and History Tracking. Easily enable logging at different verbosity levels to capture detailed information about job execution, connectivity errors, and replication processes. The job-history table maintains a record of every executed job, allowing you to review results and track changes over time. Download specific log files for source, destination, and replicate engine communications to investigate any issues. Additionally, archive logs locally or in an Amazon S3 bucket for long-term storage and auditing purposes. Ensure thorough auditing and data lineage tracking with Sync's robust logging and history capabilities.
Business views of data
Access curated data sets to select business-friendly dimensions and metrics in supported data sources. These views make it easy to replicate data from Google Analytics 4, Google Ads, Facebook Ads, and more without knowledge of how the underlying data is organized.
Deployment flexibility
Choose the deployment option that best fits your organization's needs with CData Sync. Continuously integrate with leading cloud platforms like AWS, Azure, and Google Cloud through marketplace offerings and enjoy the perks of enhanced cloud security. Or deploy CData Sync on-premises so your data never escapes the protection of your system and security protocols, alleviating the need to expose ports to the internet, open firewalls, or create VPN connections. CData Sync’s ability to run anywhere reduces latency by running closer to sources or destinations, improves performance, and satisfies potential data residency requirements. Deploy where you need it most, maintaining data governance and confidentiality every step of the way.
Job scheduling and automation
Streamline and automate your data integration processes with our robust Scheduling feature. Set up automated job runs at desired intervals, from hourly updates to custom schedules, using Cron expressions. Ensure flawless synchronization without manual intervention. Receive comprehensive email notifications that keep you informed about query status and success. Customize your notification preferences to receive alerts only on errors or for every job run, and integrate your alerts with Microsoft Teams and Slack. Stay connected and informed about your data integration activities and ensure a smooth, efficient workflow to save time, improve efficiency, and ensure accurate and timely data synchronization.
Reverse ETL
Reverse ETL, or the ability to push data from a data warehouse or analytics platform into an operational system, is a critical capability for cloud and hybrid organizations. CData Sync enables users to push data directly into Salesforce. By enriching Salesforce with database insights, teams can leverage a more comprehensive data set for decision-making and strategy development. This feature not only enhances the functionality of Salesforce but also bridges the gap between database intelligence and customer relationship management.
News & insights
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers