
Microsoft Azure Data Factory (ADF) is a cloud-based service that simplifies data integration and orchestration by moving information from diverse sources – on-premises databases, cloud platforms, and SaaS applications – and transforming it into actionable insights. But how does it work in real-life scenarios?
Think of a company struggling to connect disparate marketing and sales data for comprehensive customer analysis. ADF can bridge the gap, effortlessly pulling data from both systems and enriching it with additional sources like web analytics, creating a unified customer view. CData Connect AI provides powerful cloud-based data virtualization and further expands ADF's reach, offering connectivity to any data source, eliminating the need for custom integrations, and reducing implementation times.
The result? Streamlined data pipelines, accelerated analytics, and ultimately, data-driven decisions that propel businesses forward.
This blog will help you explore the core of Azure Data Factory, uncover its functionalities, and understand how it transforms data workflows. Discover how this tool seamlessly integrates into your business, and how it pairs with CData Connect AI, offering a robust code-free solution to address significant data management challenges.
What is Azure Data Factory?
Azure Data Factory is a cloud-based data integration service that lets you create data-driven workflows in the cloud for orchestrating and automating data movement and data transformation. The tool does not store any data itself, but facilitates the creation of data-driven workflows to orchestrate data movement between supported data stores and then process the data using compute services in other regions or an on-premise environment. The results can then be published to an on-premises or cloud data store for business intelligence (BI) applications to consume.
Data integration and orchestration using Azure Data Factory
-
Data migration
It can be used to migrate data from on-premises data stores to the cloud, or between different cloud data stores.
-
Data integration
It can be used to integrate data from multiple sources, such as relational databases, flat files, and APIs, into a single data store.
-
Data transformation
It can be used to transform data, such as cleansing, filtering, and aggregating data.
-
Data orchestration
It can be used to orchestrate the execution of data pipelines, which are a series of tasks that are performed on data.
Essential components that contribute to its architecture
-
Datasets
The datasets represent the named view of the data within the data store, which can be a table or a file. They define the structure of the data to be processed in a data pipeline.
-
Pipelines
The pipelines are a logical grouping of activities that together perform a task. They represent the workflow in Azure Data Factory, orchestrating the execution of various activities.
-
Activities
Activities are the processing steps in a pipeline. They define the actions to be performed on the data, such as data movement, data transformation, or data analysis.
-
Linked services
The linked services define the connection information needed for the Data Factory to connect to external resources. They establish a link between the data factory and the external data stores or compute services.
-
Data flows
The data flows provide a graphical interface for designing data transformations, hence allowing users to visually design, debug, and execute data transformations in a pipeline.
-
Integration runtimes
The integration runtimes define the compute infrastructure used by Azure Data Factory for data movement and data transformation. They manage the resources and environment in which the activities of a pipeline are executed.
How Azure Data Factory works
Unlocking the potential of Azure Data Factory involves mastering its intricate workings, and the steps discussed below set the stage for understanding the platform's fundamental operations.
-
Connect and collect
Making the most of ADF starts by configuring your connection to various data sources like SaaS services, file shares, FTP repositories, and web services. Once connected, ADF can extract data from these sources as the first part of a data pipeline.
-
Transform and enrich
Optimizing your data workflow in ADF involves centralizing the extracted data in the cloud through effortless connections to various sources like SaaS services, file shares, FTP repositories, and web services. Once your data is securely stored, the next step involves leveraging compute services such as HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Machine Learning to transform it. This transformative phase includes activities like filtering, cleansing, joining data from different sources, and applying essential business logic, ensuring your centralized data store is not just a repository but a dynamic hub of actionable insights.
-
Continuous integration/continuous delivery (CI/CD) and publish
Effectively utilizing ADF involves a smooth orchestration of data pipelines through various environments such as development, testing, and production, facilitated by CI/CD pipelines. After traversing these stages, ADF not only publishes the transformed data to designated target data stores like Azure Data Lake Storage, Azure SQL Database, or Azure Synapse Analytics, but also retains it in your cloud storage sources. This strategic storage ensures easy accessibility for consumption by BI and analytics tools, as well as other applications, completing the data lifecycle managed by Azure Data Factory.
-
Monitor
Optimizing your experience with ADF involves monitoring your data pipelines for potential errors and performance issues. Make sure to diligently keep an eye on the health of your pipelines, ensuring continuous operation. To enhance this proactive approach, the system sets up alerts and notifications that promptly address any emerging issues.
10 use cases of Azure Data Factory
Azure Data Factory is as a transformative solution with a myriad of use cases, revolutionizing how organizations handle their data workflows.
Emphasizing user-friendly interfaces and scalable cloud solutions, Azure Data Factory takes center stage in molding the data landscape for organizations of all sizes. Now, let's explore some of its most popular use cases:
-
Data migrations
Optimizing data migration with ADF involves consistently transferring data between on-premises and cloud environments. It helps facilitates the migration of data from legacy systems to modern data warehouses. Leveraging its capabilities, ADF streamlines the data migration process, ensuring a smooth transition across different environments and enabling organizations to modernize their data infrastructure effortlessly.
-
Getting data to an Azure Data Lake
Another key aspect of ADF is its capability to ingest and store substantial data volumes in Azure Data Lake for subsequent analytics and processing, ensuring a comprehensive approach to managing and utilizing data resources.
-
Data integration processes
Optimizing data integration processes in Azure Data Factory involves effortlessly integrating data from diverse sources, such as SQL Server, Oracle, and Azure Blob Storage, to derive unified insights. This configuration allows for streamlined ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes within ADF, enhancing both data quality and accessibility.
-
Integrating data from different ERPs into Azure Synapse
Integrating data from different ERP systems into Azure Synapse Analytics involves consolidating data from disparate ERP systems and harmonizing information from different sources into a centralized data warehouse. As the second part of the data pipeline, ADF streamlines the process of consolidating and harmonizing data, providing a unified approach to analytics and data management.
-
Integration with Azure Databricks
By combining its power with Azure Databricks, ADF extends its capabilities to facilitate comprehensive data engineering workflows. This integration empowers users to harness the synergy of both platforms, unlocking advanced analytics and machine learning insights within a unified data engineering environment.
-
GitHub integration
Maximizing the potential of GitHub integration begins by actively participating in data engineering projects through collaborative efforts within GitHub repositories. ADF facilitates this collaboration by connecting to GitHub repositories, allowing for streamlined version control and collaborative development. This integration empowers teams to work collaboratively on data engineering initiatives, enhancing efficiency and ensuring a smooth development experience within the GitHub ecosystem.
-
Cloud computing and big data
Leveraging the prowess of cloud computing, ADF offers scalability for significant big data processing. In big data scenarios, ADF extends its capabilities by implementing robust solutions, including Hadoop processing and analytics. As a result, users can harness the potential of cloud computing to process large datasets.
-
JSON and PowerShell integration
Efficient utilization of JSON and PowerShell in ADF revolves around two key functionalities. Firstly, ADF incorporates JSON configurations to define data pipelines flexibly and in a structured manner. This means users can tailor their pipelines to specific needs, ensuring a seamless and dynamic data flow. Secondly, ADF leverages the power of PowerShell scripting for advanced automation and comprehensive management of data pipelines.
-
Copy activity and copy data
Unlocking the full potential of ADF involves leveraging the Copy activity feature to streamline data movement across various data stores. With the Copy activity, users can seamlessly transfer data between different storage solutions, including support for Azure Blob Storage.
-
Azure DevOps integration
Maximizing the potential of ADF involves integrating it with Azure DevOps for a cohesive development and deployment experience. By configuring this integration, ADF becomes intertwined with Azure DevOps. Leveraging Azure DevOps pipelines, users can effortlessly automate CI/CD processes specifically tailored for their data pipelines.
CData Connect AI: Expanding the reach of Azure Data Factory
CData Connect AI serves as a transformative companion to Azure Data Factory, extending its capabilities and broadening its scope. This dynamic integration enables Azure Data Factory users to seamlessly connect with a diverse array of data sources, eliminating the confines of traditional boundaries. Discover how Connect AI empowers organizations to enhance their data integration workflows within the expansive Azure ecosystem, providing a catalyst for more comprehensive and efficient data management.
In this section, we outline the process of accessing data in Azure Data Factory through Connect AI. We use Salesforce as a data source, but these principles apply to any supported source. For detailed instructions, check out our Knowledge Base article.
-
Connect to a data source in CData Connect AI
Log into CData Connect AI, and add a new data source connection, creating a virtual SQL Server interface for the data source (Salesforce is pictured).
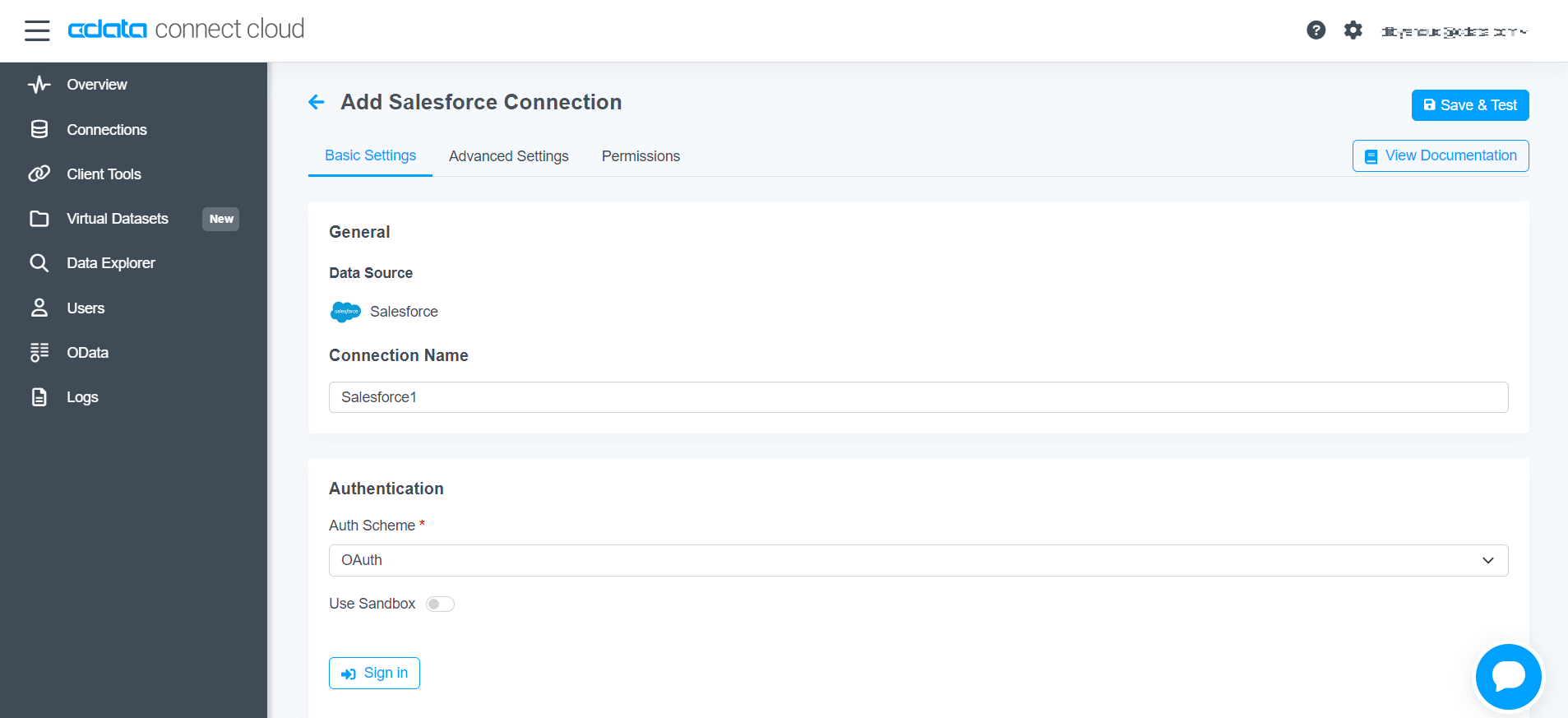
-
Collect connection information
Click on Azure Data Factory in Client Tools on the left panel and copy the connection details. You will need to create a PAT (Personal Access Token) if you haven't already done so.

-
Create a dataset in Azure Data Factory
Use the SQL Server connection to create a new linked service to Connect AI. Fill in the connection properties based on the connection information collected from Connect AI to establish the connection.
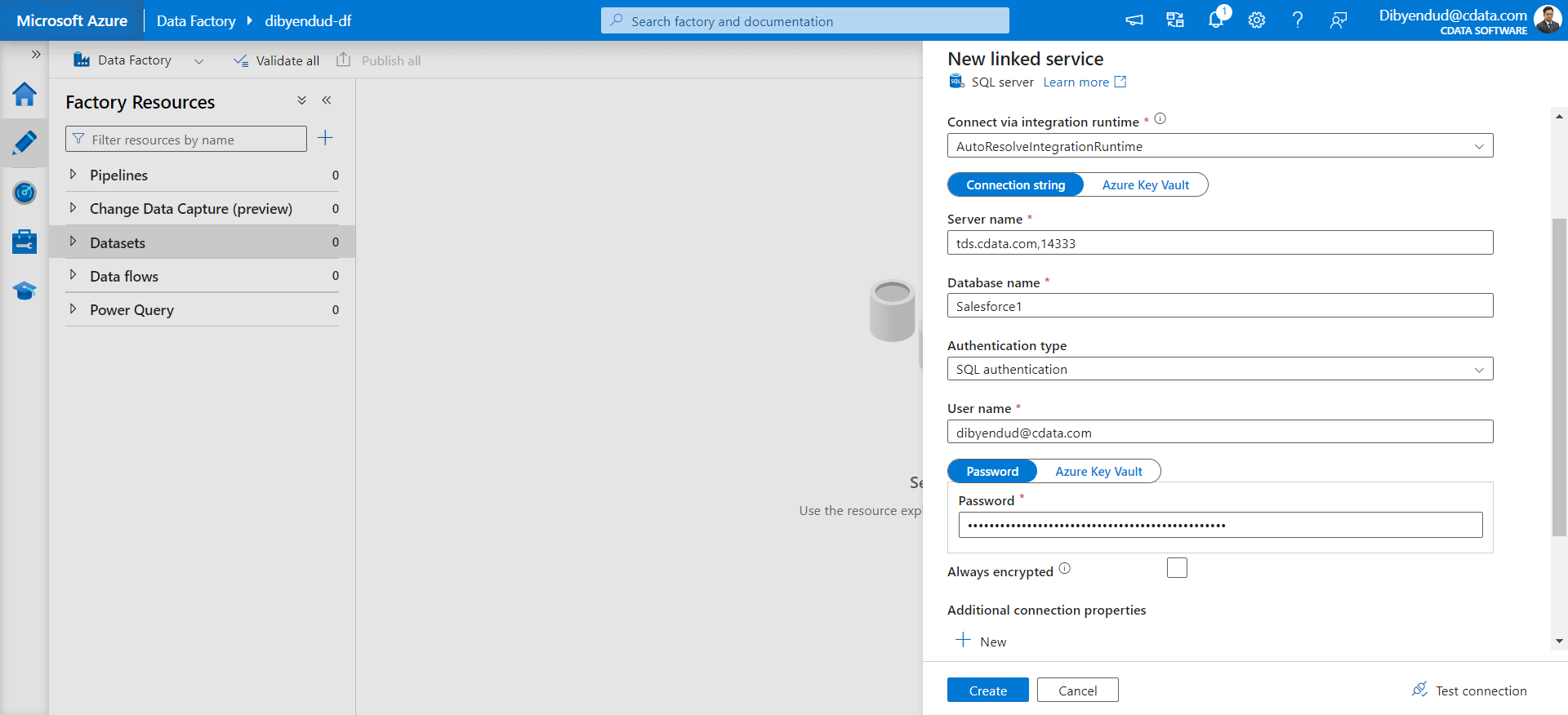
-
Select your tables and views
Once you establish the linked service, select the tables and views to work with.

The CData difference
The integration of CData Connect AI and Azure Data Factory opens a realm of possibilities for users seeking seamless connectivity and efficient data integration. With hundreds supported data sources, CData Connect AI acts as a versatile bridge, enabling users to effortlessly integrate diverse data into Azure Data Factory, empowering them to preview and leverage data from various sources, thus enhancing the capabilities of Azure Data Factory.
Stop struggling with disparate data sources and limited integrations. Let CData Connect AI and Azure Data Factory orchestrate your cloud data, transforming your data landscape into a vibrant source of actionable insights and competitive advantage. To get live and on-demand data access to hundreds of SaaS, Big Data, and NoSQL sources in CData Connect AI, sign up for a 30-day free trial.
As always, our support team is ready to answer any questions. Have you joined the CData Community? Ask questions, get answers, and share your knowledge in CData connectivity tools. Join us!
Try CData today
Ready to uplevel your data integration strategy? Try CData Connect AI free for 30 days.




